MySQL 什么情况下索引会失效?
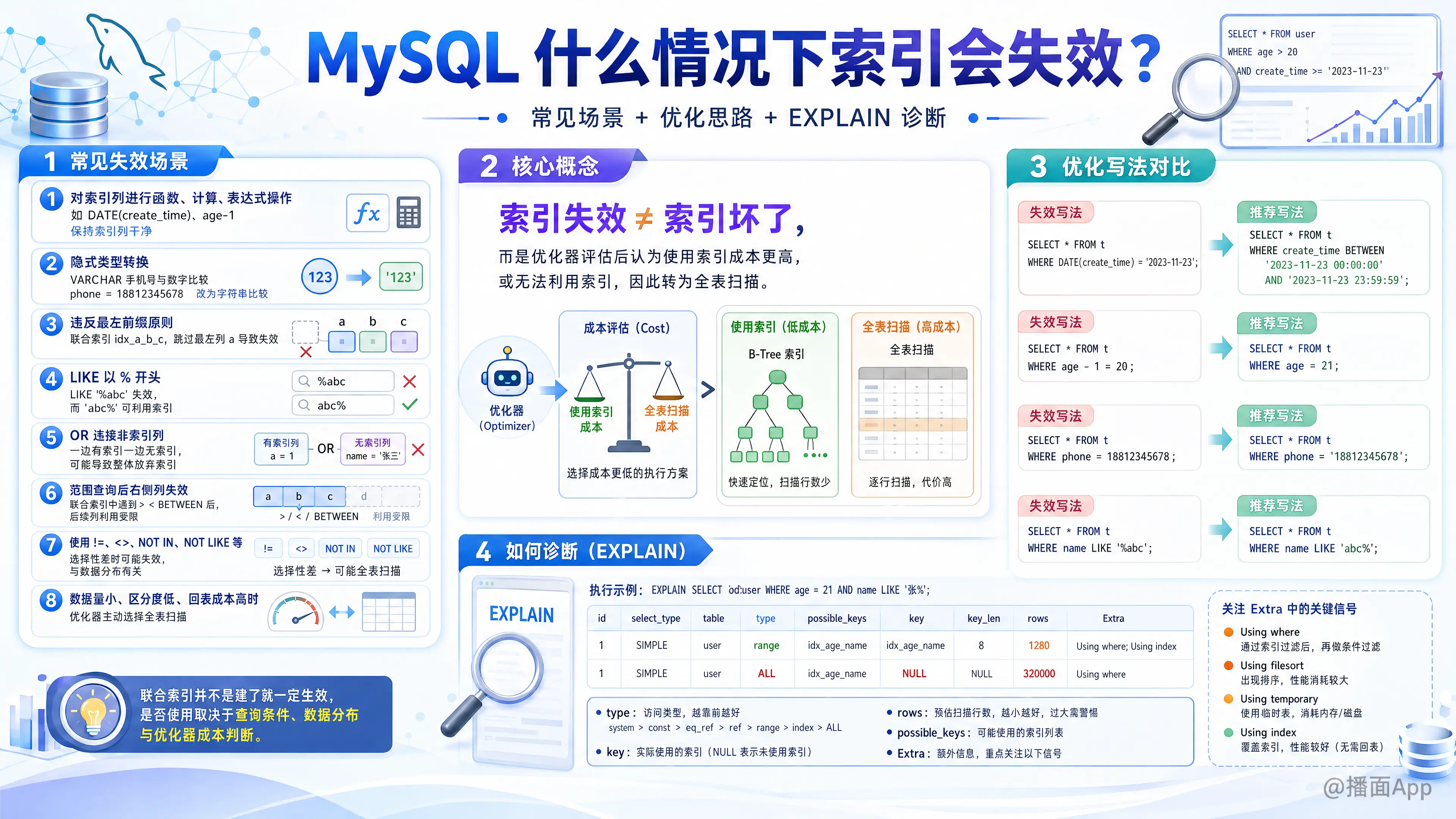
总结MySQL索引失效的常见场景:对索引列计算、违反最左原则、LIKE以%开头、OR连接非索引列等,并介绍如何用
EXPLAIN诊断。
这是一个非常经典且重要的 MySQL 面试和实战问题。
首先要明确一个核心概念:索引失效并非指索引本身坏了或消失了,而是指 MySQL 的优化器(Optimizer)在执行某条 SQL 语句时,经过评估后认为使用索引的成本(Cost)比全表扫描更高,或者根本无法使用索引,于是放弃使用索引,转而执行全表扫描。
下面我将详细列举导致 MySQL 索引失效的各种常见情况,并附上示例和解释。
1. 对索引列进行计算、函数操作或类型转换(最常见)
这是导致索引失效最主要的原因。因为索引保存的是原始列的值,如果对列进行了任何操作,索引中的值就无法直接匹配了,MySQL 无法“反向推算”出索引值。
原理: B-Tree 索引的查找效率依赖于其有序性。对索引列进行函数操作或计算,会破坏这种有序性,使得无法通过 B-Tree 快速定位数据。
示例:
假设 users 表在 create_time 列上有索引。
使用函数:
sql-- 失效:对索引列使用了函数 DATE() SELECT * FROM users WHERE DATE(create_time) = '2023-11-23'; -- 优化:将函数应用在常量上,保持索引列“干净” SELECT * FROM users WHERE create_time >= '2023-11-23 00:00:00' AND create_time <= '2023-11-23 23:59:59';进行计算:
sql-- 失效:对索引列 age 进行了计算 SELECT * FROM users WHERE age - 1 = 20; -- 优化:将计算移到常量一侧 SELECT * FROM users WHERE age = 21;隐式类型转换:
假设phone字段是VARCHAR类型并建有索引。sql-- 失效:MySQL会将字符串类型的 phone 字段隐式转换为数字进行比较,相当于对每一行的 phone 都用了 CAST(phone AS SIGNED) 函数 SELECT * FROM users WHERE phone = 18812345678; -- 优化:保持类型一致,使用字符串 SELECT * FROM users WHERE phone = '18812345678';
2. 违反最左前缀原则(针对联合索引)
当创建一个联合索引(Composite Index),例如 INDEX idx_a_b_c (a, b, c),查询时必须遵循“最左前缀原则”。
