面对多语言场景,Embedding 模型应该如何选择?
面对多语言(Multilingual)场景,选择合适的 Embedding 模型是构建高质量 RAG(检索增强生成)或搜索系统的关键。多语言场景的挑战在于:不仅要理解单一语言的语义,还要实现跨语言对齐(例如:用英文搜中文文档,向量空间必须接近)。
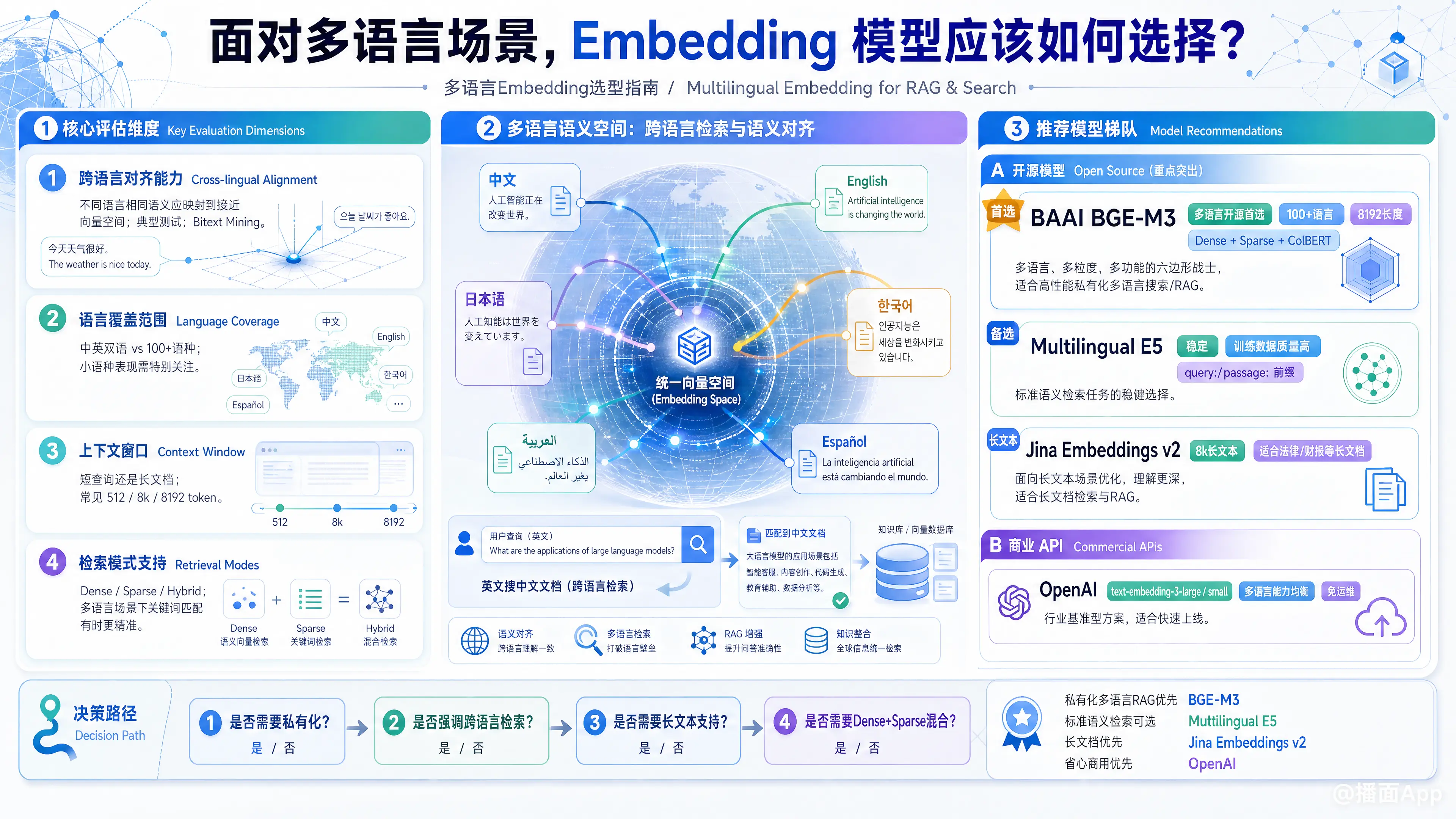
以下是选择多语言 Embedding 模型的详细指南,涵盖了核心指标、推荐模型及决策路径。
一、 核心评估维度
在选择模型前,需明确以下几个关键指标:
- 跨语言对齐能力 (Cross-lingual Alignment):
- 这是最重要的指标。模型能否将不同语言中相同语义的句子映射到向量空间中的相近位置?
- 测试场景: Bitext Mining(双语挖掘)任务。
- 语言覆盖范围 (Language Coverage):
- 模型支持多少种语言?是仅支持中英(Bilingual),还是支持100+种语言(Multilingual)?
- 注意: 对于小语种(Low-resource languages),通用多语言模型的表现通常不如专用模型。
- 上下文窗口 (Context Window):
- 你需要处理短句(搜索查询)还是长文档?
