Driver 节点和 Executor 节点的主要职责分别是什么?
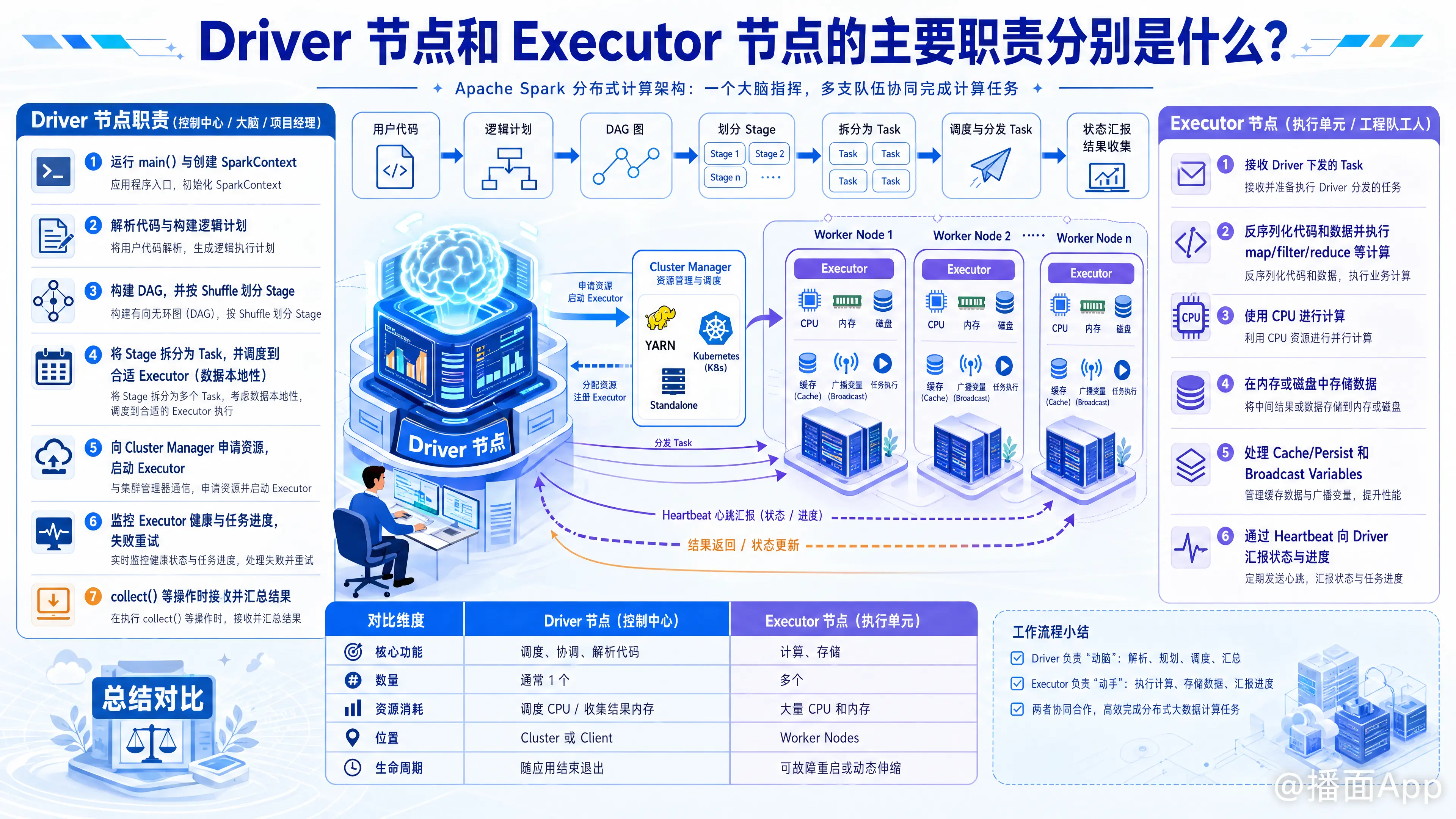
在分布式计算框架(最典型的是 Apache Spark)中,Driver(驱动器) 和 Executor(执行器) 是两个核心组件。
简单来说:Driver 是“大脑”,负责指挥和调度;Executor 是“手脚”,负责干活和存储数据。
以下是它们的详细职责划分:
1. Driver 节点 (驱动器)
Driver 是运行应用程序 main() 函数并创建 SparkContext 的进程。它是整个应用的控制中心。
主要职责:
- 解析代码与构建逻辑:
- 运行用户编写的代码。
- 将用户代码中的转化操作(Transformations)和动作操作(Actions)转化为逻辑执行计划。
- 构建 DAG (有向无环图):
- 将逻辑计划转化为物理执行计划,生成 DAG。
- 根据 Shuffle 依赖关系,将 DAG 划分为多个 Stage(阶段)。
- 任务调度 (Task Scheduling):
- 将 Stage 进一步拆分为更小的 Task(任务)(Task 是最小的计算单元)。
- 决定将这些 Task 发送给哪个 Executor 去执行(基于数据本地性原则,即尽量把计算移动到数据所在的地方)。
- 资源申请与管理:
- 向 Cluster Manager(如 YARN、K8s、Standalone)申请资源(即启动 Executor)。
- 监控与元数据管理:
- 监控所有 Executor 的健康状况和任务执行进度。
- 如果某个 Task 失败,Driver 负责重新调度该任务。
- 结果收集:
- 在程序执行
collect()等操作时,接收 Executor 返回的计算结果并展示给用户。
- 在程序执行
2. Executor 节点 (执行器)
Executor 是运行在工作节点(Worker Node)上的一个进程。一个 Worker 节点上可以运行多个 Executor。
主要职责:
- 执行任务 (Task Execution):
- 接收 Driver 发送过来的 Task。
- 反序列化代码和数据,利用 CPU 资源执行具体的计算逻辑(如 map, filter, reduce 等)。
- 数据存储与缓存 (Data Storage):
- 负责在内存(Memory)或磁盘(Disk)中存储计算过程中的数据。
- 处理 RDD 的缓存(Cache/Persist)以及广播变量(Broadcast Variables)。
- 状态汇报:
- 通过心跳机制(Heartbeat)定期向 Driver 汇报自身的健康状态。
- 汇报当前正在执行的任务进度和状态(成功/失败)。
总结对比
| 特性 | Driver (大脑) | Executor (手脚) |
|---|---|---|
| 核心功能 | 调度、协调、解析代码 | 计算、存储 |
| 数量 | 通常 1 个 (每个应用) | 多个 (分布式并行) |
| 资源消耗 | 主要消耗 CPU (用于调度) 和 内存 (用于收集结果) | 大量消耗 CPU (计算) 和 内存 (存数据) |
| 位置 | 可以运行在集群内 (Cluster Mode) 或 客户端 (Client Mode) | 始终运行在集群的工作节点 (Worker Nodes) 上 |
| 生命周期 | 与整个 Spark Application 绑定,应用结束则 Driver 退出 | 可能会因为故障重启,也可以动态伸缩 |
形象的比喻
想象一个建筑工程队:
- Driver 是“项目经理”:他手里拿着图纸(代码),知道大楼要怎么盖。他把工程拆分成具体的任务(比如砌墙、搬砖),然后指派给工人,并监督进度。
- Executor 是“建筑工人”:他们听从项目经理的指挥,领取具体的任务去执行。他们不仅出力干活(计算),还要负责保管身边的建筑材料(数据存储)。
右滑查看面试常问