讲讲RAG 的基本工作流程(Index -> Retrieve -> Generate)
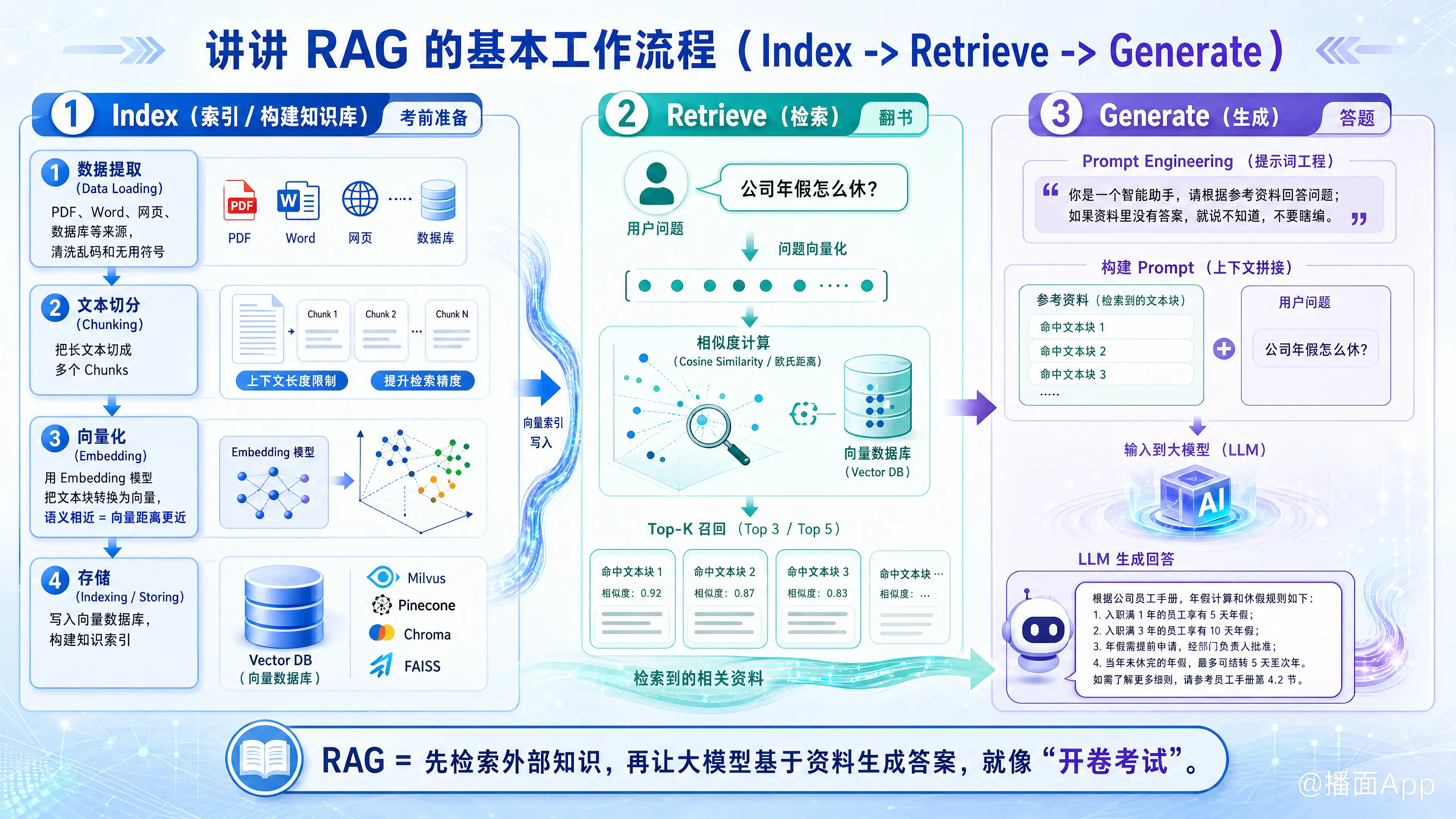
RAG(Retrieval-Augmented Generation,检索增强生成)是目前大语言模型(LLM)应用中最主流的架构。简单来说,它的核心思想是:“在大模型回答问题之前,先去外部知识库里找找答案,把找到的资料喂给大模型,让它参考着回答。”
这就像是一场“开卷考试”:大模型不再只靠死记硬背(训练数据)来回答,而是可以翻阅教科书(外部知识库)。
RAG 的标准工作流程主要分为三个阶段:Index(索引)、Retrieve(检索)和 Generate(生成)。下面我为你详细拆解这三个步骤:
第一阶段:Index(索引/构建知识库)
——这是“考前准备”阶段,目的是把资料整理好,方便查找。
这个阶段通常是离线进行的,主要包含以下几个动作:
- 数据提取(Data Loading):
- 从各种来源(PDF、Word、网页、数据库)获取原始文本数据。
- 清洗数据,去除乱码、无用符号等。
- 文本切分(Chunking):
- 为什么要切? 因为大模型有上下文长度限制(Context Window),而且如果把整本书丢进去,检索精度会下降。
- 怎么切? 将长文本切分成一个个小的“块”(Chunks)。比如按500个字切一块,或者按段落切分。
- 向量化(Embedding):
- 这是核心技术。 计算机不理解文字的含义,只理解数字。我们需要通过一个Embedding 模型(如 OpenAI text-embedding-3 或 HuggingFace 上的开源模型),把每一个文本块(Chunk)转换成一串长长的数字列表(向量/Vector)。
- 原理:语义相近的文本,在数学空间里的距离也更近。
- 存储(Indexing/Storing):
- 将这些“文本块”和对应的“向量”存入向量数据库(Vector Database,如 Milvus, Pinecone, Chroma, FAISS)。
- 这就建立了一个可以通过语义快速查找的索引库。
