Flink消费 Kafka 出现了积压,你会如何排查?
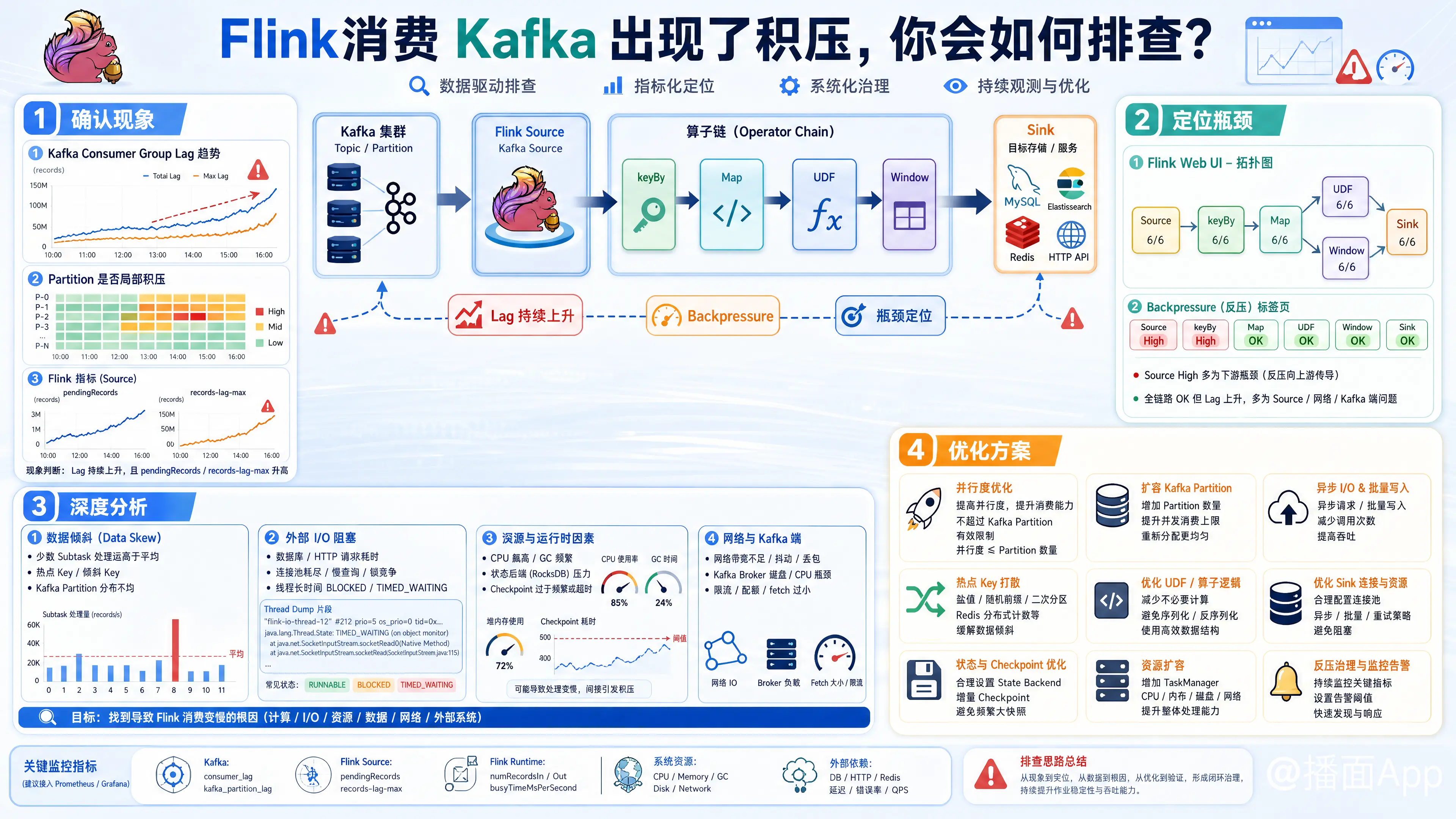
在实际生产环境中,Flink 消费 Kafka 出现作业积压(Lag 持续上升)是一个非常经典且常见的问题。排查此问题通常需要遵循“确认现象 -> 定位瓶颈 -> 分析原因 -> 制定方案”的系统性步骤。
以下是具体的排查思路和步骤:
第一步:确认积压现状与范围
在动手调整之前,首先需要明确积压的物理表现:
- 监控指标分析:
- 通过 Kafka 监控(如 Prometheus + Grafana 或 Kafka Manager)查看该 Consumer Group 的 Lag 变动趋势。是全局所有 Partition 都在积压,还是只有某几个 Partition 在积压?
- 通过 Flink Web UI 查看 Source 算子的
pendingRecords(未消费记录数)或records-lag-max指标,确认 Flink 侧感知的积压量。
- 确认时效性与诱因:
- 突发性积压:是否由于上游业务搞活动、大促导致流量激增?或者下游存储系统(如 MySQL, Elasticsearch)突发故障?
