什么是 Instruction Tuning(指令微调)?它与普通的微调有什么不同?
Instruction Tuning(指令微调) 是大语言模型(LLM)发展过程中一个非常关键的技术步骤,它是让 GPT-3 变成 ChatGPT 的核心技术之一。
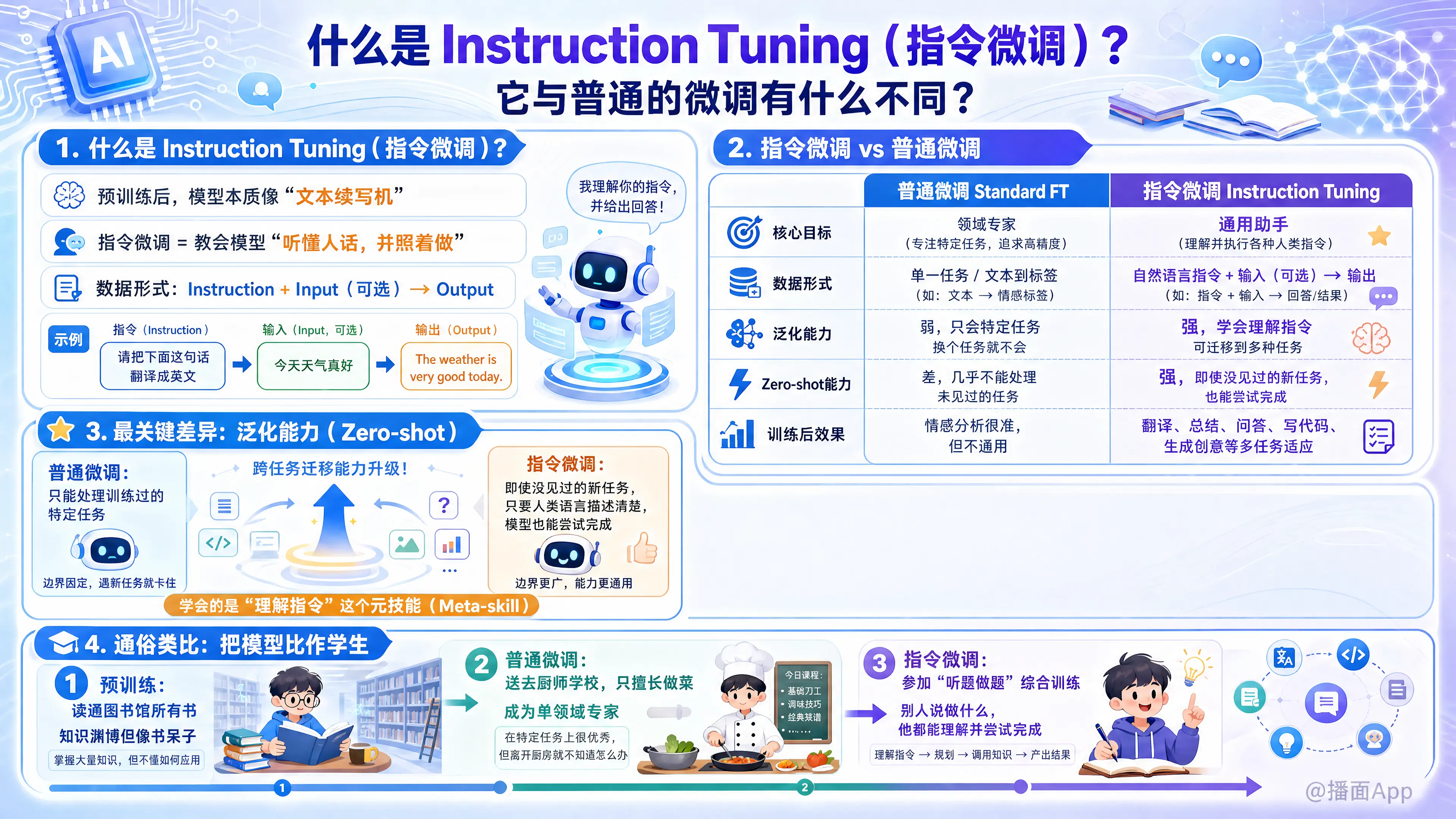
简单来说,指令微调就是教会模型“听懂人话”并“照着做”。
下面我将详细解释它的定义,并对比它与普通微调的区别。
1. 什么是 Instruction Tuning(指令微调)?
