Flink Checkpoint 和 Savepoint(保存点)的区别是什么?
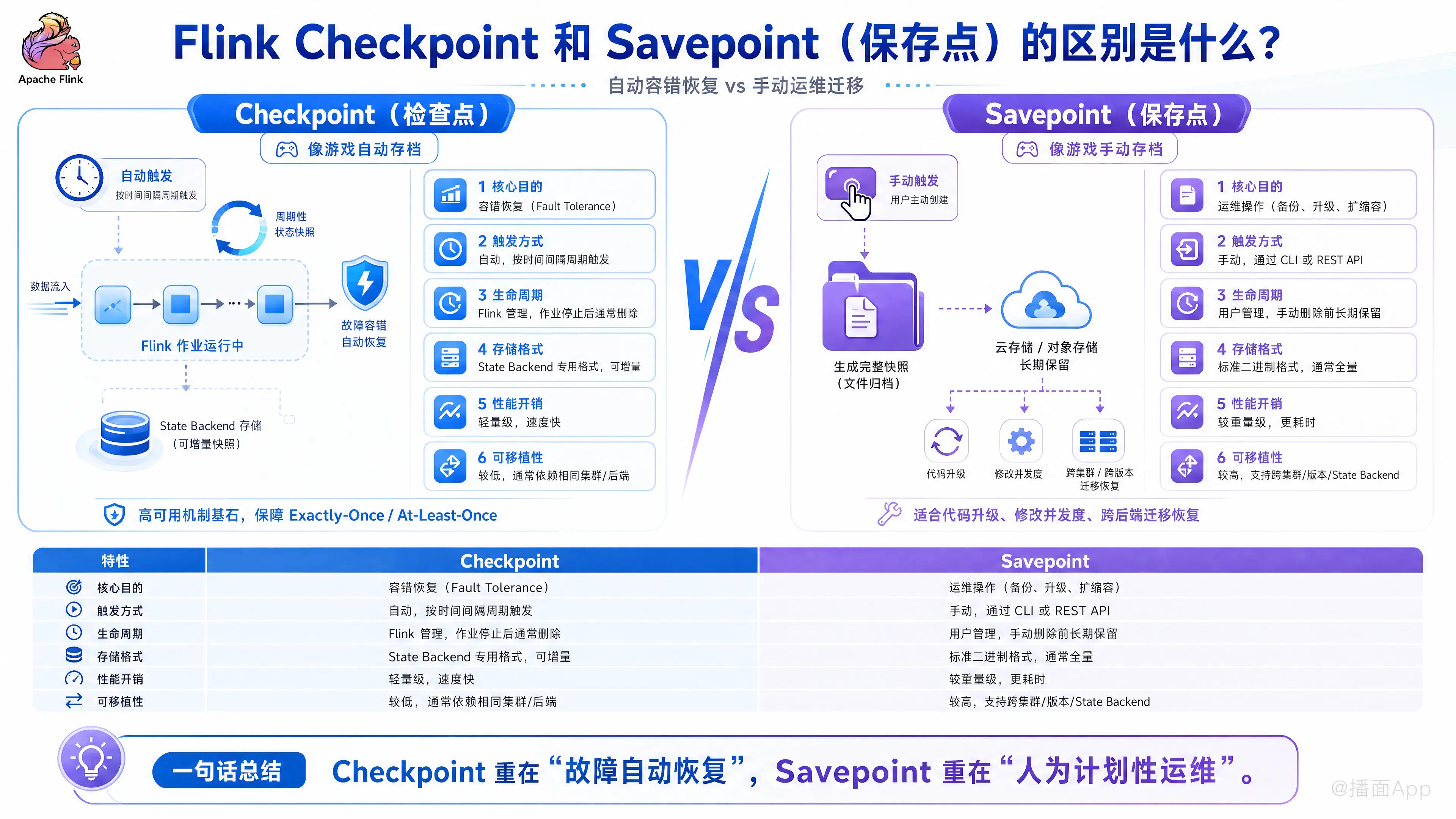
Apache Flink 中的 Checkpoint(检查点) 和 Savepoint(保存点) 虽然都是用于保存作业状态(State)的快照机制,且底层实现原理相似(都基于 Chandy-Lamport 算法),但它们的设计目的、生命周期和使用场景有本质的区别。
可以将它们简单类比为:
- Checkpoint 是游戏的自动存档(为了防止突然死机,系统自动存的,速度快)。
- Savepoint 是游戏的手动存档(你要关机睡觉了,或者要打最终BOSS前,手动存一个永久档,以后可以随时读取)。
以下是详细的对比分析:
1. 核心区别对比表
| 特性 | Checkpoint (检查点) | Savepoint (保存点) |
|---|---|---|
| 核心目的 | 容错恢复 (Fault Tolerance)。用于作业意外失败(如机器宕机、网络中断)后的自动重启恢复。 | 运维操作 (Operations)。用于有计划的备份、更新代码、修改并发度、版本升级等。 |
| 触发方式 | 自动。由 Flink JobManager 根据配置的时间间隔周期性触发。 | 手动。由用户通过命令行(CLI)或 REST API 触发。 |
| 生命周期 | Flink 管理。默认情况下,作业停止(Stop/Cancel)后会被删除(除非配置了保留策略)。 | 用户管理。即使用户取消了作业,它也会永久保留在文件系统中,直到用户手动删除。 |
| 存储格式 | State Backend 专用格式。例如 RocksDB 的 SST 文件。通常支持增量(Incremental),速度快。 | 标准格式 (Canonical Format)。将状态序列化为标准二进制流,不依赖特定 State Backend。通常是全量(Full),速度相对较慢。 |
| 性能开销 | 轻量级。设计目标是快速、低开销,尽量减少对运行中作业的影响。 | 重量级。生成过程可能耗时较长,占用更多 I/O 和 CPU。 |
| 可移植性 | 较低。通常只能在相同的集群配置和 State Backend 下恢复。 | 较高。支持跨集群、跨 Flink 版本、跨 State Backend(如从 Memory 切换到 RocksDB)恢复。 |
2. 详细维度解析
A. 目标用途 (Purpose)
- Checkpoint: 是 Flink 高可用性(HA) 机制的基石。它的存在是为了让 Flink 任务在遇到故障时,能够自动回滚到最近一次成功的状态,从而保证数据处理的 Exactly-Once 或 At-Least-Once 语义。它不需要用户操心。
- Savepoint: 是给用户用的工具。当你需要停止作业去修改代码(修复 Bug)、扩缩容(改变并行度)、或者升级 Flink 版本时,你需要先触发一个 Savepoint,然后基于这个 Savepoint 启动新作业。
