Flink Checkpoint(检查点)底层原理
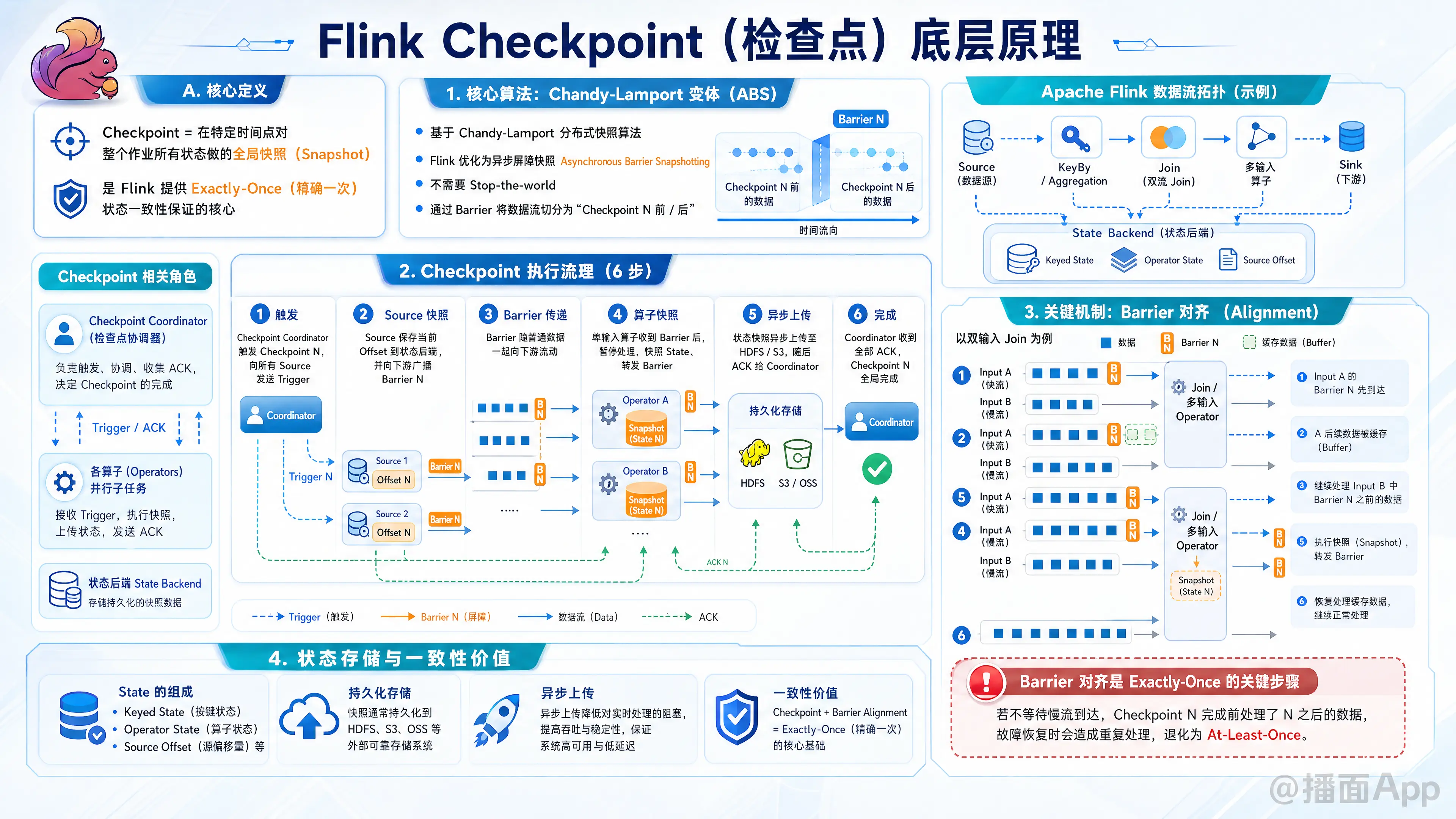
Apache Flink 的 Checkpoint(检查点)机制是其能够提供 Exactly-Once(精确一次) 状态一致性保证的核心。
简单来说,Checkpoint 就是 Flink 在某个特定时间点上,对整个作业的所有状态(State)做的一个全局快照(Snapshot)。
以下是 Flink Checkpoint 的底层原理深度解析,主要包含核心算法、执行流程、对齐机制和状态存储四个方面。
1. 核心算法:Chandy-Lamport 变体 (ABS)
Flink 的 Checkpoint 算法基于经典的 Chandy-Lamport 分布式快照算法,但针对流处理做了优化,称为 异步屏障快照(Asynchronous Barrier Snapshotting, ABS)。
核心思想:
Flink 不会“停止整个世界”(Stop-the-world)来做备份,而是通过在数据流中注入特殊的标记——Barrier(屏障),让 Barrier 随着数据一起流动。Barrier 将数据流切分为“Checkpoint N 之前的数据”和“Checkpoint N 之后的数据”。
2. Checkpoint 的执行流程
整个过程由 JobManager 中的 Checkpoint Coordinator 协调。
触发 (Trigger):
Coordinator 决定触发 Checkpoint N,向所有的 Source 算子发送 Trigger 消息。Source 快照:
Source 收到消息后,暂停发出新数据,保存当前读取的 Offset(偏移量) 到状态后端,然后向下游广播 Barrier N,随即恢复发送数据。Barrier 传递 (Propagation):
Barrier 像普通数据一样流向下游算子。算子快照 (Operator Snapshot):
当一个非 Source 算子收到 Barrier N 时:- 如果是单输入算子:立刻暂停处理数据,对当前算子的 State(如 KeyedState, OperatorState)制作快照,然后将 Barrier N 广播给下游。
- 如果是多输入算子(如 Join, KeyBy 后的聚合):需要进行 Barrier 对齐(Alignment)(详见下文)。
异步上传:
算子将状态快照异步上传到持久化存储(如 HDFS、S3)。上传完成后,向 Coordinator 发送 ACK。完成:
当 Coordinator 收到所有算子的 ACK 后,认为 Checkpoint N 全局完成。
3. 关键机制:Barrier 对齐 (Barrier Alignment)
这是实现 Exactly-Once 的关键步骤,主要发生在多输入流汇聚的算子中。
场景:算子有两个输入流 Input A 和 Input B
- 等待: 假设 Input A 的 Barrier N 先到达,Input B 的 Barrier N 还没到。
- 缓存 (Buffer): 算子会暂停处理 Input A 的后续数据(即 Barrier N 之后的数据),将它们放入缓存区。
- 为什么要暂停? 因为 Barrier N 之后的数据属于下一个 Checkpoint,如果在 Checkpoint N 完成前处理了,一旦发生故障恢复到 N,这部分数据会被重复处理(导致 At-Least-Once)。
- 继续处理 B: 在等待期间,算子继续处理 Input B 的数据(属于 Checkpoint N 之前的数据)。
- 对齐完成: 当 Input B 的 Barrier N 也到达时,对齐完成。
