说说 Transform 的整体架构
Transformer 模型由 Google 团队在 2017 年的经典论文《Attention Is All You Need》中提出。它彻底抛弃了传统的循环神经网络(RNN)和卷积神经网络(CNN)结构,完全基于注意力机制(Attention Mechanism)来处理序列数据。
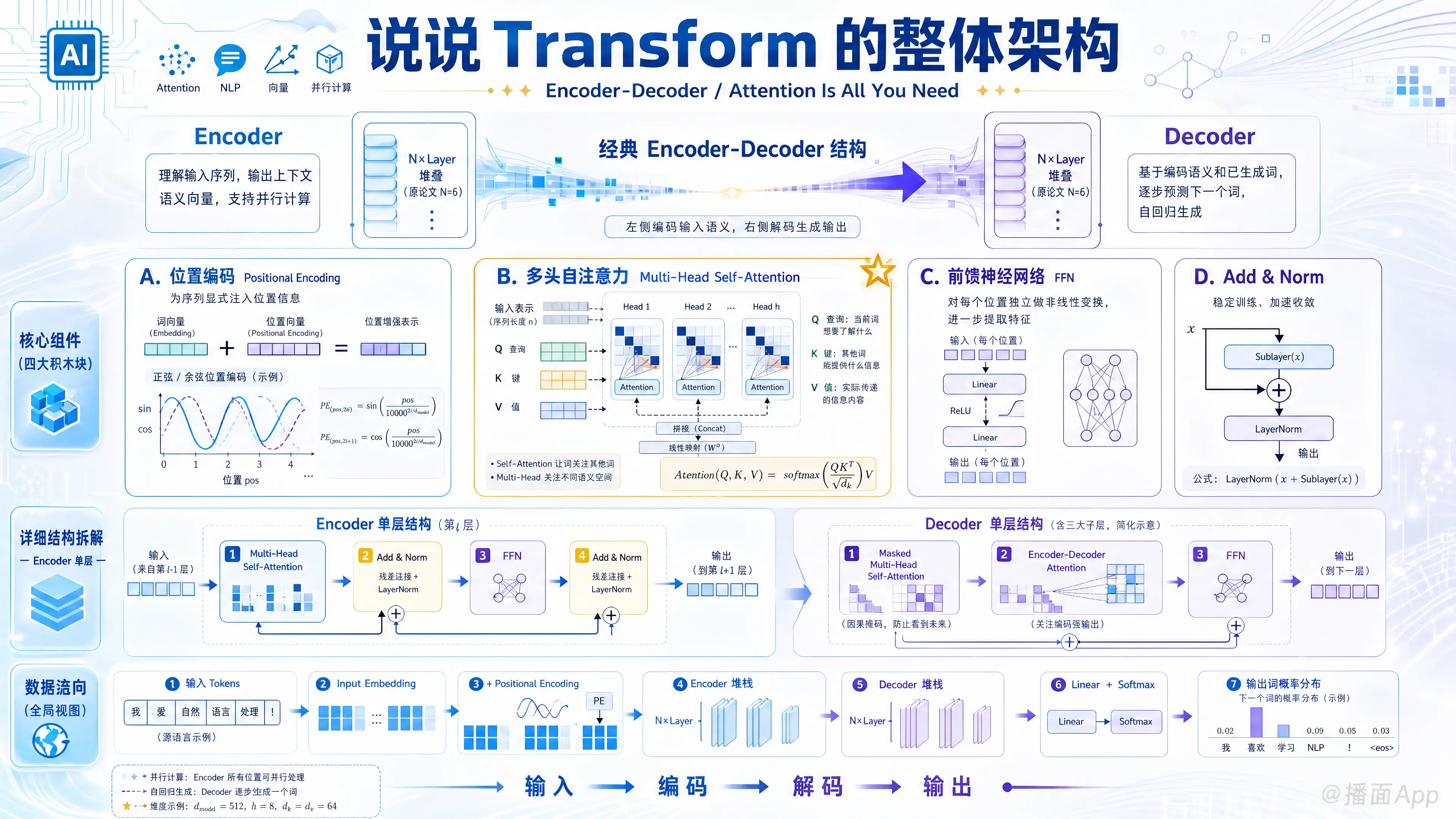
Transformer 的整体架构是一个经典的 Encoder-Decoder(编码器-解码器) 结构。
为了让你更清晰地理解,我们可以将其分为三个层面来剖析:宏观架构、核心组件以及数据流向。
1. 宏观架构 (The Big Picture)
从宏观上看,Transformer 由左右两部分组成:
- 左侧:Encoder(编码器)
- 作用:负责“理解”输入序列(例如一句话)。它将输入转换成一组包含丰富语义信息的向量(Context Vector)。
- 特点:并行计算,一次性通过所有输入。
- 右侧:Decoder(解码器)
- 作用:负责“生成”输出序列。它根据 Encoder 提供的语义信息以及之前已经生成的词,逐个预测下一个词。
- 特点:自回归(Autoregressive),即上一步的输出是下一步的输入。
两者都由 N 个相同的层(Layer)堆叠而成(原论文中 N=6)。
2. 内部核心组件 (The Components)
要理解 Transformer,必须理解构成它的几个积木块:
A. 位置编码 (Positional Encoding)
由于 Transformer 没有 RNN 那样的循环结构,它本身不知道“第一个词”和“第二个词”的顺序。因此,必须显式地将位置信息注入到输入向量中。
- 做法:将词向量(Input Embedding)与位置向量相加。
- 原理:通常使用正弦和余弦函数生成。
B. 多头自注意力机制 (Multi-Head Self-Attention)
这是 Transformer 的灵魂。
- Self-Attention (自注意力):让模型在处理某个词时,能同时关注句子中的其他词。例如处理 "it" 时,模型能通过注意力机制知道它指代前面的 "animal"。
- 核心公式:
- Q (Query):查询向量(我在找什么?)