原理: 联合索引在 B-Tree 中是按照索引定义中列的顺序进行排序的。首先按 a 排序,a 相同时再按 b 排序,以此类推。如果查询条件没有从索引的最左边列开始,就无法利用这个有序结构。
示例:
对于索引 idx_a_b_c (a, b, c):
有效的查询:
sql-- 都使用索引 SELECT * FROM table WHERE a = 1; SELECT * FROM table WHERE a = 1 AND b = 2; SELECT * FROM table WHERE a = 1 AND b = 2 AND c = 3; -- a 和 b 用了索引,c 没有 SELECT * FROM table WHERE a = 1 AND c = 3;失效的查询:
sql-- 跳过了最左边的 a,索引完全失效 SELECT * FROM table WHERE b = 2; SELECT * FROM table WHERE c = 3; SELECT * FROM table WHERE b = 2 AND c = 3;
3. LIKE 查询以通配符 % 开头
原理: B-Tree 索引的有序性是从左到右的。如果查询条件以通配符开头,MySQL 不知道从哪里开始查找,只能放弃索引进行全表扫描。
示例:
假设 name 字段有索引。
-- 失效:以 '%' 开头
SELECT * FROM users WHERE name LIKE '%John';
-- 有效:不以 '%' 开头,索引依然可以用于定位到 'John' 开头的所有记录
SELECT * FROM users WHERE name LIKE 'John%';补充: 如果确实需要进行后缀或中缀匹配,可以考虑使用全文索引(Full-Text Index)或者其他技术如 Elasticsearch。
4. 使用 OR 连接条件,其中一方没有索引
原理: MySQL 优化器会认为,既然 OR 的一部分条件无法使用索引(需要全表扫描),那么为了合并两次查询(一次索引查询,一次全表扫描)的结果,还不如直接进行一次全表扫描来得简单高效。
示例:
假设 age 有索引,email 没有索引。
-- 失效:因为 email 列没有索引
SELECT * FROM users WHERE age = 25 OR email = 'test@example.com';注意: 如果 OR 两边的条件列都有独立的索引,在某些版本的 MySQL 中,优化器可能会使用 index_merge 技术,即分别使用两个索引查询,然后合并结果。但这通常效率不高。最好的做法是确保查询条件都能命中同一个索引。
5. 使用 != 或 <> (不等于)
原理: 不等于操作符通常无法有效利用索引的 B-Tree 结构,因为它们需要扫描大部分数据。优化器认为全表扫描可能更快。
示例:
假设 status 列有索引。
-- 索引可能失效
