自增主键(AUTO_INCREMENT)和UUID作为主键各有什么优缺点?
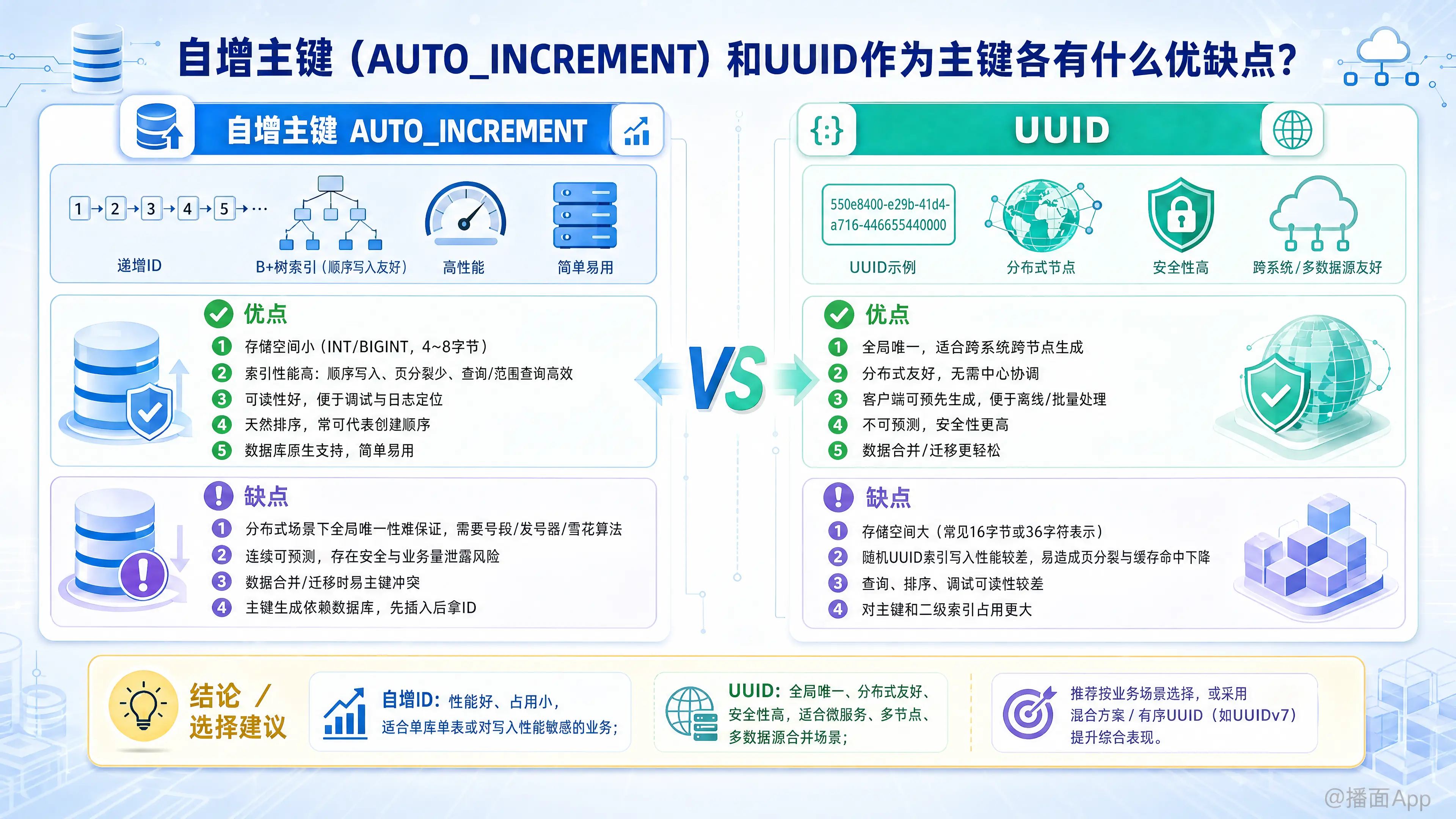
对比分析自增主键与UUID。自增ID性能好、存储小,但有分布式和安全问题;UUID全局唯一、安全,但性能和存储开销大。推荐根据场景选择或采用混合/有序UUID方案。
这是一个非常经典且重要的话题。选择自增主键(AUTO_INCREMENT)还是UUID作为主键,取决于你的应用场景、系统规模和未来的扩展性需求。
下面我将详细分析两者的优缺点,并提供选择建议。
自增主键 (AUTO_INCREMENT / SERIAL)
自增主键通常是整数类型(如 INT 或 BIGINT),数据库会在每次插入新记录时自动为其分配一个比上一条记录大1的值。
优点 (Advantages)
- 存储空间小:整数类型(通常是4字节的
INT或8字节的BIGINT)比UUID(通常是16字节)占用的存储空间要小得多。 - 索引性能高:
- 写入性能好:由于主键是顺序增长的,新记录的索引页总是在B+树索引的末尾,不需要移动或分裂已有的索引页,写入效率非常高。
- 查询性能好:基于范围的查询(如
WHERE id > 100)非常高效,因为数据在物理上是连续存储的。
- 可读性好,易于调试:
id=123这样的主键直观、简短,便于开发人员在日志、URL或口头交流中引用和调试。 - 天然排序:主键ID的顺序通常代表了记录的创建时间顺序,可以直接用
ORDER BY id来进行排序,非常方便。 - 简单易用:几乎所有关系型数据库都原生支持,配置简单,无需应用程序操心。
缺点 (Disadvantages)
- 分布式系统中的唯一性问题:这是最大的缺点。在分布式数据库或微服务架构中,多个节点或服务如果都想生成主键,很难保证全局唯一且连续。需要引入中心化的发号器(如Redis、Zookeeper)或使用类似雪花算法(Snowflake)的方案,增加了系统复杂性。
- 安全性风险:主键是连续且可预测的。攻击者可以轻易地通过URL(如
/orders/1001)猜测出下一个订单是/orders/1002,从而遍历数据,估算出你的业务量(如每天的用户数、订单数),造成商业信息泄露。 - 数据合并/迁移困难:当需要将两个独立的数据库(例如,开发环境和测试环境,或两个分公司的数据库)合并时,自增主键会发生冲突。解决冲突需要复杂的ID重映射,非常麻烦。
- 强依赖数据库:主键的生成依赖于数据库,应用程序必须先将数据插入数据库,才能获得新记录的ID。这在某些需要“先创建对象再保存”的场景下不方便。
