Doris与 ClickHouse、StarRocks 在架构有何异同?
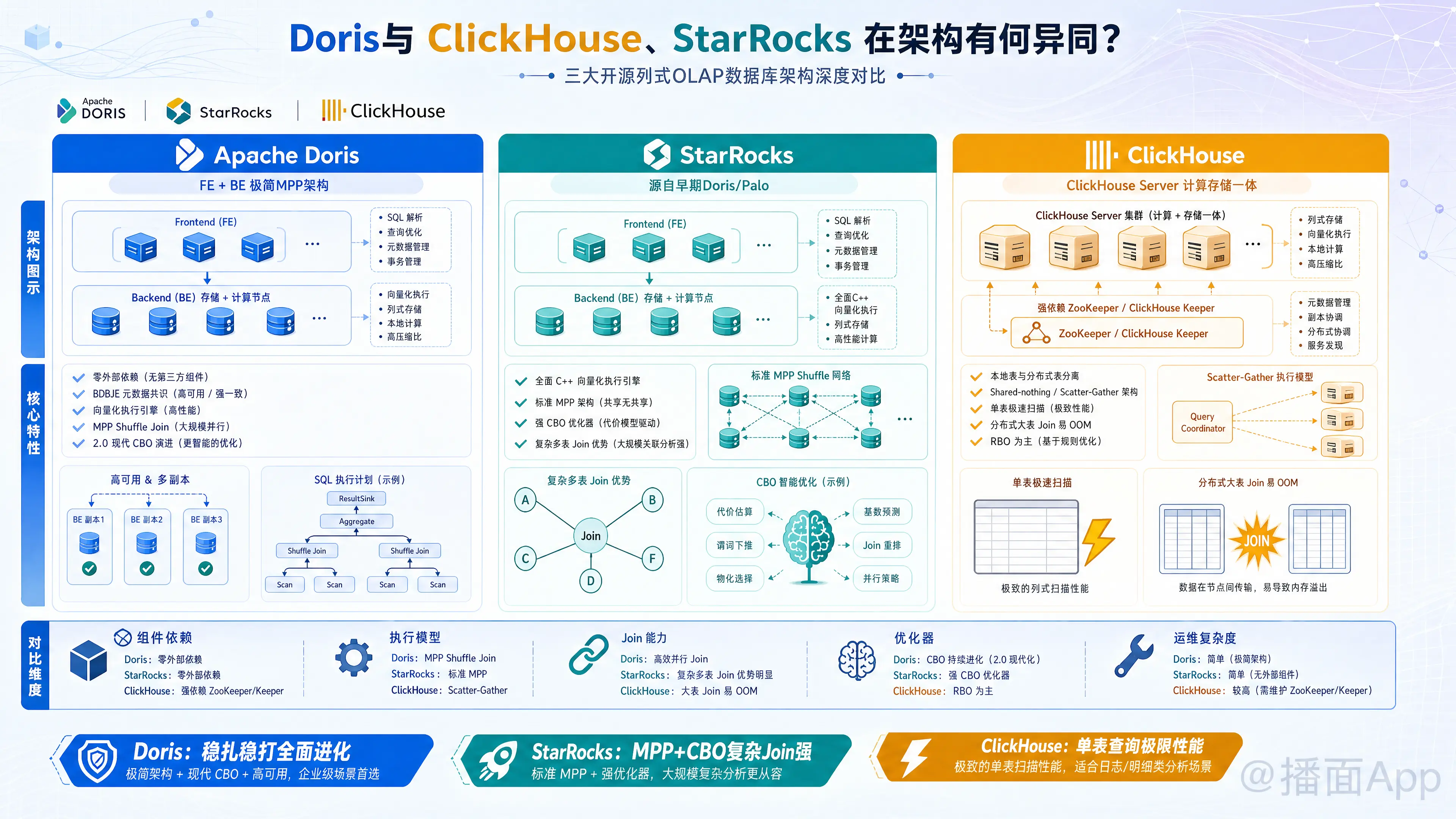
Apache Doris、StarRocks 和 ClickHouse 都是目前业界最顶级的开源列式分析型数据库(OLAP),但它们的架构设计理念、发展历程以及擅长的场景有显著差异。
由于 StarRocks 脱胎于早期版本的 Apache Doris (原 Palo),两者在基础架构上有极高的相似性,而 ClickHouse 则是完全不同的俄罗斯体系架构。
以下是这三者在架构上的异同深度对比:
一、 整体架构拓扑与组件依赖
1. Doris & StarRocks:极简的 MPP 架构
- 组件结构:两者都采用了极其精简的 FE (Frontend) + BE (Backend) 架构。
- FE:负责接收请求、解析 SQL、生成执行计划、管理元数据(基于内置的 BDBJE 共识协议,不需要外部依赖)。
- BE:负责数据存储和具体的 SQL 执行。
- 依赖:零外部依赖。部署和运维极其简单,不需要安装 ZooKeeper 或 Hadoop 生态组件。
- 高可用:FE 和 BE 都可以横向扩展,FE 通过多节点保证元数据高可用,BE 通过多副本保证数据高可用。
2. ClickHouse:松耦合的大数据集群架构
- 组件结构:ClickHouse Server 节点既负责计算也负责存储(早期是纯 Shared-nothing 架构)。
- 依赖:强依赖 ZooKeeper(或较新的 ClickHouse Keeper)。ClickHouse 的分布式表 DDL、数据复制(ReplicatedMergeTree)、集群节点状态同步,全部依赖 ZK。
- 复杂性:架构更像是一个个单机数据库被 ZK "强行" 拼成了一个集群。它的本地表和分布式表是分离的,运维复杂度远高于 Doris 和 StarRocks。
二、 计算引擎与执行模型(核心差异)
1. ClickHouse:单表极限压榨者(Scatter-Gather 模型)
- 向量化执行:ClickHouse 从底层代码级别将 C++ 的 SIMD(单指令多数据流)指令优化到了极致,这也是它单表查询快到离谱的原因。
- 执行模型:采用自底向上的 Scatter-Gather(分散-聚合)模型。查询被下发到各个节点本地执行,然后将结果汇聚到发起节点。
