ZooKeeper的Follower 接收到写请求会怎么处理?
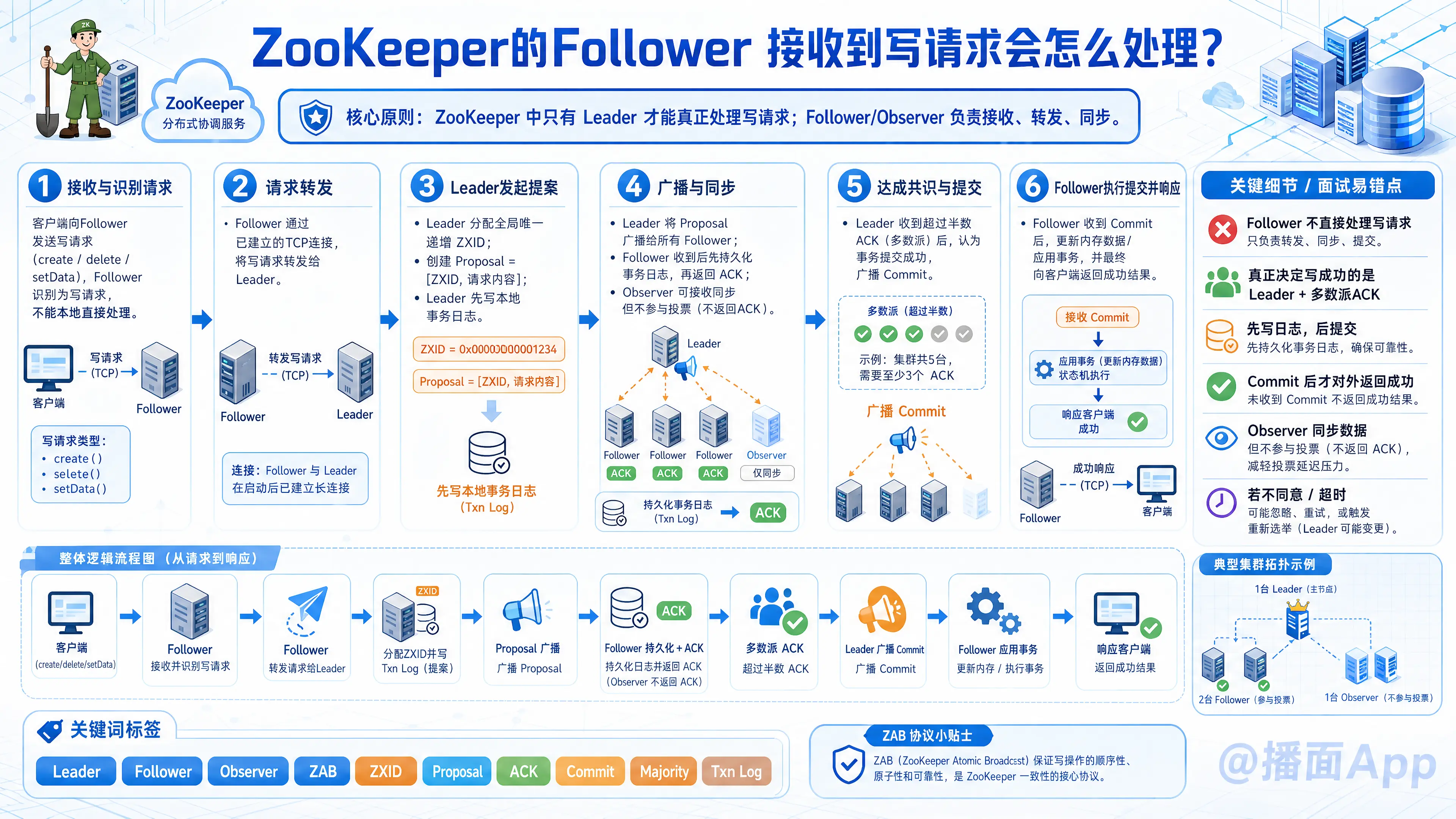
这是一个非常经典的 ZooKeeper 面试题和核心知识点。我们来详细拆解一下 ZooKeeper Follower 接收到写请求后的完整处理流程。
首先,要记住一个核心原则:在 ZooKeeper 集群中,只有 Leader 节点才能处理写请求。Follower 和 Observer 节点本身并不直接处理写请求,它们的主要角色是接收客户端请求、转发给 Leader、并参与投票/同步数据。
下面我们分步骤详细说明 Follower 接收到写请求后的处理过程:
整体流程图(逻辑示意)
plaintext
graph TD
A[客户端向Follower发送写请求] --> B{Follower接收请求};
B --> C[Follower将请求转发给Leader];
C --> D[Leader生成事务Proposal];
D --> E[Leader广播Proposal给所有Follower];
E --> F[Follower收到Proposal并处理];
F --> G{是否同意该Proposal?};
G -- 同意 --> H[Follower持久化事务日志<br>并向Leader发送ACK];
G -- 不同意/超时 --> I[忽略或触发重新选举];
H --> J[Leader收到多数派ACK];
J --> K[Leader提交Commit];
K --> L[Leader广播Commit消息];
L --> M[Follower执行Commit<br>更新内存数据并通知客户端];
M --> N[Follower响应客户端成功];详细步骤解析
第1步:接收与识别请求
- 客户端连接:客户端可能通过任意一台 ZooKeeper 服务器(可能是 Leader、Follower 或 Observer)的连接端口建立会话。
- 请求类型判断:当这台 Follower 服务器收到客户端的请求时,它内部的请求处理器链会首先判断请求的类型。
- 写请求识别:如果该请求是写操作(如
create,delete,setData等),Follower 会识别出自己不能直接处理。
第2步:请求转发
- 转发至 Leader:Follower 会通过其已有的 TCP 连接,将该写请求原封不动地转发给集群当前的 Leader 节点。这是最关键的一步。对于客户端来说,它感觉不到这个转发过程,因为最终还是会收到响应。
第3步:Leader 发起提案(Propose)
- Leader 处理:Leader 收到来自 Follower 转发的写请求后,开始标准的 ZAB 协议写流程:
- 分配ZXID:为这个写操作生成一个全局唯一的、递增的事务ID(ZXID)。
- 创建 Proposal:将这个写操作封装成一个提案(Proposal),内容为
[ZXID, 请求内容]。 - 持久化:Leader 首先在自己的磁盘上持久化这个提案(写入事务日志文件)。
第4步:广播提案与同步