UUID (Universally Unique Identifier)
UUID是一个128位的数字,通常表示为32个十六进制数字,并用连字符分隔(如 550e8400-e29b-41d4-a716-446655440000)。它通过算法保证在空间和时间上都是唯一的。
优点 (Advantages)
- 全局唯一性:UUID可以在任何时间、任何地点生成,几乎可以保证是全球唯一的。这是它在分布式系统中的核心优势。
- 分布式友好:每个服务或节点都可以独立生成ID,无需协调,大大简化了分布式系统的设计。非常适合微服务、多数据中心部署。
- 客户端可生成:应用程序可以在将数据发送到数据库之前就生成主键。这使得离线操作、批量插入等场景变得简单,应用与数据库解耦。
- 安全性高:UUID是无序且不可预测的,无法通过一个ID推测出其他ID的存在,避免了自增主鍵带来的安全风险。
- 数据合并/迁移简单:由于全局唯一,合并来自不同数据源的数据时,几乎不可能发生主键冲突。
缺点 (Disadvantages)
- 存储空间大:通常以字符串形式存储需要36个字符,或者以
BINARY(16)存储需要16个字节,是BIGINT的两倍。 - 索引性能差(特别是随机UUID):
- 写入性能差:随机生成的UUID(如UUIDv4)会导致新记录被插入到B+树索引的随机位置,频繁引起索引页的分裂和重组,导致大量的磁盘I/O和索引碎片化,写入性能远低于自增ID。
- 查询性能受影响:由于索引碎片化和数据物理存储上的不连续,范围查询性能较差,且索引本身更大,可能无法完全加载到内存中。
- 可读性差:长且无意义的字符串,不便于记忆、调试和人工操作。
- 无序性:标准的UUID(v4)是无序的,无法通过ID进行排序。需要依赖额外的
created_at等时间戳字段来排序。
总结与对比
| 特性 | 自增主键 (AUTO_INCREMENT) | UUID |
|---|---|---|
| 唯一性 | 单库唯一 | 全局唯一 |
| 性能 | 高 (特别是写入和范围查询) | 较低 (随机UUID导致索引碎片化) |
| 存储空间 | 小 (INT/BIGINT) | 大 (16字节或36字符) |
| 分布式 | 差 (需要额外机制保证唯一) | 优 (天然支持) |
| 安全性 | 低 (可预测) | 高 (不可预测) |
| 可读性 | 好 (简短、直观) | 差 (长、无意义) |
| 排序 | 天然按插入顺序排序 | 无序 (需要额外字段) |
如何选择?
选择哪种主键策略,没有绝对的对错,关键在于权衡利弊,匹配你的业务场景。
