在 RAG 中,如何处理复杂的非结构化数据,特别是 PDF 中的表格和图片?
在 RAG(检索增强生成)系统中,PDF 文档中的表格(Tables)和图片(Images/Charts)确实是最大的痛点。传统的文本提取工具(如 PyPDF2)往往会将表格变成一堆乱码,完全忽略图片。
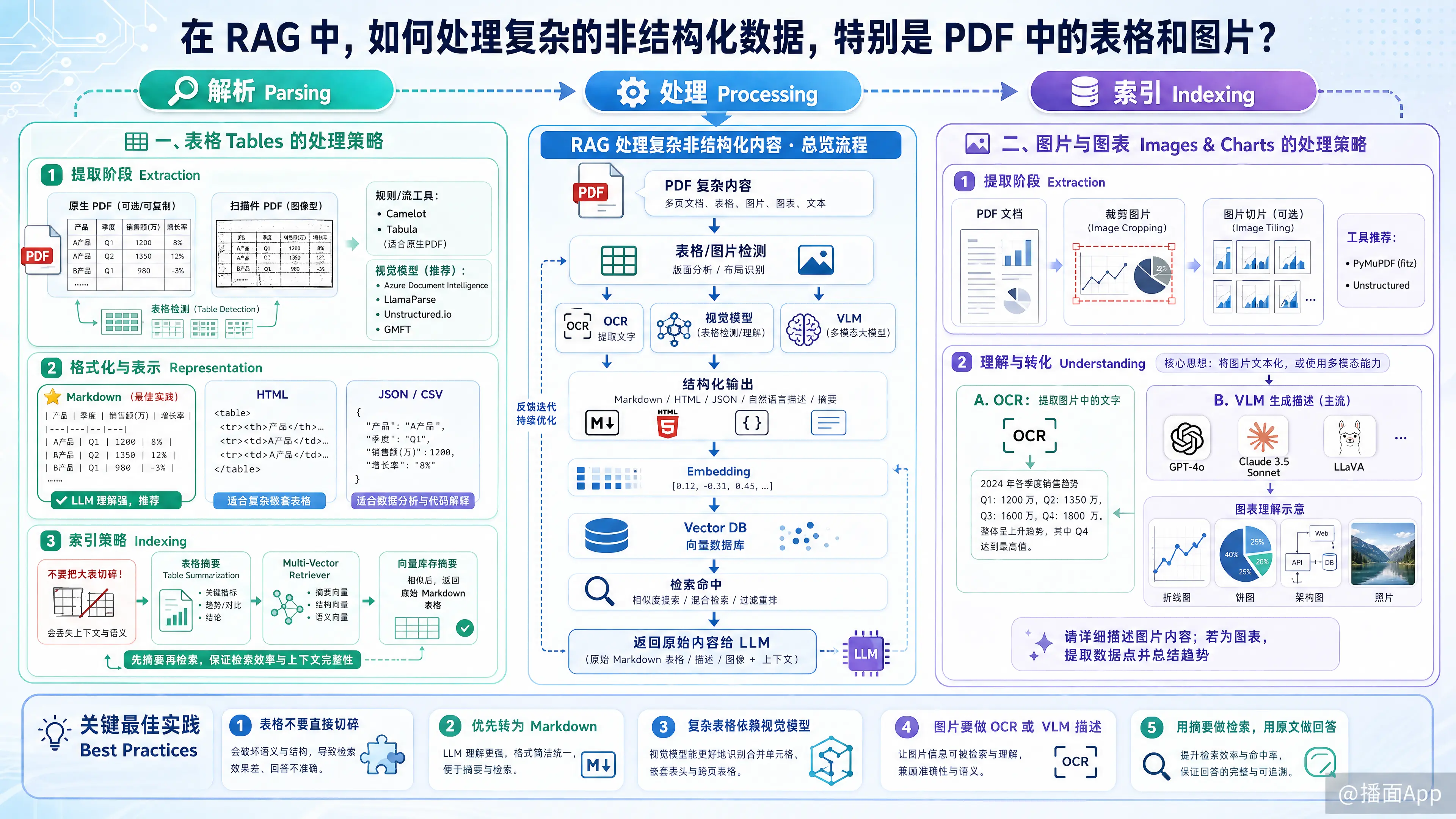
处理这些复杂的非结构化数据,通常需要一套“解析(Parsing) -> 处理(Processing) -> 索引(Indexing)”的组合策略。以下是目前业界最主流且有效的处理方案:
一、 表格(Tables)的处理策略
表格包含行、列和标题的二维关系,如果直接展平为一维文本,语义会完全丢失。
1. 提取阶段 (Extraction)
- 基于规则/流的工具:如果 PDF 是原生的(非扫描件),可以使用 Camelot 或 Tabula。它们利用 PDF 内部的线条坐标来重建表格。
- 基于视觉模型的工具(推荐):对于复杂表格(无边框、合并单元格)或扫描件,必须使用视觉模型。
- Microsoft Azure Document Intelligence (前 Form Recognizer):目前业界公认表格识别效果最好的商业 API。
- LlamaParse:LlamaIndex 推出的工具,专门针对 RAG 优化,能很好地将表格转换为 Markdown。
- Unstructured.io:开源界的瑞士军刀,结合了 OCR 和布局分析模型(如 YOLOX)来检测表格区域。
- GMFT (Grid Match Format Transformer): 最近比较火的轻量级表格提取库。
2. 格式化与表示 (Representation)
提取出来后,如何喂给 LLM 是关键:
- Markdown 格式(最佳实践):LLM 对 Markdown 表格的理解能力非常强。将提取的数据转换为
| Header | Header |格式。 - HTML 格式:对于极其复杂的嵌套表格,保留
<table>标签有时比 Markdown 更好。 - JSON/CSV:适合数据密集型表格,尤其是如果你打算让 LLM 写代码(Code Interpreter)来分析数据时。
3. 索引策略 (Indexing)
不要直接把大表格切碎进不同的 Chunk 里,那样会丢失上下文。
- 表格摘要(Table Summarization):提取表格后,单独发给 LLM 生成一段自然语言摘要(例如:“这张表展示了 2023 年 Q1-Q4 的营收增长...”)。
- 多向量检索(Multi-Vector Retriever):
- 对“表格摘要”进行 Embedding 并存入向量库。
- 当检索命中摘要时,返回原始的 Markdown 表格给 LLM,而不是返回摘要。
二、 图片与图表(Images & Charts)的处理策略
图片通常包含文本无法替代的信息(趋势线、架构图、照片)。
1. 提取阶段
- 使用 PyMuPDF (fitz) 或 Unstructured 将 PDF 中的图片对象裁剪并保存为单独的图像文件。
2. 理解与转化 (Understanding)
由于目前的向量数据库主要基于文本 Embedding,我们需要将图片“文本化”或使用多模态能力。
- 方案 A:OCR(光学字符识别)
- 仅提取图片中的文字。对于含有大量文字的截屏有效,但对于折线图、饼图,仅有文字是不够的。
- 方案 B:VLM 生成描述(Image Captioning - 主流方案)
- 利用多模态大模型(如 GPT-4o, Claude 3.5 Sonnet, LLaVA)对提取的图片进行分析。