在大模型经过预训练(Pre-training)后,它虽然学到了海量的知识和语法,但它的本质仍然是一个“文本续写机”。
- 预训练模型的行为: 如果你问它“中国的首都是哪里?”,它可能不会回答“北京”,而是根据概率续写成:“...美国的首都是哪里?日本的首都是哪里?”(因为它见过很多类似的试题集)。
- 指令微调的目标: 改变这种行为,让模型理解“指令(Instruction)”的意图,并给出符合人类期望的“回复(Response)”。
它是怎么做的?
研究人员会准备大量的数据集,这些数据由 (指令, 输出) 对组成。
- 指令: “请把下面这句话翻译成英文。”
- 输入(可选): “今天天气真好。”
- 输出: “The weather is very good today.”
通过在多种多样的任务(翻译、总结、问答、写代码等)上进行这种训练,模型学会了“如何遵循指令”这一普遍规律。
2. 指令微调 vs. 普通微调(Standard Fine-tuning)
虽然它们都是“微调”(在预训练模型基础上继续训练),但目的和能力有本质区别。
我们可以通过以下几个维度来对比:
A. 核心目标不同
- 普通微调(Standard FT): 也就是传统的任务特定微调。
- 目标: 让模型成为某个领域的专家。
- 例子: 你想做一个“情感分析模型”,你就给模型喂几万条电影评论和标签(正面/负面)。训练完后,这个模型在判断情感上非常准,但它可能已经忘了怎么做翻译,或者怎么回答常识问题。
- 指令微调(Instruction Tuning):
- 目标: 让模型成为通用的助手,提升泛化能力。
- 例子: 你给模型喂翻译、摘要、逻辑推理等几百种不同的任务。训练完后,模型不仅会做这些,甚至当你给它一个它从未见过的任务(比如“写一首关于量子力学的诗”)时,它也能理解并尝试完成。
B. 数据形式不同
- 普通微调: 数据通常是单一特定格式的。
- 输入: 文本 -> 输出: 标签(Label)。
- 指令微调: 数据必须包含明确的自然语言指令。
- 格式:
Instruction(指令) +Input(上下文) ->Output(回答)。 - 重点在于指令的多样性(Phrasing),比如“翻译”、“Translate”、“用英文表达”等不同说法对应同一任务。
- 格式:
C. 泛化能力(Zero-shot 能力)—— 最关键的区别
- 普通微调: 泛化能力差。模型只能处理它训练过的那个特定任务。
- 指令微调: 泛化能力强。模型学会了“理解指令”这个元技能(Meta-skill)。这意味着,即使是训练集中没有的任务,只要你能用人类语言描述清楚指令,模型通常都能处理。这被称为 Zero-shot(零样本)学习能力。
3. 一个通俗的类比
为了方便理解,我们可以把大模型比作一个学生:
预训练(Pre-training):
- 学生在图书馆读了全世界所有的书。他知识渊博,但他是个书呆子。如果你对他说“西红柿炒蛋”,他可能会背诵西红柿的植物学定义,而不是去炒菜。
普通微调(Standard Fine-tuning):
- 你把这个学生送去厨师学校特训。他现在非常擅长做西红柿炒蛋,但他可能忘了怎么写文章,也不懂怎么修车。他变成了专才。
指令微调(Instruction Tuning):
- 你给这个学生请了一个管家导师。导师不教具体的菜谱,而是教他:“当别人用祈使句说话时,你要去执行动作”、“当别人问问题时,你要给答案”。
- 经过训练,你对他说“去把地扫了”(哪怕他没专门学过扫地课),他也能理解这是个命令,并调动他预训练时学到的关于扫帚的知识去完成任务。
总结
指令微调是连接“庞大的知识库”(预训练模型)和“有用的人工智能助手”(如 ChatGPT)之间的桥梁。
- 普通微调是为了做深(在特定任务上达到极致)。
- 指令微调是为了做广(让模型听懂各种命令,具备通用性)。
右滑查看面试常问