推荐使用自增主键的场景:
- 单体应用或小型项目:业务逻辑简单,数据量不大,没有分布式需求。
- 内部管理系统:如后台CRM、ERP等,不直接暴露给外部用户,安全性风险较低。
- 对性能和存储极其敏感的场景:例如需要存储海量日志或时序数据。
- 需要按插入顺序进行频繁排序和分页的表。
推荐使用UUID的场景:
- 分布式系统、微服务架构:这是UUID最主要的应用场景,可以解决跨节点ID生成的难题。
- 需要客户端生成ID的场景:如移动应用,在离线状态下创建数据,联网后再同步。
- 数据需要合并或同步的场景:如多环境数据迁移、主从复制、数据同步等。
- ID会暴露在URL或API中的场景:为了避免泄露业务量信息,保护数据安全。
混合方案与优化(The Best of Both Worlds)
在很多现代应用中,大家会采用一种混合策略来兼顾两者的优点:
内部用自增ID,外部用UUID:
- 表的主键(Primary Key)仍然使用自增ID (
id),以保证数据库内部的高性能和紧凑存储。 - 同时,增加一个UUID字段 (
uuid或public_id),并为其建立唯一索引(Unique Index)。 - 所有对内的操作(如表连接JOIN)都使用高效的自增ID。
- 所有对外暴露的API、URL都使用UUID,保证安全和分布式友好。
sqlCREATE TABLE products ( id BIGINT AUTO_INCREMENT PRIMARY KEY, -- 内部主键,高性能 uuid BINARY(16) NOT NULL UNIQUE, -- 外部公共ID,安全 name VARCHAR(255), ... );- 表的主键(Primary Key)仍然使用自增ID (
使用有序UUID(Combinable UUID):
为了解决随机UUID导致的索引性能问题,出现了一些改良版的UUID,如 UUID v7 (提议中) 或 ULID (Universally Unique Lexicographically Sortable Identifier)。它们将时间戳信息编码到UUID的前缀部分,使得生成的ID大致按时间有序。- 优点:既保证了全局唯一,又因为基本有序,大大减轻了数据库索引的碎片化问题,写入性能接近自增ID。
- 缺点:需要应用程序或数据库支持相应算法来生成,不是所有环境都开箱即用。但目前已有非常成熟的库可以使用。
如果你正在设计一个需要考虑未来扩展性的新系统,“内部自增ID + 外部UUID”的混合方案 或 使用有序UUID(如ULID) 是非常推荐的现代化实践。
右滑查看面试常问