讲讲 Doris 中主键模型的读时合并(Merge-on-Read, MoR)
在 Apache Doris 中,Unique Key(主键)模型是为了满足用户对于数据的更新(Upsert)和删除(Delete)需求而设计的。
在 Doris 的演进过程中,Unique Key 模型经历了两种底层的实现方式:传统的 读时合并(Merge-on-Read, 简称 MoR) 和后来引入的 写时合并(Merge-on-Write, 简称 MoW)。
下面为你详细解析 Doris 主键模型中的 读时合并(MoR) 机制。
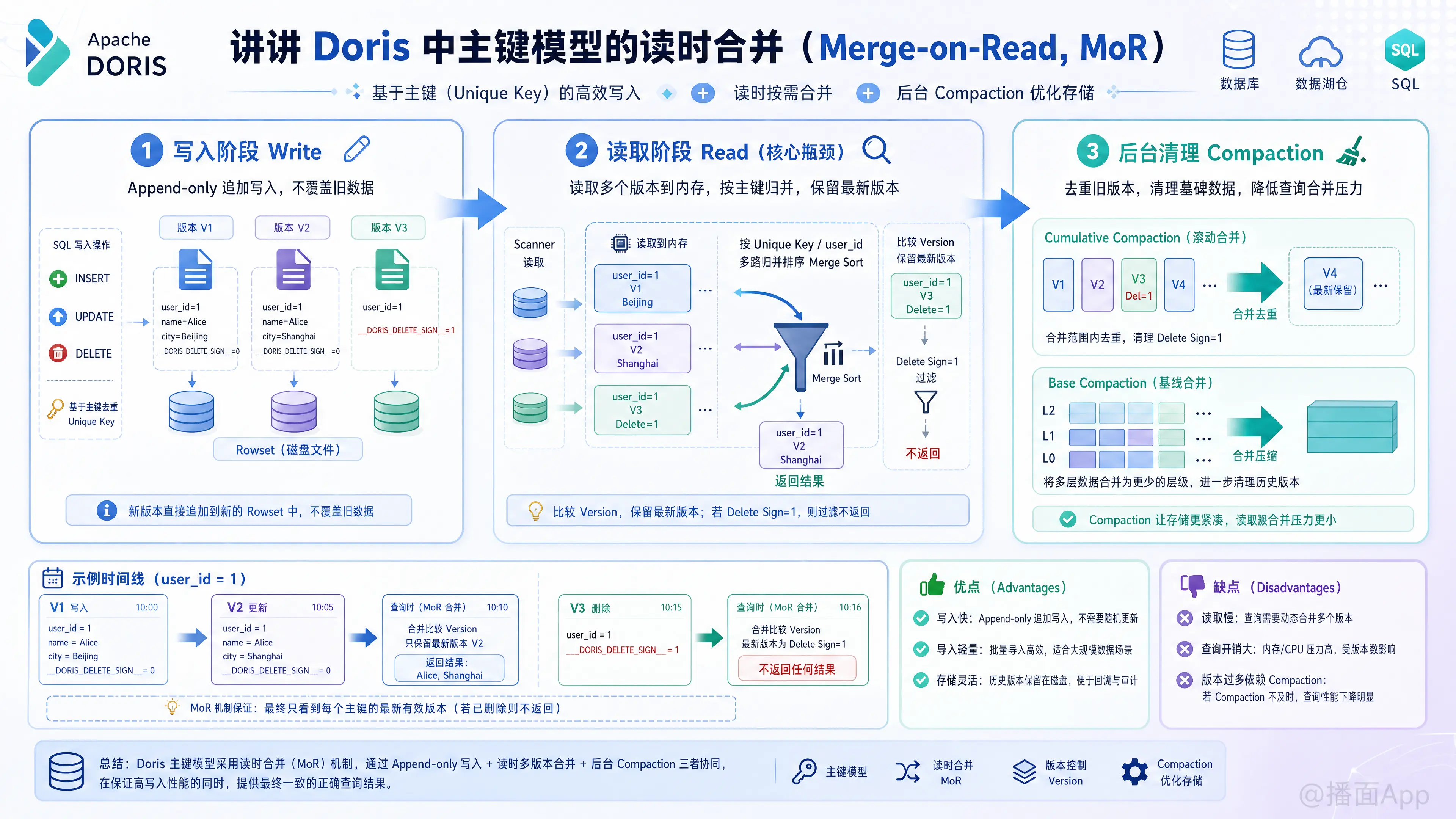
1. 什么是读时合并(Merge-on-Read, MoR)?
