Spark的动态资源分配(Dynamic Resource Allocation)
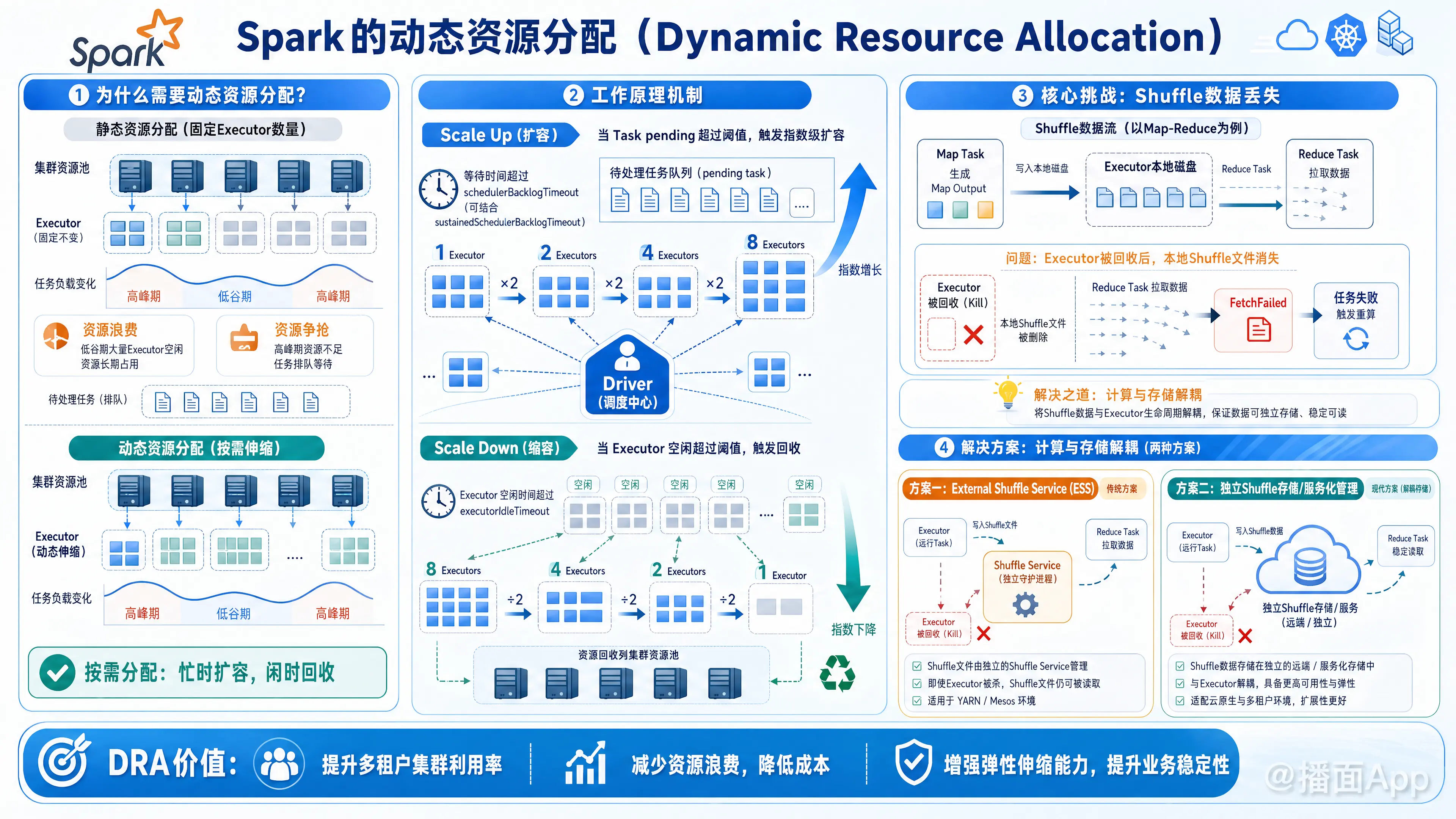
Spark 动态资源分配 (Dynamic Resource Allocation, DRA) 是 Apache Spark 提供的一项核心功能,它允许 Spark 应用程序根据当前的负载情况,自动地增加或减少 Executor(执行器)的数量。
这项功能主要用于解决静态资源分配(Static Allocation)带来的资源浪费或资源不足问题,特别是在多租户集群(如 YARN、Kubernetes)中,它能显著提高集群的整体利用率。
以下是关于 Spark 动态资源分配的详细解析:
1. 为什么需要动态资源分配?
