Python 中的多线程(Threading)和多进程(Multiprocessing)有什么区别?
在 Python 中,threading(多线程)和 multiprocessing(多进程)是实现并发编程的两种主要方式。
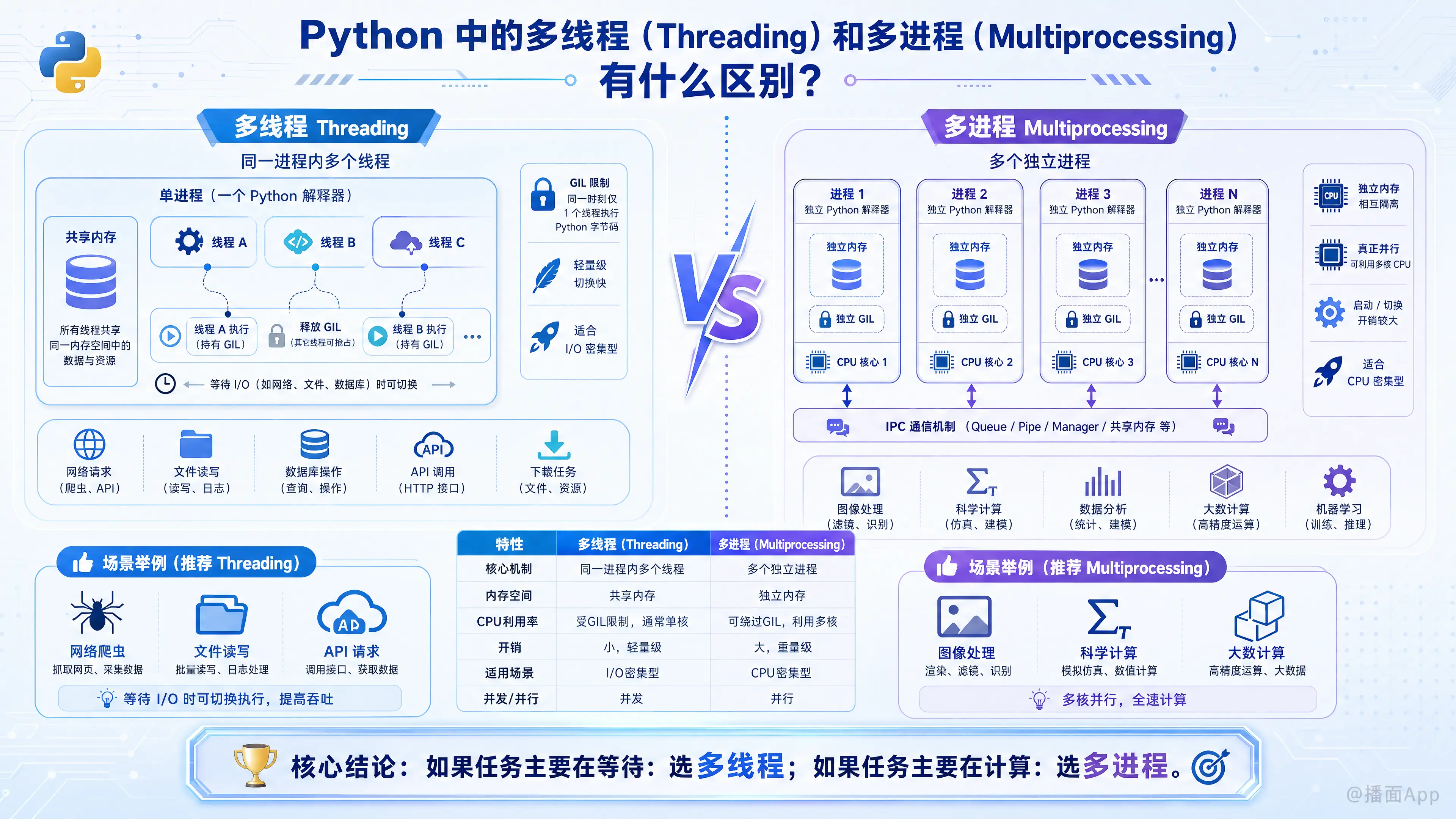
要理解它们的区别,核心在于理解 GIL(全局解释器锁,Global Interpreter Lock) 以及内存管理方式。
以下是详细的对比分析:
1. 核心区别总结表
| 特性 | 多线程 (Threading) | 多进程 (Multiprocessing) |
|---|---|---|
| 核心机制 | 在同一个进程内创建多个线程 | 创建多个独立的进程,每个进程有独立的 Python 解释器 |
| 内存空间 | 共享内存(访问全局变量容易,但需注意线程安全) | 独立内存(数据隔离,通信需通过 Queue/Pipe 等 IPC 机制) |
| CPU 利用率 | 受 GIL 限制,同一时刻只能利用 1个 CPU 核心 | 可以绕过 GIL,利用 多核 CPU 进行并行计算 |
| 开销 (Overhead) | 创建和切换开销小(轻量级) | 创建和切换开销大(重量级,需复制内存空间) |
| 适用场景 | I/O 密集型任务 (爬虫、文件读写、API 请求) | CPU 密集型任务 (科学计算、图像处理、数据分析) |
| 并发 vs 并行 | 并发 (Concurrency):看起来像同时做,实际是快速切换 | 并行 (Parallelism):真正的同时做 |
2. 深入解析
A. 多线程 (Threading) 与 GIL
在 CPython(Python 的标准解释器)中,存在一个 GIL(全局解释器锁)。这意味着在任何给定的时刻,只有一个线程可以在 CPU 上执行 Python 字节码。
- 工作原理:线程 A 执行一会儿 -> 释放 GIL -> 线程 B 抢到 GIL -> 线程 B 执行 -> ...
- 为什么适合 I/O 密集型?
当线程遇到 I/O 操作(如等待网络响应、读写硬盘)时,它会主动释放 GIL。此时 CPU 是空闲的,其他线程可以利用这段空闲时间继续工作。因此,虽然不能利用多核,但在处理大量等待任务时效率极高。 - 缺点:
- 无法利用多核 CPU 加速计算。
- 由于共享内存,多个线程同时修改同一数据时容易发生冲突(Race Condition),需要使用 Lock(锁)机制。
B. 多进程 (Multiprocessing)
multiprocessing 模块通过创建完全独立的子进程来工作。每个子进程都有自己独立的 Python 解释器实例和独立的 GIL。
- 工作原理:进程 A 在核心 1 上跑,进程 B 在核心 2 上跑。它们互不干扰。