- Prompt 示例:“请详细描述这张图片的内容。如果是图表,请提取所有数据点并总结趋势。”
- 将生成的文本描述用于 Embedding 和检索。
- 方案 C:多模态 Embedding (Multi-modal Embedding)
- 使用 CLIP 或 Google Multimodal Embedding 模型,直接将图片映射到向量空间。
- 用户可以用文本搜索图片,也可以用图片搜索图片。
3. 检索策略
与表格类似,建议使用多向量检索:
- 对“图片描述”做索引。
- 检索命中后,将原始图片(如果是支持多模态输入的 LLM)或详细文本描述(如果是纯文本 LLM)放入 Context Window。
三、 进阶架构模式(Advanced Patterns)
针对 PDF 这种混合排版文档,以下三种 RAG 架构最为有效:
1. "Small-to-Big" (Parent-Child Indexing)
- 原理:将文档切分成非常小的块(Child chunks)进行检索,但检索到后,返回其所属的更大的块(Parent chunk)甚至整页内容。
- 优势:表格或图片周围的文字通常是对它们的解释。这种方式能保证上下文完整。
2. 多向量检索器 (Multi-Vector / Summary Indexing)
- 这是处理混合数据的神器(LangChain 和 LlamaIndex 均支持)。
- 流程:
- 文本 -> 正常 Chunk -> Embedding。
- 表格 -> LLM 总结 -> 摘要 Embedding (指向原始表格)。
- 图片 -> VLM 描述 -> 描述 Embedding (指向原始图片)。
- 效果:搜索时匹配的是摘要/描述,生成时使用的是原始高保真数据。
3. ColPali / Visual RAG (最新趋势)
- 原理:不再进行繁琐的 OCR 和布局分析。直接将 PDF 的每一页截图,通过视觉语言模型(如 ColPali - 基于 PaliGemma)直接生成 Embedding。
- 流程:
- 用户提问 -> 模型直接在“页面图像”级别进行检索 -> 找到相关页面图片 -> 喂给 GPT-4o 等多模态模型回答。
- 优势:完全保留了排版、表格和图片的视觉语义,省去了清洗数据的巨大工程。
四、 推荐工具栈总结
| 任务 | 开源/免费工具 | 商业/付费工具 (效果更佳) |
|---|---|---|
| PDF 解析 | PyMuPDF, PyPDF2 | LlamaParse, Azure Doc Intelligence |
| 表格提取 | Camelot, Tabula, GMFT | LlamaParse, Azure, Textract |
| 文档拆解 | Unstructured.io (开源版) | Unstructured API |
| 图片理解 | LLaVA, Qwen-VL | GPT-4o, Claude 3.5 Sonnet, Gemini Pro Vision |
| 学术论文 | Nougat, Marker (基于视觉的转换) | - |
总结建议
- 如果预算允许:直接使用 LlamaParse 或 Azure Document Intelligence。它们能直接把 PDF 变成完美的 Markdown(包含表格),省去 80% 的工程时间。
- 如果必须开源:使用 Unstructured 库配合 YOLOX 做布局分析,把表格和图片切出来。
- 对于图片:务必使用 VLM (如 GPT-4o-mini) 生成详细描述,不要只靠 OCR。
- 存储结构:采用 多向量检索(Multi-Vector Retriever) 模式,将索引(摘要)与内容(原始数据)分离。
右滑查看面试常问