Kafka消息发送失败的重试机制是怎样的?
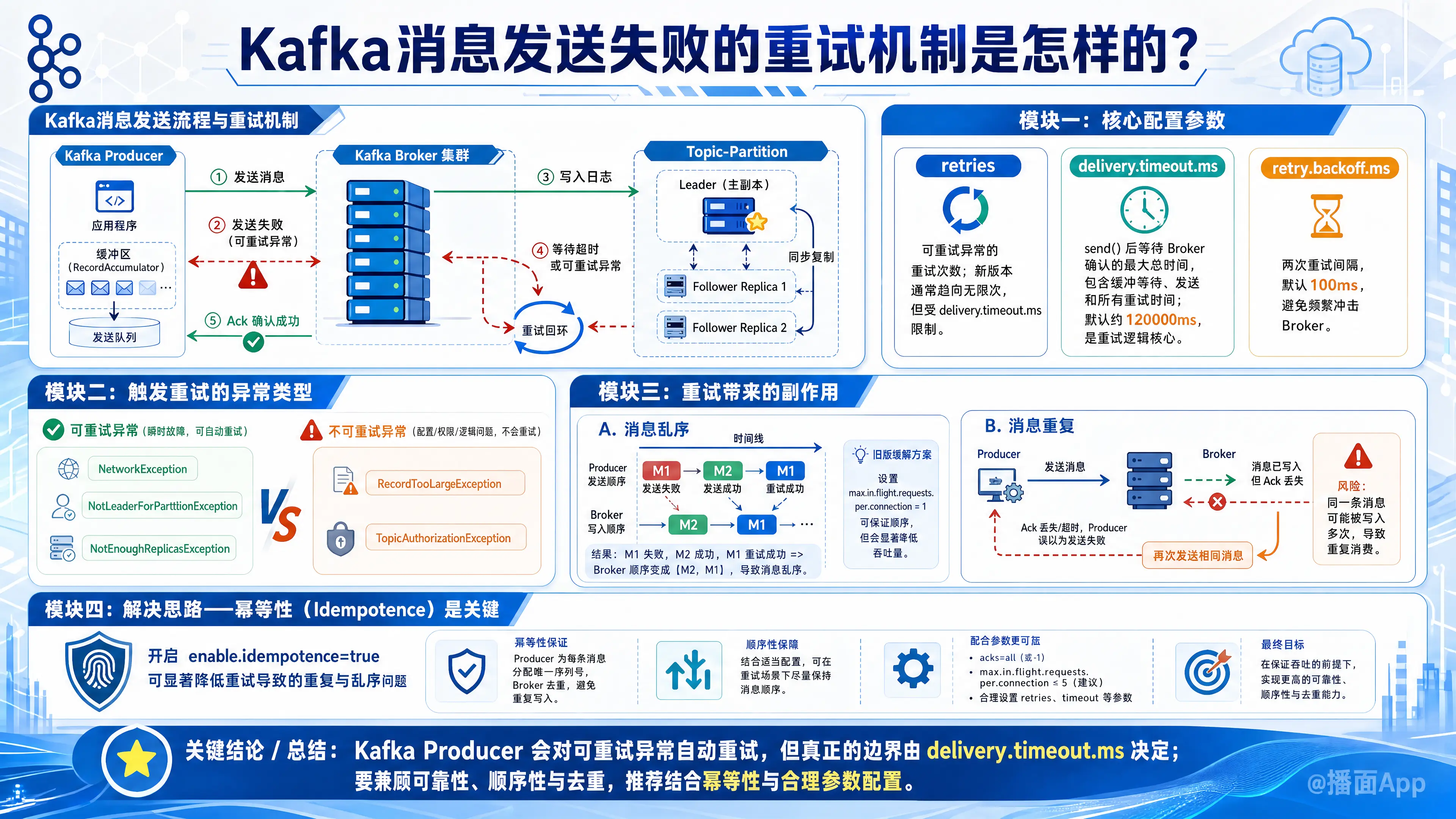
Kafka 消息发送失败的重试机制主要发生在 Producer(生产者) 端。当生产者将消息发送给 Broker 时,可能会因为网络抖动、Leader 选举等瞬时故障导致发送失败。Kafka 提供了内置的自动重试机制来保证消息的高可用性和可靠性。
以下是 Kafka 生产者重试机制的详细解析:
1. 核心配置参数
Kafka 生产者的重试行为主要由以下几个参数控制:
retries(重试次数)- 含义:决定了生产者在抛出致命异常之前,针对可重试异常(Transient Exceptions)尝试重新发送消息的次数。
- 默认值:在较新的版本(2.1+)中,默认值通常是
Integer.MAX_VALUE(即无限次),而不是以前的 0。 - 注意:虽然设置为无限次,但它受限于
delivery.timeout.ms。
delivery.timeout.ms(投递超时时间)- 含义:这是现代 Kafka 生产者控制重试逻辑的核心参数。它表示调用
send()方法后,生产者等待 Broker 确认(Ack)的最大总时间。 - 机制:这个时间包含了:消息在缓冲区等待的时间 + 发送请求的时间 + 所有重试的时间。
- 默认值:通常为 120000ms (2分钟)。
- 逻辑:如果在这个时间内消息没有发送成功(无论重试了多少次),生产者就会放弃并回调异常。
- 含义:这是现代 Kafka 生产者控制重试逻辑的核心参数。它表示调用
retry.backoff.ms(重试间隔)- 含义:两次重试之间等待的时间。
- 默认值:100ms。
- 作用:避免在故障发生时立即频繁请求打垮 Broker,给集群一定的恢复时间。
2. 哪些异常会触发重试?