- K (Key):键向量(我是什么标签?)
- V (Value):值向量(我的实际内容是什么?)
- Multi-Head (多头):相当于把注意力机制复制多份(比如 8 份)。每一份(Head)关注不同的语义空间(有的关注语法结构,有的关注指代关系),最后拼接起来。这极大地增强了模型的表达能力。
C. 前馈神经网络 (Position-wise Feed-Forward Networks, FFN)
在每个注意力层之后,都有一个全连接网络。它对每个位置的向量独立进行非线性变换(通常是两层线性变换中间加一个 ReLU 激活函数),用于进一步提取特征。
D. 残差连接与层归一化 (Add & Norm)
在每个子层(Attention 和 FFN)的输出端,都使用了:
- Residual Connection (残差连接):,防止深层网络梯度消失,让训练更稳定。
- Layer Normalization (层归一化):对每一层的数据进行归一化,加速收敛。
3. 详细结构拆解
编码器 (Encoder) - 左侧
Encoder 由 N 个堆叠的层组成,每一层包含两个子层:
- Multi-Head Self-Attention:让序列中的每个词都能看到所有其他词,建立全局依赖。
- Feed-Forward Network:处理特征。
- 数据流:Input Embedding + Positional Encoding Layer 1 ... Layer N Output (Context Matrix)。
解码器 (Decoder) - 右侧
Decoder 也由 N 个堆叠的层组成,但每一层包含三个子层(比 Encoder 多了一个):
- Masked Multi-Head Self-Attention (带掩码的自注意力):
- 关键点:这里加了 Mask(掩码)。因为在预测第 个词时,模型不能看到 之后的词(不能作弊)。Mask 将未来的位置设为负无穷,使其 Softmax 概率为 0。
- Encoder-Decoder Attention (交叉注意力):
- 关键点:这是连接 Encoder 和 Decoder 的桥梁。
- Q 来自 Decoder 上一层的输出(我在生成什么?)。
- K, V 来自 Encoder 的最终输出(原文说了什么?)。
- 这让解码器在生成每个词时,都能回头去“看”原文中最相关的部分。
- Feed-Forward Network:同 Encoder。
4. 整体工作流程 (Workflow Summary)
假设我们要将中文 "我爱你" 翻译成英文 "I love you":
- 输入处理:"我爱你" 被转化为 Embedding 并加上位置编码。
- Encoder 运行:数据流经 6 层 Encoder,每一层都通过自注意力机制理解词与词的关系。最终输出一个包含整句话深层语义的矩阵(K 和 V)。
- Decoder 开始生成:
- Step 1:输入
<Start>标记。 - Masked Attention:只能看到
<Start>。 - Cross Attention:拿着
<Start>的向量去查 Encoder 的输出(K, V),关注到 "我" 这个词。 - 输出:经过 Linear 和 Softmax,预测出概率最高的词 "I"。
- Step 2:输入
<Start> I。 - Masked Attention:只能看到
<Start>和I。 - Cross Attention:结合上下文去查 Encoder,关注到 "爱"。
- 输出:预测出 "love"。
- ...以此类推,直到生成
<End>标记。
- Step 1:输入
5. 总结与演变
Transformer 的架构之所以伟大,在于它实现了:
- 并行计算:Encoder 阶段可以并行处理整个句子,训练速度远超 RNN。
- 长距离依赖:无论句子多长,任意两个词之间的距离都是 1(通过 Attention 直接相连),解决了长序列遗忘问题。
后续演变(大模型的基石):
- Encoder-only (如 BERT):只用左半边。擅长“理解”任务(分类、情感分析)。
- Decoder-only (如 GPT 系列):只用右半边(去掉交叉注意力,改为纯自回归)。擅长“生成”任务。
- Encoder-Decoder (如 T5, BART):保持原样。擅长翻译、文本摘要。
右滑查看面试常问