Map与FlatMap的区别
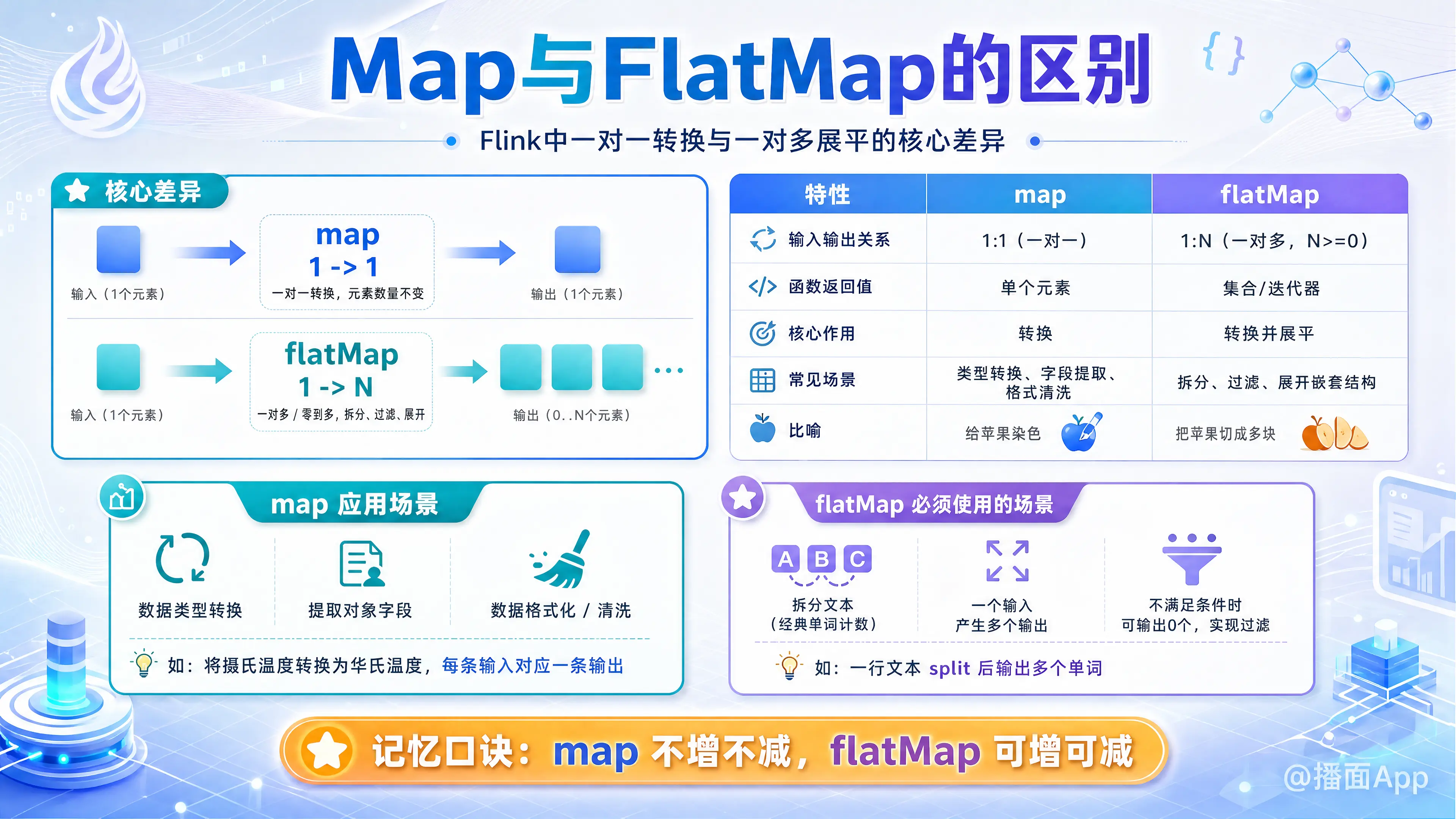
本文重点阐述Flink中map与flatMap的差异:map执行一对一转换,元素数量不变;flatMap执行一对多(或零)转换,用于拆分或过滤数据,如经典的单词计数场景。
我们来详细解释一下 Flink 中 map 和 flatMap 的应用场景差异,并举例说明在什么情况下必须使用 flatMap。
核心差异:输入与输出元素的数量关系
这是理解两者差异最关键的一点:
map:一对一(1 -> 1) 的转换关系。它对数据流(DataStream)中的 每一个 输入元素应用一个函数,并产生 一个 输出元素。输入流中有 N 个元素,经过map操作后,输出流中也必然有 N 个元素。flatMap:一对多(1 -> N, 其中 N >= 0) 的转换/展平关系。它对数据流中的 每一个 输入元素应用一个函数,并产生 零个、一个或多个 输出元素。输出流中的元素数量可能大于、等于或小于输入流。
我们可以用一个简单的表格来总结:
| 特性 | map |
flatMap |
|---|---|---|
| 输入输出关系 | 1 : 1 (一对一) | 1 : N (一对多,N可以是0, 1, 2, ...) |
| 函数返回值 | 返回一个 单个元素 | 返回一个 集合或迭代器(例如 List, Iterator) |
| 核心作用 | 转换 (Transform) | 转换并展平 (Transform and Flatten) |
| 常见场景 | 数据类型转换、数据清洗、对象字段提取 | 拆分、过滤、展开嵌套结构 |
| 比喻 | 对每个苹果染色,得到一个染了色的苹果 | 把每个苹果切成多块,得到一堆苹果块 |
map 的应用场景
当你的需求是简单地转换流中的每一个元素,而不改变元素的数量时,应该使用 map。
场景示例:
- 数据类型转换:将一个包含字符串数字的流,转换为一个整数流。
- 提取对象字段:从一个复杂的
Order对象流中,只提取出orderId字段,形成一个字符串流。 - 数据格式化/清洗:将所有字符串转换为大写,或者去除字符串两端的空格。
代码示例:
假设我们有一个传感器读数流,包含传感器 ID 和摄氏温度。我们想把温度转换为华氏温度。
// 输入数据 POJO
public class SensorReading {
public String id;
public double temperatureCelsius;
// constructor, getters, setters...