SELECT * FROM users WHERE status != 1;注意: 这不是绝对的。如果 status != 1 筛选掉的数据非常多(即 status = 1 的数据占绝大多数),优化器评估后也可能会使用索引。这取决于数据的分布(统计信息)。
6. 数据量小或索引选择性(Selectivity)差
原理: 当 MySQL 优化器评估发现,通过索引查找数据后再回表(根据索引找到主键,再根据主键找数据行)的成本,比直接扫描全表的成本还要高时,它会放弃使用索引。
- 表数据量太小: 比如表里只有几百行数据,直接全表扫描非常快,没必要走索引。
- 索引选择性差: 索引列的唯一值很少。例如,
gender列(性别)只有 '男', '女', '未知' 三个值。如果你查询WHERE gender = '男',这个条件会匹配表中约一半的数据。此时优化器会认为直接扫描全表更划算。
7. IS NULL 通常能用索引,IS NOT NULL 较难
WHERE column IS NULL:通常可以使用索引。WHERE column IS NOT NULL:和!=类似,因为它通常会返回大量数据,优化器可能会放弃索引。
这同样取决于数据的分布情况。
总结与排查方法
| 失效场景 | 解释 | 优化建议 |
|---|---|---|
| 对索引列用函数/计算 | 破坏了索引的有序性 | 将计算和函数移到查询条件右侧 |
| 隐式类型转换 | 相当于对列使用了转换函数 | 确保查询值与列类型一致 |
| 违反最左前缀原则 | 联合索引查询未从最左列开始 | 调整 WHERE 子句顺序或重建索引 |
LIKE 以 % 开头 |
无法定位 B-Tree 的起始点 | 避免前缀模糊查询,或使用全文索引 |
OR 连接非索引列 |
优化器认为全表扫描更优 | 确保 OR 两侧的列都有索引 |
使用 != 或 <> |
范围太大,选择性差 | 尽量使用 =、>、<、IN 等 |
| 索引选择性差 | 命中数据占比过高,回表成本大 | 考虑不建索引或选择选择性更好的列建索引 |
最重要的工具:EXPLAIN
如何确定你的 SQL 查询是否使用了索引?答案是使用 EXPLAIN 命令。
EXPLAIN SELECT * FROM users WHERE age = 25;在 EXPLAIN 的输出结果中,重点关注以下几列:
type:连接类型。index、range、ref、eq_ref、const都表示用到了索引。如果是ALL,则表示是全表扫描,索引失效。key:实际使用的索引名称。如果是NULL,则表示没有使用索引。possible_keys:可能使用的索引。Extra:额外信息。如果出现Using filesort或Using temporary,说明查询性能有待优化。如果出现Using index,则表示使用了覆盖索引(性能很好)。
通过分析 EXPLAIN 的结果,你可以准确地诊断出索引失效的原因,并进行针对性的优化。