讲讲 Flink-CDC SchemaRegistry 与 SchemaOperator 在 Flink CDC 3.0 的 Job 拓扑中是如何协作应对 DDL 变更事件的?
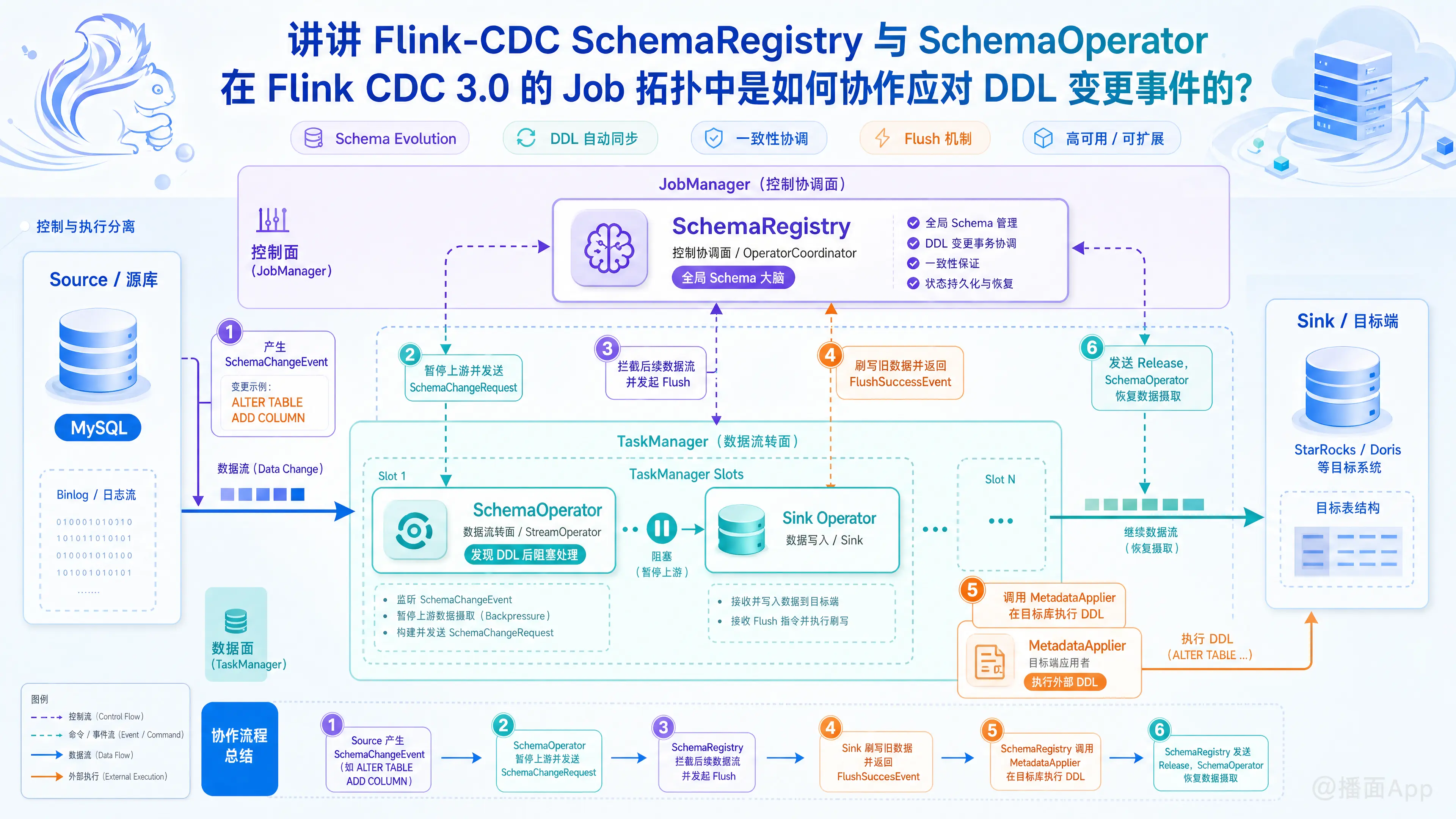
在 Flink CDC 3.0 数据集成框架中,支持表结构自动演进(Schema Evolution,即 DDL 自动同步)是一项核心特性。为了实现这一功能,社区设计了 SchemaRegistry 和 SchemaOperator 这两个核心组件,它们分别处于控制面和数据面,通过经典的一致性协调和管道刷写(Flush)机制,共同在作业拓扑中应对 DDL 变更。
以下是这两个组件的架构角色及其在 Job 拓扑中的具体协作过程:
一、 核心组件角色
在 Flink 拓扑中,这两个组件采取了“控制与执行分离”的设计模式:
- SchemaRegistry(控制协调面):
- 运行在 JobManager 进程中,继承自 Flink 的
OperatorCoordinator(算子协调器)框架。 - 充当作业中全局 Schema 管理的“大脑”,负责接收来自数据面的 schema 变更请求、拦截后续数据流、驱动外部目标端更新 DDL,并决定何时恢复数据摄取。
- 运行在 JobManager 进程中,继承自 Flink 的
- SchemaOperator(数据流转面):
- 运行在 TaskManager 的 Slots 中,是 Flink DataStream 拓扑中的一个物理算子(StreamOperator)。
- 处于数据通道上(通常介于 Source 与 Sink 之间),负责监听上游流向下游的数据事件,当发现 DDL 变更事件时,阻塞其本身的数据处理,并生成对应的网络刷新事件。
- MetadataApplier(目标端应用者):
- 由目标端 Sink(如 StarRocks, Doris 等连接器)实现并提供,负责接收
SchemaRegistry的指令,并在外部物理目标库上真实执行 DDL 操作。
- 由目标端 Sink(如 StarRocks, Doris 等连接器)实现并提供,负责接收
二、 DDL 变更的详细协同演进流程
当上游源数据库(例如 MySQL)发生了一次加列操作(ALTER TABLE ADD COLUMN)时,SchemaRegistry 与 SchemaOperator 在 Flink 拓扑中协作的具体流转流程如下:
plaintext
[Source] ──> SchemaChangeEvent ──> [SchemaOperator] ───────────────────> [Sink]
│ │
(2. 暂停上游 & 发送 (4. 刷写旧数据并发送
SchemaChangeRequest) FlushSuccessEvent)
│ │
▼ ▼
[SchemaRegistry] <──────────────────────────┘
│
(5. 调用 MetadataApplier
到目标库真实执行 DDL)
│
(6. 发送 Release 响应)
│
▼
[SchemaOperator] ──> (7. 恢复数据流传输)1. 初始化阶段(注册绑定)
在 Flink 任务启动时,下游所有的 Sink Writer 实例都会向运行在 JobManager 上的 SchemaRegistry 进行注册。SchemaRegistry 借此获取并记录当前整个作业中的 Writer 实例总数(writerCount)。
2. DDL 事件捕获与主动阻断