并不是所有的发送失败都会触发重试。Kafka 将异常分为两类:
可重试异常 (Retriable Exceptions):
- 这类异常通常是瞬时的,过一会可能就会自动恢复。
- 例子:
NetworkException(网络连接中断)NotLeaderForPartitionException(Partition 的 Leader 正在选举中或发生了变更)NotEnoughReplicasException(ISR 副本数不足)
- 行为:生产者会自动触发重试机制。
不可重试异常 (Non-Retriable Exceptions):
- 这类异常通常是配置错误或逻辑错误,重试无法解决。
- 例子:
RecordTooLargeException(消息体积超过了 Broker 限制)TopicAuthorizationException(没有权限)
- 行为:生产者直接抛出异常,不会重试。
3. 重试带来的副作用及解决方案
开启重试虽然提高了可靠性,但如果不加配置,会带来两个严重问题:消息乱序和消息重复。
A. 消息乱序 (Out of Ordering)
- 场景:生产者发送消息 M1 失败,紧接着发送消息 M2 成功。此时 M1 触发重试并成功。
- 结果:Broker 保存的顺序变成了 M2, M1。
- 旧版解决方案:设置
max.in.flight.requests.per.connection = 1。这意味着在收到当前请求的响应之前,不允许发送下一个请求,从而保证顺序。但这会严重降低吞吐量。
B. 消息重复 (Duplication)
- 场景:生产者发送 M1,Broker 写入成功,但在返回 Ack 时网络断了。生产者认为发送失败,重试发送 M1。
- 结果:Broker 里存了两条 M1。
C. 终极解决方案:幂等性生产者 (Idempotent Producer)
从 Kafka 0.11 开始,引入了幂等性配置,这是目前的最佳实践。
- 配置:
enable.idempotence = true - 原理:生产者在初始化时会被分配一个 Producer ID (PID),每条消息会被分配一个序列号 (Sequence Number)。Broker 会利用 (PID + Sequence Number) 来去重。
- 效果:
- 即使重试,Broker 也能保证消息不重复。
- 即使
max.in.flight.requests.per.connection > 1(默认是 5),Kafka 也能通过序列号保证有序性。
- 默认情况:在 Kafka 3.0+ 的 Java 客户端中,默认为
true。
4. 重试流程总结
当调用 producer.send(record) 时:
- 消息进入生产者的累加器(RecordAccumulator)。
- Sender 线程尝试发送 Batch。
- 如果发送失败:
- 检查异常是否为
RetriableException。 - 检查当前已用时间是否超过
delivery.timeout.ms。 - 检查重试次数是否超过
retries(如果未设置超时)。
- 检查异常是否为
- 满足重试条件:
- 等待
retry.backoff.ms时间。 - 重新将消息加入发送队列。
- 如果是幂等生产者,序列号保持不变。
- 等待
- 不满足重试条件(超时或不可重试异常):
- 触发 Callback,返回异常信息给用户代码。
5. 最佳实践建议
- 不要禁用重试:除非你不在乎数据丢失。
- 使用
delivery.timeout.ms控制:不要纠结于retries的具体数字,设置一个合理的总超时时间(如 2 分钟)让 Kafka 自己去尽力重试。 - 开启幂等性 (
enable.idempotence = true):这是保证数据不丢失、不重复、且有序的最简单方法。 - 应用层兜底:如果 Kafka 内部重试彻底失败(回调中收到异常),业务代码需要捕获这个异常,将消息记录到数据库或死信队列(DLQ),以便人工处理。
右滑查看面试常问