- 广播 Proposal:Leader 通过 ZAB 协议的原子广播阶段,将这个 Proposal 广播给集群中所有的 Follower 节点(以及 Observer,但 Observer 不参与投票)。
- Follower 处理 Proposal:
- 接收与持久化:每个 Follower 收到 Proposal 后,同样会在自己的磁盘上持久化这个事务日志。这是一个关键的安全步骤,确保了即使节点重启,也能恢复未提交的事务。
- 发送 ACK:Follower 完成持久化后,会向 Leader 发送一个确认(ACK)消息,表示“我已经收到了这个提案并安全保存了”。
第5步:达成共识与提交
- Leader 等待多数派确认:Leader 需要收到超过半数(Quorum) 的 Follower 返回的 ACK(包括 Leader 自己的一票)。这个“多数派”机制保证了即使在部分节点故障时,集群依然能正常工作,这也是 ZooKeeper 高可用的基础。
- Leader 发起 Commit:一旦达成多数派共识,Leader 就会进入提交阶段:
- Leader 自己先执行这个写操作,将数据变更应用到自己内存中的 DataTree。
- Leader 然后向所有 Follower 广播 Commit 消息,告知它们可以提交了。
第6步:Follower 执行与响应
- Follower 执行 Commit:
- Follower 收到 Commit 消息后,正式执行该写操作,将数据变更应用到自己的内存数据库中。
- 同时,Follower 会更新其内存中的
lastProcessedZxid。
- 响应客户端:
- 现在,最初接收到客户端请求的那个 Follower 节点,会从它自己的内存状态中得知该写操作已经成功。
- 于是,这个 Follower 节点向客户端返回成功响应(例如,返回新创建的节点的路径或版本号等信息)。
总结与要点
- 核心角色:Follower 是写请求的 “中转站” 而非“处理者”。
- 流程本质:整个过程遵循 ZAB 协议,通过 两阶段提交(2PC) 的变种来实现强一致性。第一阶段是广播 Proposal 并收集 ACK(确保事务被持久化到多数节点),第二阶段是广播 Commit(确保事务在所有节点上生效)。
- 为什么这样设计:
- 简化设计:所有写操作都经过单一 Leader,避免了分布式系统中复杂的写冲突解决。
- 保证顺序:Leader 为所有事务分配单调递增的 ZXID,保证了全局操作的顺序性。
- 高可用:通过多数派投票机制,容忍少数节点(最多
(n-1)/2)的故障。
- Observer 的区别:如果客户端连接到 Observer,流程完全一样——Observer 也会将写请求转发给 Leader。不同之处在于,Observer 不参与投票(不发送 ACK),只异步接收 Commit 消息来更新数据,因此不会影响 Leader 达成多数派决议的速度,常用于提升读性能且不影响写性能。
所以,当有人问“ZooKeeper 的 Follower 接收到写请求会怎么处理?”时,最准确的回答是:它会将写请求透明地转发给 Leader,然后作为 ZAB 协议的参与者,完成提案的持久化、确认和最终提交,最后再将结果响应给客户端。
右滑查看面试常问