为什么 Doris 选用 MPP(大规模并行处理)架构?
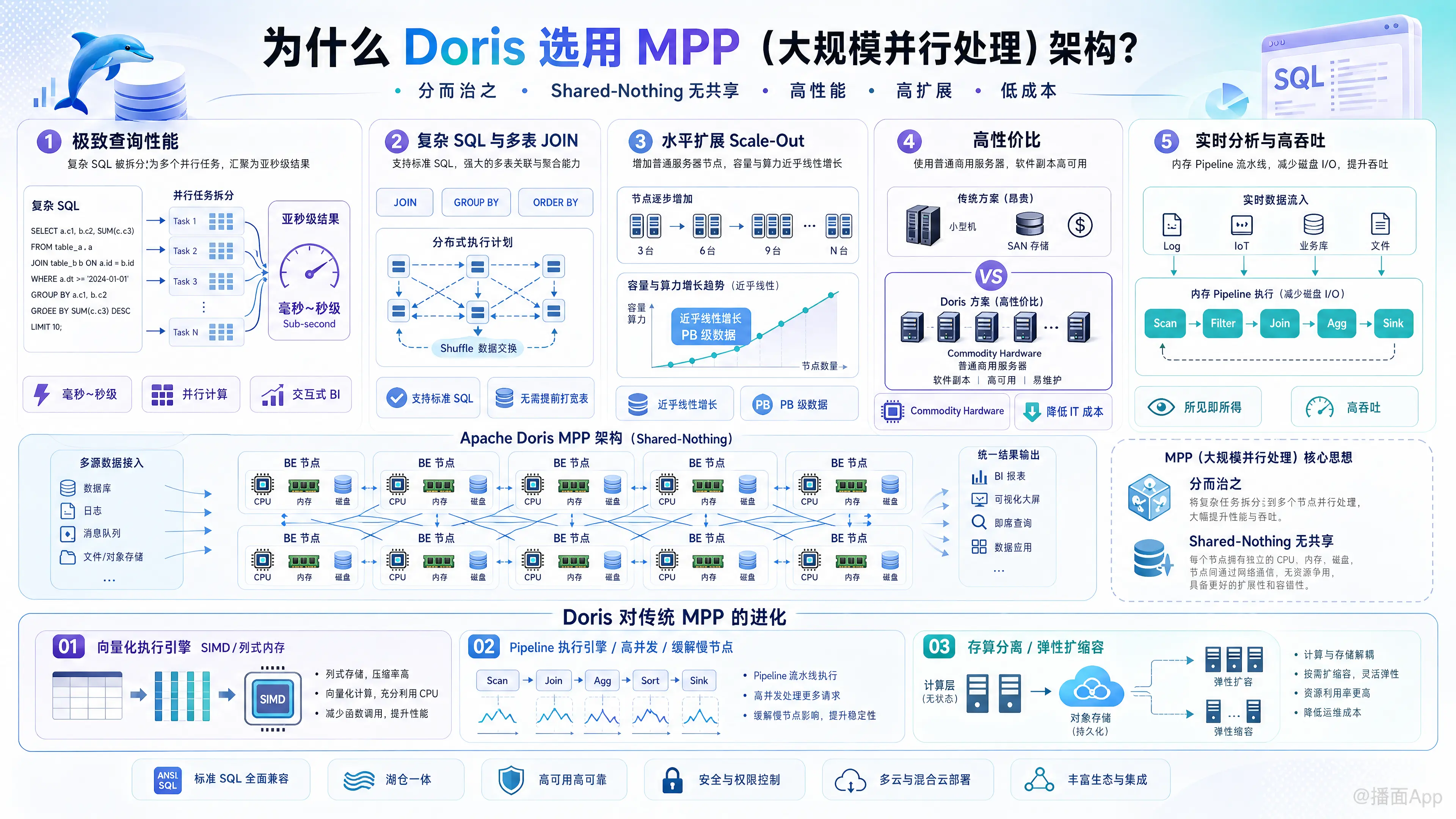
Apache Doris 选用 MPP(Massively Parallel Processing,大规模并行处理) 架构,是由其作为 “新一代实时高性能 OLAP 分析型数据库” 的产品定位和核心业务需求决定的。
简单来说,MPP 架构的核心思想是“分而治之”和“无共享(Shared-Nothing)”。Doris 选择这种架构,主要出于以下几个维度的考量:
1. 极致的查询性能(极低延迟)
- 分而治之: 在 MPP 架构下,一个复杂的 SQL 查询会被拆分成多个物理执行计划,分发到集群中的多个节点上同时执行。
- 并行计算: 每个节点只处理自己本地存储的那部分数据,计算完成后将结果汇总。这种架构能够充分利用集群中所有机器的 CPU 和内存资源,将原本需要分钟级执行的查询压缩到亚秒级(毫秒到秒级),非常适合面向业务人员的交互式 BI 分析。
2. 支持极其复杂的 SQL 和多表 JOIN
- 与 Scatter-Gather 架构对比: 像 Elasticsearch、Druid 等系统通常采用 Scatter-Gather(分散-聚集)架构,这种架构处理单表聚合非常快,但在处理分布式大表 JOIN 时能力极弱。
- MPP 的 Shuffle 机制: MPP 架构支持节点间的数据交换(Shuffle 操作)。当 Doris 需要执行复杂的
JOIN、GROUP BY、ORDER BY或嵌套子查询时,数据可以在不同计算节点之间重分布,从而完美支持标准 SQL 的复杂分析场景,不需要用户提前将数据打平成宽表。
3. 优秀的水平扩展能力(Scale-Out)
- 无共享架构(Shared-Nothing): Doris 的 BE(Backend)节点是无状态且无共享的。每个节点拥有独立的 CPU、内存和磁盘,节点之间互不干扰。
- 线性扩展: 当数据量暴增或算力不足时,只需要简单地增加普通的商用服务器节点即可。随着节点数量的增加,系统的存储容量和计算能力能够实现近乎线性的增长,轻松支撑 PB 级别的数据规模。
4. 摆脱昂贵硬件,高性价比