顾名思义,“读时合并”的核心思想是:把数据合并(去重、更新)的压力放在“读取(查询)”阶段,而让“写入”阶段尽可能轻量和快速。
在 MoR 模式下,当有新数据写入或者旧数据更新时,Doris 不会在写入时去底层数据文件中寻找旧数据并覆盖它,而是将新数据作为一个新的版本(Version)直接追加写入(Append-only)。只有当用户发起查询(Read)时,Doris 才会把相同主键的多个版本数据读取出来,在内存中进行动态合并,最终只返回最新版本的数据。
2. MoR 的工作原理详解
我们可以从 写入、读取 和 后台清理 三个阶段来理解 MoR 是如何工作的。
A. 写入阶段 (Write)
- 追加写入(Append-only): 所有的
INSERT、UPDATE或DELETE操作,在存储层都被视为“追加写入”。 - 版本号(Version): Doris 为每一次导入批次分配一个递增的版本号。例如,第一次写入版本号是 V1,第二次更新是 V2。
- 删除标志(Delete Sign): 如果是
DELETE操作,Doris 并不是物理删除那行数据,而是写入一条主键相同,但隐藏列__DORIS_DELETE_SIGN__被标记为1的数据(相当于墓碑机制 Tombstone)。
例子:
假设有一张用户表,主键是 user_id。
- 写入:
(user_id=1, name='Alice', city='Beijing')-> 存入磁盘,版本号 V1。 - 更新: Alice 搬到了上海,写入
(user_id=1, name='Alice', city='Shanghai')-> 存入磁盘,版本号 V2。
此时磁盘上同时存在 V1 和 V2 两条user_id=1的记录。
B. 读取阶段 (Read) - 【核心性能瓶颈所在】
当用户执行 SELECT * FROM table WHERE user_id = 1 时:
- Doris 的扫描节点(Scanner)会把磁盘上 V1 和 V2 两个版本的数据都读入内存。
- 在内存中,按照主键
user_id进行多路归并排序(Merge Sort)。 - 发现两条主键相同的记录,比较它们的版本号。
- 保留版本号更大的 V2(上海),丢弃 V1(北京)。
- 如果最新版本的数据带有删除标志(Delete Sign = 1),则将其过滤掉,不返回给用户。
C. 后台清理阶段 (Compaction)
如果数据不断更新,磁盘上的版本会越来越多,导致查询时需要合并的数据量呈指数级上升,查询极其缓慢。
为了解决这个问题,Doris 后台会不断运行 Compaction(数据压缩/合并) 任务:
- Cumulative Compaction(增量合并): 将最近产生的小版本合并成一个较大的版本。
- Base Compaction(全量合并): 将增量合并产生的大版本与基线数据合并。
- 在 Compaction 过程中,Doris 也会在后台执行主键去重,物理删除掉旧版本和被标记为删除的数据,从而降低后续查询的合并压力。
3. MoR 的优缺点分析
优点:
- 写入性能极高: 因为是纯追加写入(Append-only),无需在写入时读取和比对历史数据,不需要加锁等待,写入吞吐量非常大。
- 写资源消耗低: 写入过程非常轻量,CPU 和内存消耗少,适合极高并发的高频实时写入场景。
缺点:
- 查询性能较差(特别是数据刚写入时): 因为查询时需要在内存中进行多路归并排序和去重,这非常消耗 CPU,导致查询延迟较高。
- 谓词下推受限: 对于非主键列的过滤条件(WHERE 条件),很多时候无法在扫描磁盘数据时就过滤掉,必须等数据合并出最新版本后才能进行过滤(否则可能会用旧版本的数据做了错误的过滤)。这导致数据读取量大增。
- 性能极度依赖 Compaction: 如果写入过于频繁,导致后台 Compaction 跟不上,积压的版本过多(Version Too Many),查询性能会呈断崖式下跌,甚至报出
-235错误导致写入失败。
4. 为什么 Doris 后来引入了写时合并(Merge-on-Write, MoW)?
正是因为 MoR 在高频更新 + 极速分析的场景下,查询性能无法满足用户的极致要求,Doris 从 1.2 版本开始引入了 Merge-on-Write (MoW),并在之后的版本中将其作为 Unique Key 模型的默认选项。
MoW 与 MoR 的区别简述:
- MoW(写时合并): 写入数据时,系统会去寻找该主键旧版本所在的位置,并通过 Bitmap(Delete Bitmap)将旧数据标记为删除。
- 查询时: 查询引擎只需要根据 Delete Bitmap 过滤掉被标记为删除的行即可,完全不需要在内存中做任何主键的比对和合并。
- 结果: 稍微牺牲了一点写入速度(因为写入时要维护 Bitmap),但换来了和明细模型(Duplicate)几乎一样快的极速查询性能,并且完美支持各种谓词下推。
5. 总结建议
- 如果你使用的 Doris 版本较老(1.2 以前),主键模型默认就是 MoR。你需要密切关注后台的 Compaction 状态。
- 如果你使用的是 Doris 1.2 及以上版本(尤其是 2.x 版本),强烈建议使用默认的 MoW(写时合并)机制,它在 95% 以上的场景中都能提供比 MoR 好得多的综合体验。
- 什么情况下还在用 MoR? 只有在极少数“写请求极其巨大、更新频率极高,但查询频率很低、对查询延迟要求不高”的极端场景下,MoR 的高吞吐写入优势才有发挥空间。