}
// Flink 作业
DataStream<SensorReading> sensorStream = ...;
// 使用 map 将摄氏度转换为华氏度
// 输入一个 SensorReading, 输出一个同样包含华氏度的 SensorReading
DataStream<SensorReading> fahrenheitStream = sensorStream.map(reading -> {
reading.setTemperatureFahrenheit(reading.temperatureCelsius * 1.8 + 32);
return reading; // 返回一个元素
});在这个例子中,每条输入的传感器读数 (SensorReading) 经过 map 操作后,都精确地对应一条输出的、增加了华氏温度字段的 SensorReading。元素数量保持不变。
flatMap 的应用场景及【必须使用】的案例
当你的需求是根据一个输入元素,可能产生多个输出元素,或者不产生任何输出(即过滤)时,就必须使用 flatMap。
场景1:拆分(Tokenization)- 【最经典的必须使用 flatMap 的场景】
问题描述:统计文本流中每个单词出现的次数(Word Count)。
输入是一个包含句子的数据流,例如:"Hello Flink""Stream Processing with Flink"
为什么 map 不行?
如果我们尝试用 map 来解决这个问题,map 函数会对每个句子进行 split(" ") 操作。
// 错误示范:使用 map
DataStream<String> sentenceStream = ...;
DataStream<String[]> wordsArrayStream = sentenceStream.map(sentence -> sentence.split(" "));这个操作的输出 wordsArrayStream 是一个 DataStream<String[]> 类型,也就是一个 字符串数组流。流中的元素是 ["Hello", "Flink"] 和 ["Stream", "Processing", "with", "Flink"] 这两个 数组,而不是我们想要的单个单词。后续的 keyBy 和 sum 操作将无法直接对单词进行分组和计数。
为什么必须用 flatMap?
我们需要将每个句子拆分成的单词数组“拍平”(flatten),让每个单词成为流中的一个独立元素。这正是 flatMap 的作用。
正确代码示例:
DataStream<String> sentenceStream = ...;
// 使用 flatMap 将每个句子拆分成多个单词
DataStream<String> wordStream = sentenceStream.flatMap(
(String sentence, Collector<String> out) -> {
for (String word : sentence.split(" ")) {
out.collect(word); // 每个单词作为独立元素向下游发送
}
}
);
// 后续可以进行 word count
DataStream<Tuple2<String, Integer>> wordCountStream = wordStream
.map(word -> new Tuple2<>(word, 1))
.keyBy(0)
.sum(1);在这里:
- 输入
"Hello Flink",flatMap的for循环会执行两次。 out.collect("Hello")将 "Hello" 发送到输出流。out.collect("Flink")将 "Flink" 发送到输出流。- 一个输入元素(一个句子)产生了两个输出元素(两个单词)。
- 最终得到的
wordStream是一个真正的单词流,可以轻松进行后续的聚合操作。
场景2:过滤与转换相结合
问题描述:我们有一个订单流,需要筛选出金额大于 100 元的订单,并将其中的商品列表拆分出来,形成一个商品流。
// 输入数据 POJO
public class Order {
public long orderId;
public double amount;
public List<String> items;
// ...
}
DataStream<Order> orderStream = ...;
// 使用 flatMap 进行过滤和展开
DataStream<String> highValueItemStream = orderStream.flatMap(
(Order order, Collector<String> out) -> {
// 过滤条件:金额大于100
if (order.amount > 100) {
// 展开商品列表
for (String item : order.items) {
out.collect(item);
}
}
// 如果金额不大于100,则该函数不调用 out.collect(),
// 相当于这个输入元素产生了0个输出元素,实现了过滤。
}
);在这个例子中:
- 如果一个订单金额小于等于 100,
flatMap不会产生任何输出(1 -> 0)。 - 如果一个订单金额大于 100 且包含 3 个商品,
flatMap会产生 3 个输出元素(1 -> 3)。
这个功能无法用一个 map 操作完成,因为 map 必须为每个输入都产生一个输出,它不能凭空“丢弃”元素。虽然可以先 filter 再 map,但 flatMap 可以将这两个逻辑优雅地合并在一起。
总结
- 用
map:当你需要对数据流中的每个元素进行 一对一 的简单转换时(比如改个格式、换个类型、加个字段)。 - 用
flatMap:当你需要进行 一对多 的转换时。最典型、必须使用flatMap的场景就是“拆词”或“展开集合”,即需要将一个整体元素拆分成多个独立的子元素,并让这些子元素在下游被独立处理。此外,它也非常适合在转换的同时进行条件过滤。