- Join 能力的痛点:因为这种架构,ClickHouse 在处理分布式多表 Join 时非常吃力。它通常需要把右表广播到所有节点(Broadcast Join),如果在两张大表之间做 Hash Join/Shuffle Join,极易导致 OOM(内存溢出)或性能骤降。
- 优化器:主要依赖 RBO(基于规则的优化器),CBO(基于代价的优化器)能力长期偏弱。
2. StarRocks:全面向量化与最强 CBO(纯 MPP 模型)
- 向量化执行:StarRocks 分家后,率先从头重写了纯 C++ 的全面向量化执行引擎,性能相比早期 Doris 有了质的飞跃。
- Join 能力:StarRocks 的核心卖点。它是一个标准的 MPP(大规模并行处理)架构,支持数据在各个计算节点之间灵活地 Shuffle(重分布)。因此,它在处理多张亿级大表的复杂 Join 时游刃有余。
- 优化器:拥有目前三者中最成熟的 CBO(基于代价的优化器),能够极其聪明地调整多表 Join 的顺序和执行计划。
3. Doris:稳扎稳打的全面进化者(MPP 模型)
- 向量化执行:Doris 早期非向量化,但从 1.2 版本开始全面切换到向量化引擎,目前在单表扫描性能上已经追平甚至在某些场景反超。
- Join 能力:同样是 MPP 架构,Join 能力远胜 ClickHouse,与 StarRocks 同属第一梯队。
- 优化器:在 2.0 版本推出了全新的现代 CBO 优化器(Nereids),补齐了之前面对复杂 SQL 时的短板,目前复杂查询能力与 StarRocks 咬得很紧。
三、 存储架构与数据更新机制
1. ClickHouse:MergeTree 家族与 Append-Only
- 存储模型:基于 LSM-Tree 变种的 MergeTree 引擎。
- 更新机制:ClickHouse 骨子里是一个追加写入(Append-only)的系统。虽然支持
UPDATE/DELETE(通过 Mutation 操作),但极其重型,是异步执行的。它极不擅长高频的实时细粒度更新(例如订单状态的实时变更)。
2. Doris & StarRocks:强大的实时更新能力
- 存储模型:两者都提供 明细模型(Duplicate)、聚合模型(Aggregate)、主键模型(Unique)。
- 更新机制:
- 这是 Doris 和 StarRocks 远胜 ClickHouse 的地方。两者都在 Unique Key 模型上做了巨大的底层创新。
- 它们实现了 Merge-on-Write(写时合并) 技术。在数据实时高频 upsert(更新/插入)时,能够在底层快速标记删除并写入新数据,查询时无需再做昂贵的合并(Merge-on-Read),从而实现了“既能高频更新,查询又极快”。