- 与传统的 SMP(对称多处理,如 Oracle 依赖的高端小型机)或 Shared-Disk(共享磁盘,依赖昂贵的 SAN 存储网络)架构不同,MPP 架构设计之初就是运行在普通商用服务器(Commodity Hardware)上的。
- 通过软件层面的分布式副本机制来保证高可用性,大幅降低了企业的 IT 基础设施成本。
5. 满足实时分析与高吞吐需求
- 与批处理架构(如 Hadoop/MapReduce/Hive)对比: MapReduce 模型为了极高的容错性,在计算的每个阶段都会将中间结果落盘(写入磁盘),导致 I/O 开销巨大,延迟极高。
- 内存计算: MPP 架构在执行查询时,中间结果主要在内存中流转(Pipeline 模式),省去了大量的磁盘 I/O 开销,吞吐量大,能够满足现代企业对数据“所见即所得”的实时分析需求。
补充:Doris 对传统 MPP 架构的进化
传统的 MPP 架构虽然好,但也存在一些痛点(如:并发能力相对较差、容易受到“木桶效应/慢节点”的影响)。为了解决这些问题,Doris 在传统的 MPP 架构之上做了大量的深度优化:
- 全面向量化执行引擎: Doris 重写了执行引擎,采用列式内存布局和向量化计算(SIMD),一次处理一批数据而不是一行数据,极大提升了单核 CPU 的处理效率。
- Pipeline 执行引擎: 传统的 MPP 往往采用“一个任务占用一个线程”的阻塞模型,并发一高就容易耗尽线程池。Doris 引入了 Pipeline 调度模型,将查询切分成细粒度的任务放入队列,由调度器异步调度,彻底打破了高并发的瓶颈,并缓解了慢节点(Straggler)拖慢整体查询的问题。
- 存算分离(近期版本引入): 为了解决 MPP 架构在资源弹性扩缩容上的痛点,Doris 在 2.x 版本开始支持存算分离架构(数据存在 S3/HDFS 等共享存储,计算节点变成无状态的 Cache 节点),结合了 MPP 的高性能和云原生的极致弹性。
总结:
Doris 选用 MPP 架构,是因为 MPP 是目前实现 “海量数据 + 复杂关联查询 + 亚秒级响应” 最优的技术路径。在此基础上,Doris 通过引入向量化和 Pipeline 等现代数据库技术,将 MPP 架构的威力发挥到了极致。
右滑查看面试常问