- 持续性积压:作业上线后吞吐量一直跟不上,随着时间推移 Lag 持续线性增长。
第二步:利用 Flink Web UI 定位瓶颈
Flink 提供了非常直观的物理拓扑图和反压(Backpressure)监控,这是定位瓶颈最快速的方式。
打开 Flink Web UI,点击运行中的 Job,查看 Backpressure 标签页:
情况 A:Source 算子处于“High”反压状态,或下游算子反压严重
- 原理解析:根据 Flink 的反压传播机制(从下游往上游传递),如果 Source 被反压了,说明瓶颈在下游算子或 Sink 端。下游处理不过来,导致 Buffer 占满,进而限制了 Source 消费 Kafka 的速度。
- 排查重点:顺着数据流向下寻找,找到第一个状态为“High”但其下游为“OK”的算子,该算子即为物理瓶颈点(通常是业务逻辑复杂的 UDF 算子或 Sink 算子)。
情况 B:所有算子反压均为“OK”,但 Kafka Lag 仍在上升
- 原理解析:说明下游消费极快,但 Source 自身拉取数据太慢。
- 排查重点:瓶颈在 Source 算子自身,或者 Flink 与 Kafka 集群之间的网络/IO 存在限制。
第三步:针对具体瓶颈点进行深度分析
根据第二步定位出的瓶颈,进行针对性排查:
1. 排查是否存在“数据倾斜”(Data Skew)
数据倾斜是导致局部积压的最常见原因。
- 如何排查:在 Web UI 中观察该算子各个 Subtask 的
Bytes Received、Records Received以及Subtask Backpressure。 - 现象:如果发现只有某一个或少数几个 Subtask 的处理数据量、CPU 使用率极高,而其他 Subtask 非常空闲,说明存在数据倾斜。
- 根源分析:
- Kafka 层面:上游往 Kafka 写数据时 Key 指定不合理,导致某些 Partition 的数据量远大于其他 Partition。
- Flink 层面:在 Flink 算子链中使用了
keyBy,但 Key 的哈希分布不均匀(如存在热点 Key)。
2. 排查是否存在“外部 I/O 阻塞”
在 Map 或 FlatMap 算子中,如果存在同步请求外部数据库(如 Redis、MySQL、HBase、HBase 或外部 HTTP API)的逻辑,会严重拖慢吞吐。
- 如何排查:通过 Flink UI 抓取该 TaskManager 的 Thread Dump。
- 现象:如果发现大量的线程都处于
BLOCKED或TIMED_WAITING状态,且堆栈指向数据库连接、网络请求或等待锁,说明被同步 I/O 阻塞。
3. 排查 JVM 垃圾回收(GC)与资源瓶颈
严重的 GC 停顿(Stop-The-World)会导致 TaskManager 瞬间失去处理能力,产生积压。
- 如何排查:通过监控(如 Grafana 或 TaskManager 的 Stdout/Stderr)查看内存占用及 GC 日志。
- 现象:JVM 堆内存(尤其是老年代)持续在高位运行,频繁发生 Full GC,单次 GC 耗时达到数秒级。此外,检查 CPU 负载是否已经接近 100%。
4. 排查 Sink 端写入性能瓶颈
如果反压源头在 Sink 算子,说明下游存储介质(如 JDBC, Hudi, Elasticsearch)达到了写入瓶颈。
- 如何排查:
- 检查下游数据库的 CPU、I/O 吞吐、磁盘繁忙度。
- 检查写入是否存在锁冲突,或者目标端由于连接数被打满、写入队列溢出而拒绝服务。
5. 排查 Flink 消费 Kafka 的参数配置
如果 Source 自身消费慢且无反压:
- 并发度不足:Flink 消费 Kafka 的 Source 并发度是否小于 Kafka 的 Partition 数量?如果并发度小于分区数,会导致某些 Subtask 消费多个分区,处理不过来;如果并发度大于分区数,多出的并发将处于空闲状态。
- 配置参数不合理:检查
max.poll.records(单次拉取最大记录数)、fetch.min.bytes、fetch.max.wait.ms等参数是否设置过小,导致网络交互过于频繁,吞吐量无法提升。
第四步:针对性的优化与解决方案
定位到原因后,可以采取以下手段进行优化:
- 解决数据倾斜:
- 如果是 Key 分布不均,可以考虑引入“两阶段聚合”(先加随机前缀进行局部聚合,再去掉前缀进行全局聚合)。
- 重新设计 keyBy 的 Key,或者在没有严格业务顺序要求下使用
rebalance()重新打散数据分发。
- 重构外部 I/O(引入异步与缓存):
- 将同步的数据库/API 请求重构为 Async I/O(异步 I/O)。
- 在 Flink 内存中引入本地缓存(如 Guava Cache),减少对外部存储的请求频次。
- Sink 写入攒批与调优:
- 开启 Sink 的批量写入功能(设置合理的批量条数
batch size和最大延迟等待时间flush interval)。 - 对下游目标存储进行调优(如增加索引写入缓存、调整物理分片等)。
- 开启 Sink 的批量写入功能(设置合理的批量条数
- 调整消费参数与并发:
- 确保 Flink Source 算子的并行度等于 Kafka 的 Partition 数量,实现 1:1 的最佳消费模型。
- 适当调大 Kafka Consumer 的
max.poll.records(例如从 500 调大到 2000)以增加单次批处理的吞吐量。
- 系统资源扩容与 JVM 调优:
- 适当调大 TaskManager 的内存(尤其是 Managed Memory 和 Framework Memory),防止因内存不足频繁触发 GC。
- 在条件允许的情况下,直接增加 TaskManager 实例(水平扩容)以分担整体计算压力。
右滑查看面试常问