四、 架构的最新演进(云原生化)
目前这三款数据库都在向 存算分离(Shared-Data) 架构演进,以适应云原生:
- ClickHouse:推出了 ClickHouse Cloud,底层数据存放在 S3 等对象存储上,计算节点无状态化。
- StarRocks:在 3.0 版本后全面发力存算分离架构,并且极其强调 数据湖分析(Lakehouse) 能力,可以直接作为查询引擎去极速查询 Iceberg、Hudi、Hive 中的数据(无需导入)。
- Doris:在 3.0 版本(及商业版 SelectDB)中也实现了极致的存算分离,同时也支持了极速的数据湖联邦查询。相比之下,Doris 更强调高并发面向用户(To-C)的报表查询和日志分析引擎的替代(倒排索引)。
五、 总结与选型建议
| 特性 | ClickHouse | Apache Doris | StarRocks |
|---|---|---|---|
| 系统架构 | 松耦合,强依赖 ZK,分片管理复杂 | 极简 FE+BE,零外部依赖,运维简单 | 极简 FE+BE,零外部依赖,运维简单 |
| 单表查询性能 | ⭐️⭐️⭐️⭐️⭐️ (极限速度) | ⭐️⭐️⭐️⭐️ | ⭐️⭐️⭐️⭐️ |
| 多表 Join 能力 | ⭐️⭐️ (易 OOM) | ⭐️⭐️⭐️⭐️ (MPP 架构,Nereids 优化器) | ⭐️⭐️⭐️⭐️⭐️ (MPP 架构,自研顶级 CBO) |
| 并发能力 | 较低 (消耗CPU过快) | ⭐️⭐️⭐️⭐️⭐️ (支持高并发点查) | ⭐️⭐️⭐️⭐️ (高并发不断优化中) |
| 实时更新能力 | 极弱 (不支持高频 Update) | ⭐️⭐️⭐️⭐️⭐️ (Merge-on-Write) | ⭐️⭐️⭐️⭐️⭐️ (Merge-on-Write) |
| 数据湖联邦分析 | 一般 | 优秀 | 极优 (主推 Lakehouse) |
选型一句话指南:
- 选 ClickHouse:如果你只有单张超宽大表,没有(或极少)表关联,数据都是日志流水型(不修改),追求极限的单表查询速度。
- 选 Apache Doris:如果你需要一个全场景的数据仓库,既有大表分析又有高并发报表,业务经常需要实时更新数据,并且希望部署和运维越简单越好。
- 选 StarRocks:如果你有海量数据的复杂多表 Join 需求,原本使用 Presto/Trino 觉得太慢,或者你想直接在 Iceberg/Hudi 数据湖上做极速分析而不迁移数据。
右滑查看面试常问