- 为什么适合 CPU 密集型?
因为每个进程有自己的 GIL,它们可以同时在不同的 CPU 核心上全速运行,实现真正的并行计算。 - 缺点:
- 内存开销大:每个进程都需要一份独立的内存空间。
- 启动慢:创建进程比创建线程慢得多。
- 通信复杂:进程间数据不共享,必须使用
Queue、Pipe或Manager等机制来传递数据,这会带来额外的序列化(Pickling)开销。
3. 场景举例:该选哪一个?
场景一:网络爬虫 (I/O 密集型)
你需要从 100 个网站下载网页。
- 选择:
Threading - 原因:大部分时间程序都在等待服务器响应(I/O)。多线程可以在等待时切换去下载下一个,极大缩短总耗时。多进程在这里只会增加不必要的内存开销。
场景二:图像处理/大数计算 (CPU 密集型)
你需要将 1000 张高清图片转换为黑白,或者计算 1 亿以内的质数。
- 选择:
Multiprocessing - 原因:这是纯计算任务,CPU 一直在满负荷工作。如果用多线程,因为 GIL 的存在,实际上还是单核在跑,甚至因为线程切换的开销比单线程还慢。用多进程可以将任务分配给 4 核或 8 核 CPU 同时跑,速度提升显著。
4. 代码简单对比
多线程 (Threading):
python
import threading
import time
def task():
time.sleep(1) # 模拟 I/O 等待
print("Task finished")
# 创建线程
t1 = threading.Thread(target=task)
t2 = threading.Thread(target=task)
# 启动
t1.start()
t2.start()
# 等待结束
t1.join()
t2.join()多进程 (Multiprocessing):
python
import multiprocessing
import time
def task():
# 这里可以是繁重的计算
sum(i * i for i in range(10000000))
print("Task finished")
if __name__ == '__main__': # Windows 下必须加这行
# 创建进程
p1 = multiprocessing.Process(target=task)
p2 = multiprocessing.Process(target=task)
p1.start()
p2.start()
p1.join()
p2.join()总结 (一句话法则)
- 如果你在等(网络、磁盘),用 多线程 (Threading)。
- 如果你在算(CPU 计算),用 多进程 (Multiprocessing)。
右滑查看面试常问