Go sync.RWMutex(读写锁)的实现原理?
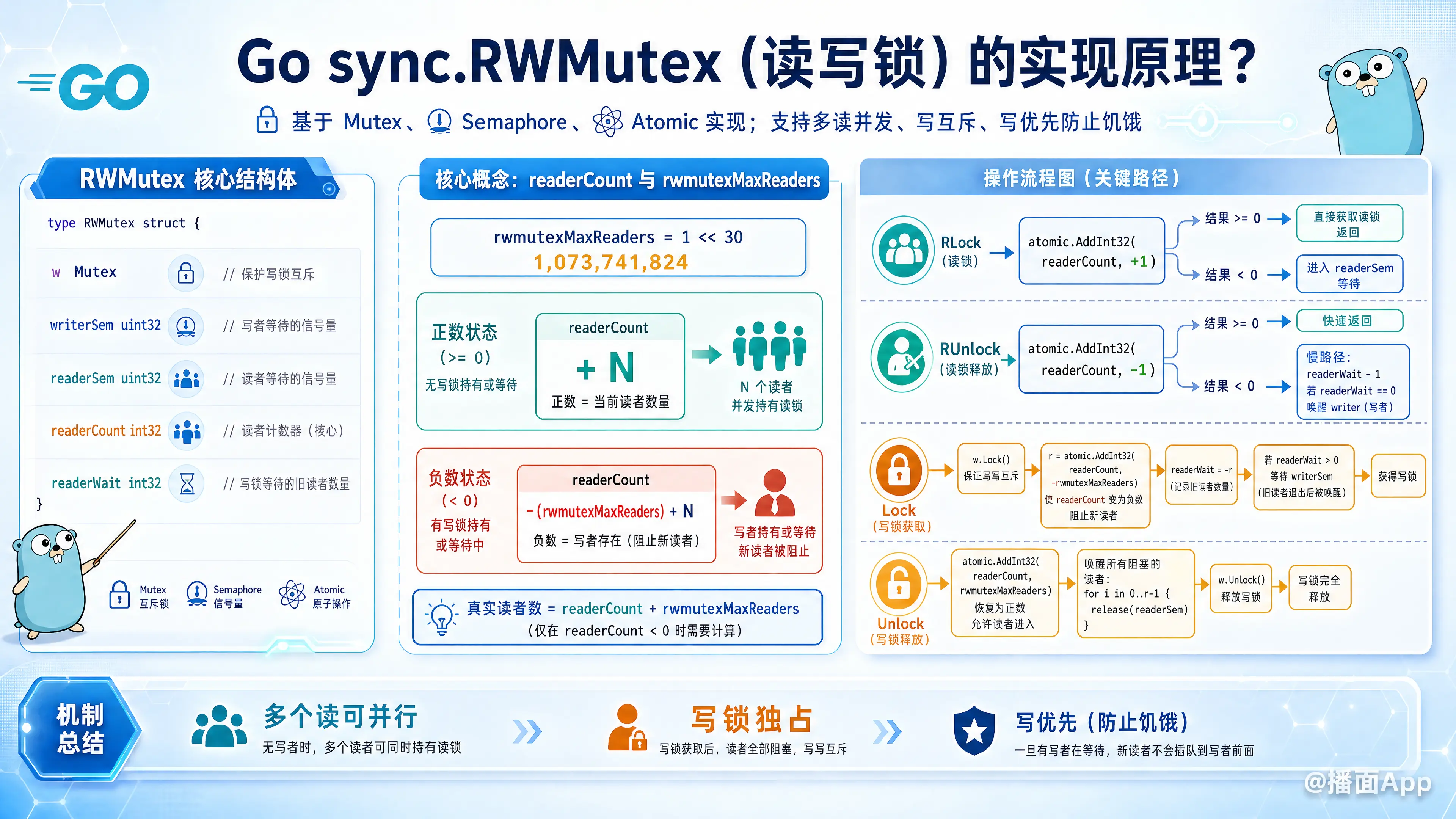
Go 语言的 sync.RWMutex(读写锁)是基于 互斥锁(sync.Mutex)、信号量(runtime.Semacquire/Semrelease) 和 原子操作(atomic) 实现的。
它的核心设计目标是:写锁优先(防止写饥饿),允许多个读锁并行,但写锁互斥。
以下是 sync.RWMutex 实现原理的深度解析:
1. 核心结构体
首先看源码中的结构定义(src/sync/rwmutex.go):
type RWMutex struct {
w Mutex // 用于控制多个写锁之间的互斥
writerSem uint32 // 写阻塞等待的信号量
readerSem uint32 // 读阻塞等待的信号量
readerCount int32 // 记录当前读者的数量(关键字段)
readerWait int32 // 记录写锁申请时,需要等待结束的读者数量
}w: 一个标准的互斥锁,用来保证同一时间只有一个写操作在进行(写-写互斥)。readerCount: 这是一个复用的字段。- 正常情况下,它等于当前持有读锁的 goroutine 数量。
- 当有写锁介入时,它会被减去一个巨大的常数
rwmutexMaxReaders(1 << 30),变成负数。通过判断它是否为负数,来确定当前是否有写锁(或写锁等待中)。
readerWait: 当写锁请求到来时,如果当前已经有读者,写锁需要等待这些旧的读者离开。这个字段就是记录还需要等待多少个旧读者。
2. 核心常量:rwmutexMaxReaders
const rwmutexMaxReaders = 1 << 30这是一个非常大的数(约 10 亿)。
Go 利用这个技巧将 readerCount 分为两个状态:
- 正数:表示当前只有读锁,数值代表读者数量。
- 负数:表示当前有写锁(或正在等待写锁),
readerCount + rwmutexMaxReaders才是真实的读者数量。
3. 实现流程详解
3.1 获取读锁 (RLock)
逻辑:原子增加读者计数,如果计数变负,说明有写锁,则阻塞等待。
func (rw *RWMutex) RLock() {
// 1. 原子操作 readerCount + 1
if atomic.AddInt32(&rw.readerCount, 1) < 0 {
// 2. 如果结果 < 0,说明 writer 正在持有锁或正在等待
// 当前 goroutine 进入休眠,等待 readerSem 信号量唤醒
runtime_SemacquireMutex(&rw.readerSem, false, 0)
}
// 3. 如果结果 >= 0,获取读锁成功
}- 关键点:只要
readerCount是正数,读锁就是无锁的原子操作,性能极高。
3.2 释放读锁 (RUnlock)
逻辑:原子减少读者计数,如果计数变负,说明有写锁在等,且自己可能是最后一个读者,需要尝试唤醒写锁。
func (rw *RWMutex) RUnlock() {
// 1. 原子操作 readerCount - 1
if r := atomic.AddInt32(&rw.readerCount, -1); r < 0 {
// 2. 结果 < 0,说明有写锁在排队(r 是负数)
rw.rUnlockSlow(r)
}
}
func (rw *RWMutex) rUnlockSlow(r int32) {
// 3. 减少 readerWait(写锁等待的读者数)
if atomic.AddInt32(&rw.readerWait, -1) == 0 {
// 4. 如果 readerWait 归零,说明我是最后一个阻挡写锁的读者
// 唤醒写锁
runtime_Semrelease(&rw.writerSem, false, 1)
}
}3.3 获取写锁 (Lock)
逻辑:先抢内部互斥锁,然后把 readerCount 变成负数(阻断新读者),再等待旧读者离开。
func (rw *RWMutex) Lock() {