在默认情况下(静态分配),Spark 应用在启动时会申请固定数量的 Executor,并在整个应用生命周期内一直持有它们,直到应用结束。这会带来两个主要问题:
- 资源浪费:如果一个作业包含多个阶段(Stage),其中某些阶段计算量大,而其他阶段计算量小,那么在负载低的阶段,持有的 Executor 处于空闲状态,浪费了集群资源。
- 资源争抢:在多租户环境中,如果一个长运行的作业占用了大量它并不时刻需要的资源,会导致其他作业无法获取资源而排队等待。
DRA 的目标:按需分配。忙的时候多要点,闲的时候退还给集群。
2. 工作原理机制
DRA 主要包含两个策略:请求资源(Scale Up) 和 释放资源(Scale Down)。
A. 请求策略 (Scaling Up)
当 Spark Driver 发现有 Task 处于 pending(等待)状态时,意味着当前的 Executor 不足以处理并行任务,它会触发扩容:
- 触发条件:如果有 Task 等待时间超过了
spark.dynamicAllocation.schedulerBacklogTimeout(默认 1秒)。 - 增长方式:Spark 采用指数级增长的方式申请 Executor(例如:1, 2, 4, 8...)。
- 原因:为了应对突然爆发的负载,快速满足需求。
- 后续请求:如果队列中仍有积压,每隔
spark.dynamicAllocation.sustainedSchedulerBacklogTimeout秒继续申请。
B. 释放策略 (Scaling Down)
当 Executor 处于空闲状态时,Spark 会将其回收:
- 触发条件:如果一个 Executor 空闲时间超过了
spark.dynamicAllocation.executorIdleTimeout(默认 60秒)。 - 动作:Driver 通知集群管理器(如 YARN/K8s)杀死该 Executor 并释放资源。
3. 核心挑战:Shuffle 数据丢失问题
这是 DRA 中最棘手的技术难点。
问题:Executor 不仅负责计算,还负责存储 Shuffle 过程中的中间文件(Map Output)。如果一个 Executor 因为空闲被回收(Kill),它本地磁盘上的 Shuffle 文件也会随之消失。当后续 Stage 需要拉取这些数据(Reduce 阶段)时,就会报错(FetchFailed),导致任务重算。
解决方案:
为了安全地回收 Executor,必须将计算与存储解耦。Spark 提供了两种方案:
External Shuffle Service (ESS) - 传统方案 (YARN/Mesos)
- 在集群的每个 NodeManager (Worker) 上运行一个独立的守护进程(Shuffle Service)。
- Executor 产生的 Shuffle 文件由这个 Service 管理。
- 即使 Executor 被杀掉,Shuffle Service 依然存在,后续任务可以通过 Service 读取数据。
- 缺点:运维复杂,升级 Spark 版本时可能需要重启集群层面的 Service。
Shuffle Tracking (Shuffle 追踪) - 新方案 (Kubernetes)
- 自 Spark 3.0 引入,主要为 K8s 设计(因为 K8s 上部署 ESS 很麻烦)。
- Driver 会追踪哪些 Executor 上存有活跃的 Shuffle 数据。
- 如果一个 Executor 上有还没被消费的 Shuffle 数据,即使它空闲了,Spark 也不会回收它,直到数据被消费或超时(GC)。
- 优点:无需配置外部服务。
4. 关键配置参数
要启用 DRA,通常需要在 spark-defaults.conf 或提交命令中配置以下参数:
基础开关
# 启用动态分配
spark.dynamicAllocation.enabled = true
# 必须启用外部 Shuffle 服务 OR Shuffle Tracking (二选一)
# 方案一:使用 External Shuffle Service (常见于 YARN)
spark.shuffle.service.enabled = true
# 方案二:使用 Shuffle Tracking (常见于 K8s)
spark.dynamicAllocation.shuffleTracking.enabled = true数量限制 (非常重要)
# 初始 Executor 数量
spark.dynamicAllocation.initialExecutors = 1
# 最小 Executor 数量 (保证应用不被完全饿死)
spark.dynamicAllocation.minExecutors = 1
# 最大 Executor 数量 (防止应用吃光整个集群资源)
spark.dynamicAllocation.maxExecutors = 100时间阈值
# 任务积压多久后开始申请新 Executor
spark.dynamicAllocation.schedulerBacklogTimeout = 1s
# Executor 空闲多久后被回收
spark.dynamicAllocation.executorIdleTimeout = 60s
# 如果有缓存数据(Cached Data),空闲多久回收 (通常设置得更长以防缓存丢失)
spark.dynamicAllocation.cachedExecutorIdleTimeout = infinity5. 优缺点总结
| 优点 | 缺点 |
|---|---|
| 成本优化:云环境下按使用量付费,闲置回收可省钱。 | 冷启动延迟:新申请 Executor 需要时间(启动 JVM 等),可能导致最初的任务有延迟。 |
| 集群并发度:释放的资源可供其他作业使用,提升吞吐量。 | 稳定性风险:如果配置不当(如 maxExecutors 太大),可能导致资源震荡(频繁申请/释放)。 |
| 适应性:无需预先准确估算作业所需的资源量。 | Shuffle 复杂性:需要维护 External Shuffle Service 或配置 Tracking。 |
6. 最佳实践建议
- 一定要设置
maxExecutors:如果不设置,Spark 可能会在负载高时申请无限多的 Executor,导致集群其他任务饿死。 - 处理数据倾斜:如果发生严重的数据倾斜,少数 Task 运行极慢,其他 Executor 会空闲并被回收。当慢 Task 结束后进行 Shuffle 时,可能因为并发度不够导致拉取变慢。
- 流处理 (Spark Streaming/Structured Streaming):
- 通常不建议在流处理中开启 DRA。
- 因为流处理批次间隔很短,频繁的申请和释放资源跟不上处理节奏,反而造成抖动。
- K8s 环境:推荐使用
spark.dynamicAllocation.shuffleTracking.enabled=true,避免在 K8s 节点上部署 DaemonSet 形式的 Shuffle Service,简化运维。
总结
Spark 动态资源分配是提升大规模集群效率的神器。它通过监控任务积压和 Executor 空闲状态,配合 External Shuffle Service 或 Shuffle Tracking 技术,实现了计算资源的弹性伸缩。