讲一下 RocketMQ 的整体架构流程(从生产者发送到消费者消费)
本文解析RocketMQ架构四大组件,详解消息从发送、CommitLog存储到长轮询消费的全链路流程。
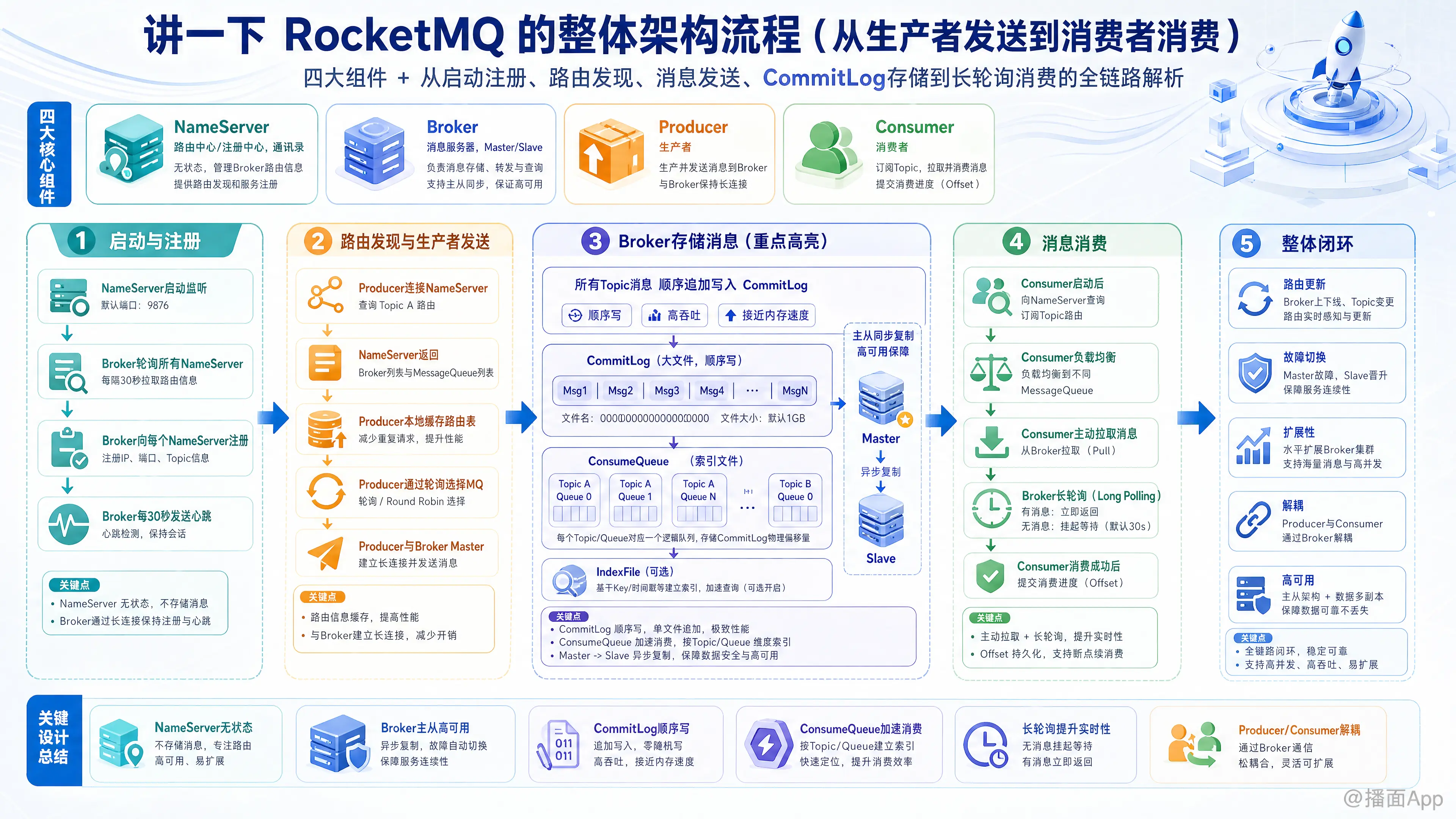
RocketMQ 的整体架构和消息流转流程是一个经典的高并发、分布式系统设计案例。为了让你清晰理解,我将从四大核心组件入手,然后详细梳理从启动到消费的全链路流程。
一、 RocketMQ 的四大核心组件
在讲流程之前,必须先认识四个“角色”:
NameServer(路由中心):
- 角色:相当于“通讯录”或“注册中心”。
- 特点:无状态节点,节点之间互不通信(Share-nothing)。
- 作用:Broker 启动时向它注册,生产者和消费者向它查询 Broker 的地址。
Broker(消息服务器):
- 角色:核心“搬运工”和“仓库”。
- 作用:接收消息、存储消息、投递消息。它处理消息的持久化(写入磁盘)和高可用(主从同步)。
- 结构:分为 Master(主)和 Slave(从)。
Producer(生产者):
- 角色:发信人。
- 作用:产生业务消息并发送给 Broker。
Consumer(消费者):
- 角色:收信人。
- 作用:从 Broker 拉取消息并进行业务消费。
二、 全链路流程详解(从发送到消费)
整个流程可以分为五个阶段:启动注册、路由发现、消息发送、消息存储、消息消费。
第一阶段:启动与注册 (Startup & Registration)
在任何消息发送之前,系统必须先组网。
- NameServer 启动:监听端口,等待 Broker 注册。
- 注意:NameServer 之间互不通信,互不感知。
- Broker 启动:
- Broker 启动后,会轮询所有的 NameServer 节点。
- Broker 向每个 NameServer 建立长连接,注册自己的 IP、端口以及自己负责的 Topic(主题) 信息。
- Broker 此后每隔 30秒 发送一次心跳,告诉 NameServer “我还活着”。
第二阶段:生产者发送消息 (Producer Sending)
假设生产者要发送一条消息到 Topic A。
- 获取路由信息:
- Producer 启动时或发送消息时,先连接 NameServer。
- 询问:“谁负责 Topic A?”