B. 数据格式与状态后端 (Format & State Backend)
- Checkpoint: 数据格式通常与配置的 State Backend 强绑定。
- 例如,如果使用
RocksDBStateBackend并开启了增量 Checkpoint,那么 Checkpoint 目录里存的就是 RocksDB 的 SST 文件。这种方式恢复速度极快,但难以跨 State Backend 迁移。
- 例如,如果使用
- Savepoint: 使用一种标准化的二进制格式。
- 这意味着你可以用
HashMapStateBackend运行作业,触发 Savepoint,然后修改配置使用RocksDBStateBackend从该 Savepoint 恢复。这在状态数据量暴涨需要切换后端时非常有用。
- 这意味着你可以用
C. 目录结构 (Directory Structure)
在分布式文件系统(如 HDFS/S3)上,它们的存储路径通常如下:
- Checkpoint:
.../checkpoints/<job-id>/chk-1,chk-2... - Savepoint:
.../savepoints/savepoint-<short-job-id>-<uuid>
D. 扩缩容 (Rescaling)
- 虽然现在的 Flink 版本也支持从 Checkpoint 进行 Rescaling(修改并行度),但官方推荐且最稳健的方式依然是使用 Savepoint。Savepoint 在处理并行度改变时的状态重分配(Key Group 重分配)上兼容性最好。
3. 什么时候用哪个?
使用 Checkpoint 的场景:
- 日常运行任务时。
- 你需要在
flink-conf.yaml或代码中配置execution.checkpointing.interval。 - 当 TaskManager 挂掉、网络抖动导致任务失败时,Flink 会自动寻找最近的 Checkpoint 恢复。
使用 Savepoint 的场景:
- 更新应用程序代码:修复了业务逻辑 Bug,需要重启任务。
- Flink 版本升级:从 Flink 1.14 升级到 1.17。
- 扩容/缩容:流量高峰期增加并行度,低峰期减少并行度。
- A/B 测试:使用相同的源状态启动两个不同逻辑的作业进行对比。
- 集群迁移:将任务从一个 Hadoop 集群迁移到另一个集群。
4. 总结
- Checkpoint 是给 Flink 引擎 看的,为了活下去(容错)。
- Savepoint 是给 开发者/运维 看的,为了过得更好(升级、维护、迁移)。
注意: 从 Flink 1.15 开始,Flink 引入了 "Native Savepoint"(原生保存点)的概念,允许 Savepoint 使用特定 State Backend 的格式(类似 Checkpoint)来加速生成速度,但这属于进阶优化,上述的核心概念区别依然适用。
右滑查看面试常问