- 快照与转发: 算子进行状态快照,并向下游发送 Barrier N。
- 恢复: 释放 Input A 的缓存数据,继续正常处理。
At-Least-Once 模式下的对齐:
如果你配置的是 At-Least-Once 语义,Flink 不会缓存 Input A 的数据。即使 Input B 的 Barrier 没到,它也会直接处理 Input A 的新数据。这虽然降低了延迟,但如果故障恢复,这部分数据会被重放,导致重复计算。
4. 状态后端 (State Backends)
Checkpoint 的数据到底存在哪里?这取决于 State Backend 的配置。
Flink 将状态分为两层:
- 工作状态 (Working State): 算子运行时读写的状态(在内存或本地磁盘)。
- 持久化状态 (Persisted State): Checkpoint 产生的文件(在 HDFS/S3)。
主要后端类型:
- HashMapStateBackend (基于内存):
- 原理: 数据以 Java 对象形式存在 JVM 堆内存中。
- Checkpoint: 序列化内存中的对象并上传到 HDFS。
- 优缺点: 读写极快,但受限于内存大小,GC 压力大。
- EmbeddedRocksDBStateBackend (基于 RocksDB):
- 原理: 数据序列化后存储在 TaskManager 本地的 RocksDB 数据库(基于磁盘/SSD 的 KV 存储)中。
- Checkpoint: 利用 RocksDB 的快照机制,支持 增量 Checkpoint (Incremental Checkpoint)。即只上传自上次 Checkpoint 以来修改过的 SST 文件,而不是全量数据。
- 优缺点: 支持超大状态(TB 级),不受内存限制,但序列化/反序列化有开销,读写稍慢。
5. 进阶:非对齐 Checkpoint (Unaligned Checkpoint)
背景:
传统的 Barrier 对齐机制有一个缺点:如果产生反压(Backpressure),数据处理慢,Barrier 会被堵在路上,导致 Checkpoint 超时。
原理:
Unaligned Checkpoint 不等待 Barrier 对齐。
- 当 Barrier 到达算子的任意一个输入通道时,算子立刻将该 Barrier 发送给下游。
- 关键点: 算子不仅保存自己的 State,还会把输入缓冲区(Input Buffers)和输出缓冲区(Output Buffers)中所有“在路上”的数据也一起保存到 Checkpoint 中。
优缺点:
- 优点: 即使在严重反压下也能快速完成 Checkpoint。
- 缺点: Checkpoint 文件体积变大(存了大量 inflight 数据),I/O 压力增加,恢复速度变慢。
6. 故障恢复 (Recovery)
当 Flink 任务失败时:
- 重启: JobManager 重启所有 Task。
- 加载: 算子从最近一次成功的 Checkpoint 中加载状态(State)。
- 重置: Source 算子根据 Checkpoint 中保存的 Offset,重置读取位置。
- 重放: 从 Offset 开始重新消费数据。由于 State 回滚到了当时的快照,配合数据重放,实现了 Exactly-Once。
总结
Flink Checkpoint 的底层原理可以概括为:
利用 Chandy-Lamport 算法的变体(ABS),通过在数据流中插入 Barrier 来切分时间段,利用 Barrier 对齐机制保证状态的一致性(Exactly-Once),并将状态异步持久化到远程存储(如 HDFS)中。