- NameServer 返回 Topic A 对应的 Broker 列表(包含 Broker 地址和 MessageQueue 列表)。
- Producer 会在本地缓存这份路由表。
- 选择队列 (Load Balancing):
- 一个 Topic 通常包含多个 MessageQueue (消息队列),分布在不同的 Broker 上。
- Producer 通过负载均衡算法(默认是轮询 Round Robin,也可以是 Hash 取模等)选择其中一个 MessageQueue。
- 发送消息:
- Producer 与选定的 Broker(Master 节点)建立长连接。
- 将消息发送给 Broker。
第三阶段:Broker 存储消息 (Storage - 核心机制)
这是 RocketMQ 高性能的关键。
- 写入 CommitLog(顺序写):
- Broker 收到消息后,不直接按 Topic 分类存储。
- 而是将所有 Topic 的消息,都顺序追加写入到一个巨大的文件叫
CommitLog中。 - 优势:磁盘顺序写速度极快,接近内存速度,这是 RocketMQ 高吞吐的根本。
- 构建 ConsumerQueue(异步构建索引):
- 虽然消息存进了 CommitLog,但消费者怎么读?不能遍历几百 GB 的文件吧。
- Broker 有一个后台线程(ReputMessageService),不断扫描 CommitLog。
- 它将消息的 物理偏移量(Offset)、大小、Tag Hash 提取出来,写入到对应 Topic 的
ConsumerQueue文件中。 ConsumerQueue可以看作是索引文件,类似于字典的目录。
- 主从同步 (HA):
- 如果配置了 Slave,Master 会将数据同步给 Slave(可以是同步双写,也可以是异步复制)。
第四阶段:消费者消费消息 (Consumer Consumption)
消费者准备处理 Topic A 的消息。
- 获取路由与重平衡 (Rebalance):
- Consumer 连接 NameServer,获取 Topic A 的路由信息。
- Rebalance:同一个消费者组(Consumer Group)里的多个消费者会分配 Topic 下的 MessageQueue。例如:4个队列,2个消费者,那么每个消费者分到 2 个队列。
- 拉取消息 (Pull Mechanism):
- RocketMQ 的消费本质上都是 Pull(拉) 模式。
- 即使是 PushConsumer,底层也是通过长轮询 (Long Polling) 实现的:Consumer 发送拉取请求,如果 Broker 有新消息立刻返回;如果没有,Broker 会挂起请求(默认最多 15秒),一旦有新消息到达立刻唤醒返回。
- 读取流程:
- Consumer 向 Broker 请求:“我要读 Topic A,Queue 1,Offset 为 100 的消息”。
- Broker 查找
ConsumerQueue,找到 Offset 100 对应的物理位置。 - Broker 根据物理位置去
CommitLog读取真正的消息内容。 - Broker 将消息返回给 Consumer。
第五阶段:消费确认 (ACK)
- 业务处理:Consumer 收到消息后,执行具体的业务逻辑(如扣减库存、发送短信)。
- 发送 ACK:
- 业务处理成功,Consumer 返回
CONSUME_SUCCESS给 Broker。 - Broker 更新该 Consumer Group 在该 MessageQueue 上的消费进度(Offset),并持久化。
- 业务处理成功,Consumer 返回
- 重试机制:
- 如果 Consumer 业务处理失败或超时,Broker 会将消息重新发回 Broker 的重试队列(
%RETRY%),等待延时后再次投递。
- 如果 Consumer 业务处理失败或超时,Broker 会将消息重新发回 Broker 的重试队列(
三、 总结流程图(文字版)
plaintext
[NameServer] <----(1. Register)---- [Broker Master/Slave]
^ ^
| (2. Lookup Route) | (3. Send Msg)
| |
[Producer] -----------------------------> [Broker]
|
+---> [CommitLog] (Data)
+---> [ConsumerQueue] (Index)
|
| (4. Lookup Route) | (5. Pull Msg & ACK)
v v
[Consumer] <--------------------------- [Broker]四、 关键点总结(面试/理解重点)
- 读写分离的假象:RocketMQ 的写是全顺序写(CommitLog),读是随机读(通过 ConsumerQueue 索引跳读)。但利用操作系统的 PageCache 和 零拷贝 (mmap) 技术,读取性能依然非常高。
- NameServer 的无状态:NameServer 之间不通信,这使得它非常轻量且高可用,但也意味着 Broker 必须向所有 NameServer 注册。
- 推拉结合:Consumer 表面是 Push,实际底层是长轮询 Pull。这既保证了实时性,又避免了 Consumer 被 Broker 的海量消息压垮。
- 消息堆积能力:因为数据存储在磁盘(CommitLog)而非内存,RocketMQ 拥有极强的消息堆积能力(亿级)。
右滑查看面试常问