// 1. 获取互斥锁,解决 写-写 竞争
rw.w.Lock()
// 2. 反转 readerCount:减去 rwmutexMaxReaders
// 这一步之后,readerCount 变为负数。
// 新来的 RLock 会发现值 < 0,从而阻塞。
r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders
// 3. r 是减去之前的读者数量。如果 r != 0,说明当前还有旧读者未离开
if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 {
// 4. 还有读者,写锁进入休眠,等待 writerSem 信号量
runtime_SemacquireMutex(&rw.writerSem, false, 0)
}
// 5. 没有读者,或者被唤醒,获取写锁成功
}- Writer Priority(写优先):一旦执行了第 2 步,
readerCount变负,后续新来的RLock都会被阻塞。这避免了“读锁源源不断导致写锁永远拿不到”的情况(写饥饿)。
3.4 释放写锁 (Unlock)
逻辑:把 readerCount 变回正数,唤醒所有阻塞的读者,最后释放内部互斥锁。
func (rw *RWMutex) Unlock() {
// 1. 反转 readerCount:加回 rwmutexMaxReaders
r := atomic.AddInt32(&rw.readerCount, rwmutexMaxReaders)
// 2. 此时 r 是被阻塞的读者数量(因为写锁持有期间,新来的读者都在排队)
// 循环唤醒所有等待的读者
for i := 0; i < int(r); i++ {
runtime_Semrelease(&rw.readerSem, false, 0)
}
// 3. 释放互斥锁,允许其他写锁进入
rw.w.Unlock()
}4. 总结图解
为了方便理解,我们可以把状态分为三个阶段:
纯读状态:
readerCount> 0。RLock只是原子 +1。Lock来了,抢w锁,把readerCount变负。
写锁等待状态(写锁已调用 Lock,但旧读者还没走完):
readerCount< 0 (绝对值很大)。readerWait> 0 (记录剩下的旧读者)。- 新来的
RLock发现readerCount< 0,阻塞在readerSem。 - 旧的
RUnlock发现readerCount< 0,去减readerWait。减到 0 时唤醒写锁。
写锁持有状态:
- 写锁干活中。
- 新来的
RLock继续阻塞。 - 新来的
Lock阻塞在rw.w上。 - 写锁
Unlock时,恢复readerCount,唤醒所有阻塞的读者。
5. 关键设计哲学
写锁饥饿问题(Writer Starvation):
Go 的 RWMutex 是写锁优先的(从 Go 1.9 开始优化)。
一旦 Writer 尝试获取锁(修改了readerCount),新的 Reader 就会被阻塞,直到 Writer 完成。这防止了在高并发读取场景下,Writer 永远抢不到锁的问题。互斥锁复用:
利用sync.Mutex来保证写锁之间的串行化,避免了重复造轮子。原子操作性能:
在没有写锁竞争的场景下,RLock/RUnlock仅仅是原子加减操作,没有系统调用(syscall),性能非常高。
6. 注意事项
- 不可复制:
sync.RWMutex包含状态,复制会导致死锁或 panic(这也是为什么通常在结构体中用指针*sync.RWMutex)。 - 不可递归读锁:如果一个 goroutine 拿了写锁,还没释放,又去拿读锁,或者拿了读锁又去拿写锁,极易造成死锁。
- 典型死锁场景:G1 RLock -> G2 Lock (等待 G1) -> G1 RLock (等待 G2,因为写优先,G2 阻断了新读锁)。
- 性能权衡:虽然 RWMutex 读并发性能好,但如果读写竞争极其激烈,或者临界区非常小,标准
Mutex的性能可能反而更好(因为 RWMutex 逻辑更复杂)。