- OpenAI 通常是 8k,开源模型通常是 512 或 8192 token。
- 检索模式支持:
- 是否支持稠密检索(Dense,常规向量)与稀疏检索(Sparse,类似关键词/BM25)的混合?多语言场景下,关键词匹配有时比语义更精准。
二、 推荐模型梯队 (截至 2024 年)
根据目前的 MTEB (Massive Text Embedding Benchmark) 榜单和工业界实践,以下是首选方案:
1. 开源模型 (Self-Hosted / Open Source)
首选推荐:BAAI BGE-M3
- 模型名称:
BAAI/bge-m3 - 特点: 目前多语言开源领域的“六边形战士”。
- M3含义: Multi-linguality (支持100+语言), Multi-granularity (多粒度,最大8192长度), Multi-functionality (多功能)。
- 杀手锏: 它同时支持三种检索方式:
- Dense: 传统的语义向量。
- Sparse (Lexical): 类似 BM25 的关键词权重,解决了跨语言中专有名词匹配难的问题。
- ColBERT (Multi-vector): 精细化匹配,效果好但存储成本高。
- 适用场景: 构建高性能、私有化部署的多语言搜索/RAG 系统。
备选推荐:Multilingual E5
- 模型名称:
intfloat/multilingual-e5-large(或small/base) - 特点: 表现非常稳定,训练数据质量高。需要在查询前加前缀
"query: ",文档前加"passage: "。 - 适用场景: 标准的语义检索任务,资源占用相对适中。
长文本推荐:Jina Embeddings v2
- 模型名称:
jinaai/jina-embeddings-v2-base-de/en(注意:Jina 有专门的多语言版本,需确认具体 checkpoint) - 特点: 支持 8k 长度,适合处理长法律文档或财报。
2. 闭源/商业 API (Commercial APIs)
首选推荐:OpenAI
- 模型:
text-embedding-3-large/text-embedding-3-small - 特点: 行业基准。多语言能力非常均衡,无需维护基础设施。
large版本在多语言细微语义捕捉上优于small。 - 适用场景: 快速验证、不想维护 GPU 服务器、对数据隐私不极其敏感的场景。
专业推荐:Cohere
- 模型:
embed-multilingual-v3.0 - 特点: 专门针对多语言检索优化。Cohere 的模型在处理非英语语言(尤其是欧洲语言和亚洲主要语言)的跨语言检索上,有时表现优于 OpenAI。
- 适用场景: 企业级搜索,特别是需要配合 Cohere 优秀的 Rerank 模型使用时。
Google Cloud:
- 模型:
Gecko(Vertex AI) - 特点: Google 在多语言翻译数据上有天然优势,Gecko 在多语言基准测试中表现强劲。
三、 决策路径图
面对具体项目,请按以下步骤选择:
数据隐私与合规性?
- 必须私有化: 选择 BGE-M3 或 Multilingual-E5。
- 可上云: 选择 OpenAI 或 Cohere。
语言类型?
- 中/英互搜: BGE-M3 效果极佳(BAAI是智源,中文优化好)。
- 包含小语种 (如泰语、希伯来语): 优先考虑 OpenAI 或 Google Gecko,因为它们的训练语料覆盖面最广。
- 特定领域 (医疗/法律): 无论选哪个,可能都需要微调(Fine-tuning)。
精度要求 vs. 延迟要求?
- 极致精度: 使用 BGE-M3 的混合检索(Dense + Sparse) + Reranker(重排序模型)。
- 低延迟/低成本: 使用
text-embedding-3-small或bge-m3(仅使用 Dense 模式)。
四、 避坑指南与最佳实践
在多语言场景下,仅靠 Embedding 往往不够,必须注意以下几点:
必须引入 Reranker (重排序):
- Embedding 做召回(Retrieve top 100),Reranker 做精排(Select top 5)。
- 推荐:
BAAI/bge-reranker-v2-m3或Cohere Rerank Multilingual。 - 原因: 跨语言向量有时会把“语义相关但事实相反”的内容拉得很近,Reranker 能纠正这一点。
混合检索 (Hybrid Search) 是刚需:
- 纯向量检索在多语言场景下容易丢失“专有名词”(如人名、产品型号)。
- 方案: 结合 向量检索 + 关键词检索 (BM25)。BGE-M3 自带的 Sparse 向量就是为了解决这个问题。
Instruction Tuning (指令微调):
- 现在的模型(如 E5, BGE)通常需要指令。
- Query: "Given a web search query, retrieve relevant passages that answer the query."
- 跨语言技巧: 有时将 Query 翻译成目标文档的语言再做 Embedding,效果会比直接跨语言检索好(Query Translation 策略)。
总结建议
- 如果你能跑 GPU 且需要高性能: 直接上 BGE-M3。它是目前开源界处理多语言、多粒度任务的“版本答案”。
- 如果你想省事且效果不错: 使用 OpenAI
text-embedding-3-large。 - 如果你关注跨语言检索的精准度: 务必搭配一个多语言 Reranker。
右滑查看面试常问