第二阶段:Retrieve(检索)
——这是“翻书”阶段,当用户提问时触发。
当用户提出一个问题(Query)时,系统会执行以下操作:
- 问题向量化:
- 使用和第一阶段完全相同的 Embedding 模型,把用户的“问题”也转换成一个向量。
- 相似度计算(Similarity Search):
- 拿着“问题向量”,去向量数据库里和之前存好的成千上万个“文档向量”进行比对。
- 通常使用余弦相似度(Cosine Similarity)或欧氏距离来计算。
- Top-K 召回:
- 找出在数学空间里距离最近(语义最相关)的 K 个文本块(比如前 3 个或前 5 个)。
- 例如:用户问“公司年假怎么休?”,系统找出了员工手册里关于“年假规定”的那几段话。
第三阶段:Generate(生成)
——这是“答题”阶段,大模型登场。
现在我们有了“用户的问题”和“检索到的参考资料(Context)”,接下来:
- 构建提示词(Prompt Engineering):
- 系统会在后台拼接一个特殊的 Prompt,通常长这样:
“你是一个智能助手。请根据以下【参考资料】来回答用户的【问题】。如果资料里没有答案,就说不知道,不要瞎编。
参考资料:
[检索到的文本块1]
[检索到的文本块2]
[检索到的文本块3]用户问题:
[用户的原始提问]”
- 系统会在后台拼接一个特殊的 Prompt,通常长这样:
- LLM 生成回答:
- 将这个填好内容的 Prompt 发送给大模型(如 GPT-4, Claude, Llama 3)。
- 输出结果:
- 大模型阅读参考资料,结合自己的语言能力,生成最终的自然语言答案返回给用户。
总结 RAG 的价值
通过 Index -> Retrieve -> Generate 这三步,RAG 完美解决了大模型的两大痛点:
- 幻觉问题(Hallucination): 强迫模型基于事实(参考资料)说话,减少胡编乱造。
- 知识时效性(Knowledge Cutoff): 大模型训练完知识就固定了,但通过 RAG,你可以随时往向量数据库里塞最新的新闻或公司内部文档,模型不需要重新训练就能回答最新问题。
右滑查看面试常问