Elasticsearch 是如何实现近实时(NRT, Near Real-Time)搜索的?
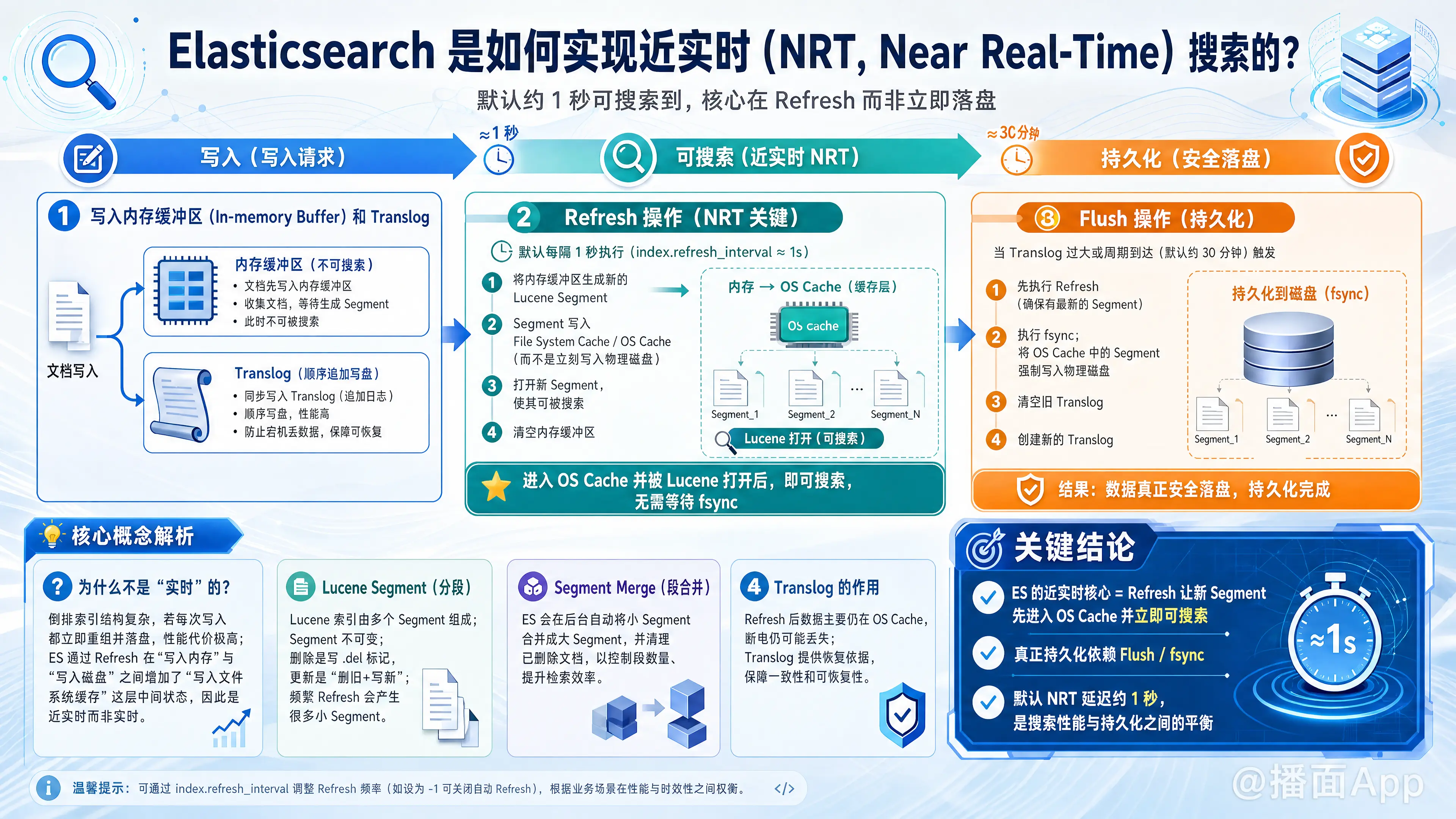
Elasticsearch 实现近实时(Near Real-Time, NRT)搜索的核心在于它如何处理数据的写入、索引和存储。简单来说,ES 牺牲了部分数据写入硬盘的实时性(持久化),换取了极快的检索速度。
通常,ES 的 NRT 延迟默认为 1 秒。也就是说,文档写入后,大约 1 秒钟就可以被搜索到。
以下是其实现原理的详细步骤和核心机制:
核心流程:从写入到可搜索
1. 写入内存缓冲区 (In-memory Buffer) 和 Translog
当一个文档被索引(写入)时,数据会同时被写入两个地方:
- 内存缓冲区 (In-memory Buffer):用于收集当前的文档数据,等待生成索引分段(Segment)。此时数据不可被搜索。
- 事务日志 (Translog):用于防止数据丢失。因为内存是不安全的,如果断电数据会丢失,所以先追加写入 Translog(顺序写磁盘,速度快)。
2. Refresh 操作(NRT 的关键)
这是实现“近实时”最关键的一步。
- 机制:默认每隔 1 秒(
index.refresh_interval),ES 会执行一次 Refresh 操作。 - 过程:
- 将内存缓冲区中的文档生成一个新的 Lucene Segment(分段)。
- 这个 Segment 被写入到 文件系统缓存 (File System Cache / OS Cache) 中,而不是直接写入物理硬盘。
- 打开这个新的 Segment,使其可以被搜索。
- 清空内存缓冲区。
- 原理:写入文件系统缓存(内存操作)比写入物理硬盘(磁盘 I/O)要快得多。只要 Segment 进入了系统缓存并被 Lucene 打开,它就可以被搜索到了,而不需要等待昂贵的
fsync(强制刷盘)操作。
3. Flush 操作(持久化)
虽然数据可以被搜索了,但它还只存在于内存(OS Cache)中。如果此时服务器宕机,数据会丢失。因此需要持久化:
- 机制:当 Translog 变得太大或每隔一段时间(默认 30 分钟),ES 会执行 Flush 操作。
- 过程:
- 执行 Refresh,确保缓冲区数据进入 OS Cache。
- 调用
fsync,将 OS Cache 中的所有 Segment 强制写入物理磁盘。 - 清空旧的 Translog,创建一个新的。
- 结果:数据真正安全地存储在了磁盘上。
核心概念解析
为了更好地理解,需要区分以下几个概念:
1. 为什么不是“实时”的?
因为在数据库(如 MySQL)中,提交事务通常意味着数据落盘(fsync)。但在搜索引擎中,倒排索引的结构很复杂,如果每写一条数据就重新组织索引并落盘,性能会极其低下。
ES 引入了 Refresh 机制,在“写入内存”和“写入磁盘”之间加了一个中间状态——“写入文件系统缓存”。这层缓存使得搜索变得很快,但会有 1 秒左右的延迟。
2. Lucene Segment (分段)
- Lucene 索引由多个 Segment 组成。
- Segment 是不可变的(Immutable)。这意味着一旦生成,就不能修改。
- 删除/更新:由于不可变,删除实际上是写入一个
.del文件标记该文档已删除;更新则是“标记删除旧文档 + 索引新文档”。 - NRT 的代价:由于每秒生成一个新 Segment,会导致 Segment 数量暴增。ES 会在后台自动进行 Segment Merge(段合并),将小段合并成大段,并物理删除被标记的文档。
3. Translog (事务日志) 的作用
Translog 保证了数据的一致性。
- 问题:Refresh 只是把数据写到了内存缓存(OS Cache),如果机器断电,这部分数据就丢了。
- 解决:在 Flush(落盘)发生之前,数据一直保留在 Translog 中。如果重启,ES 会重放 Translog 中的操作来恢复数据。
总结图解
plaintext
[文档写入]
|
v
[内存缓冲区 (Buffer)] + [Translog (磁盘顺序写)]
|
| <-- (每1秒自动 Refresh) --> NRT 的关键
v
[文件系统缓存 (OS Cache)] --> 生成新的 Segment --> [此时可被搜索!]
|
| <-- (每30分钟或日志过大 Flush)
v
[物理硬盘 (Disk)] --> 执行 fsync --> [数据持久化完成,清空 Translog]性能调优启示
理解了 NRT 原理,你就可以根据业务场景进行优化:
- 提高写入速度:如果你在进行大量批量导入(Bulk Indexing),可以临时将
index.refresh_interval设置为-1或更大的值(如30s)。这样可以减少 Segment 的生成频率,降低 I/O 开销,显著提升写入吞吐量。 - 实时性要求不高:如果业务允许 5 秒或 10 秒的延迟,调大
refresh_interval可以减轻集群负载。 - 强制刷新:在单元测试或某些必须立即读到刚写入数据的场景,可以手动调用
_refreshAPI(但不要在生产环境频繁调用,会严重影响性能)。
右滑查看面试常问