- 当上游 Source 发生 DDL 变更时,Source 节点会生成一个
SchemaChangeEvent(例如AddColumnEvent)并发送到下游。 - 拓扑中间的
SchemaOperator接收到此SchemaChangeEvent后:- 它会立即暂停(Hold/Block)数据通道,不再继续向后传递后续接收到的
DataChangeEvent(此时,新 Schema 下的数据变更积压在算子前部),以此保证新老 Schema 数据不发生混杂。 - 它向 JobManager 上的
SchemaRegistry发送一个包含本次表结构变更信息的 RPC 请求(SchemaChangeRequest),向“大脑”申请 DDL 注册并阻塞等待回复。
- 它会立即暂停(Hold/Block)数据通道,不再继续向后传递后续接收到的
3. 广播刷写事件(Flush 广播)
因为在 DDL 触发时,Flink 的网络传输通道(Network Buffer)中可能还残留有旧 Schema 格式的数据变更事件,不能直接在目标库上应用 DDL。
SchemaOperator会向所有的下游 Sink Operator 广播下发一个特殊的FlushEvent标记。
4. 管道数据排空(Drain / Flush)
- 下游的各个 Sink Writer 实例在接收到
FlushEvent后:- 会立即把内存中所有已经积压和缓冲的、属于旧 Schema 格式的数据强制排空并安全刷写(Flush)到外部存储中。
- 刷写成功后,Sink 实例会向 JobManager 上的
SchemaRegistry反馈发送一个FlushSuccessEvent。
5. 目标物理库 DDL 应用
SchemaRegistry持续收集下游 Sink 汇报的FlushSuccessEvent。- 当收集到的数量等于初始注册的
writerCount时,说明整个 Flink 拓扑管道中的历史旧数据已全部安全写入目标端。 - 此时,
SchemaRegistry调用 DataSink 提供的MetadataApplier,向外部数据库发起真实的 DDL 变更申请(例如在目标表执行加列语句)。 - 当外部目标端 DDL 修改成功后,
SchemaRegistry更新其在 JobManager 内存中维护的表元数据状态(以解析后续新数据格式)。
6. 恢复管道流转(Resume)
- 目标库 DDL 应用完毕后,
SchemaRegistry向之前处于阻塞等待状态的SchemaOperator发送回复,确认 DDL 同步完成(ReleaseUpstreamResponse)。 - 下游 Sink Writer 接收到更新通知,以便更新内部反序列化器来对接新结构。
SchemaOperator收到释放响应后,解除对上游数据的阻塞,开始下发后续积压的新 Schema 数据(DataChangeEvent),整个管道同步链路恢复顺畅运行。
三、 这一设计的关键优势
- 严格的数据结构屏障(Schema Barrier):
FlushEvent充当了数据流中的“分水岭”,它保证了在 DDL 执行之前,旧结构的数据一定已经全部落盘,避免了目标端出现旧数据匹配新字段(或反之)导致数据错位、混杂的致命错误。 - 多并发状态对齐:
在 Flink 作业并行度大于 1 时,多路 DDL 事件在不同的 TaskManager 节点并发流转,集中式协调器(SchemaRegistry)能防止各个 Sink 并发去外部库上执行重复/冲突的ALTER TABLE操作,避免因竞争导致目标表产生元数据冲突(如Column already exists报错)。
右滑查看面试常问