如何监控 HBase 的读写延迟(Read/Write Latency)和吞吐量?常用的监控工转换有哪些?
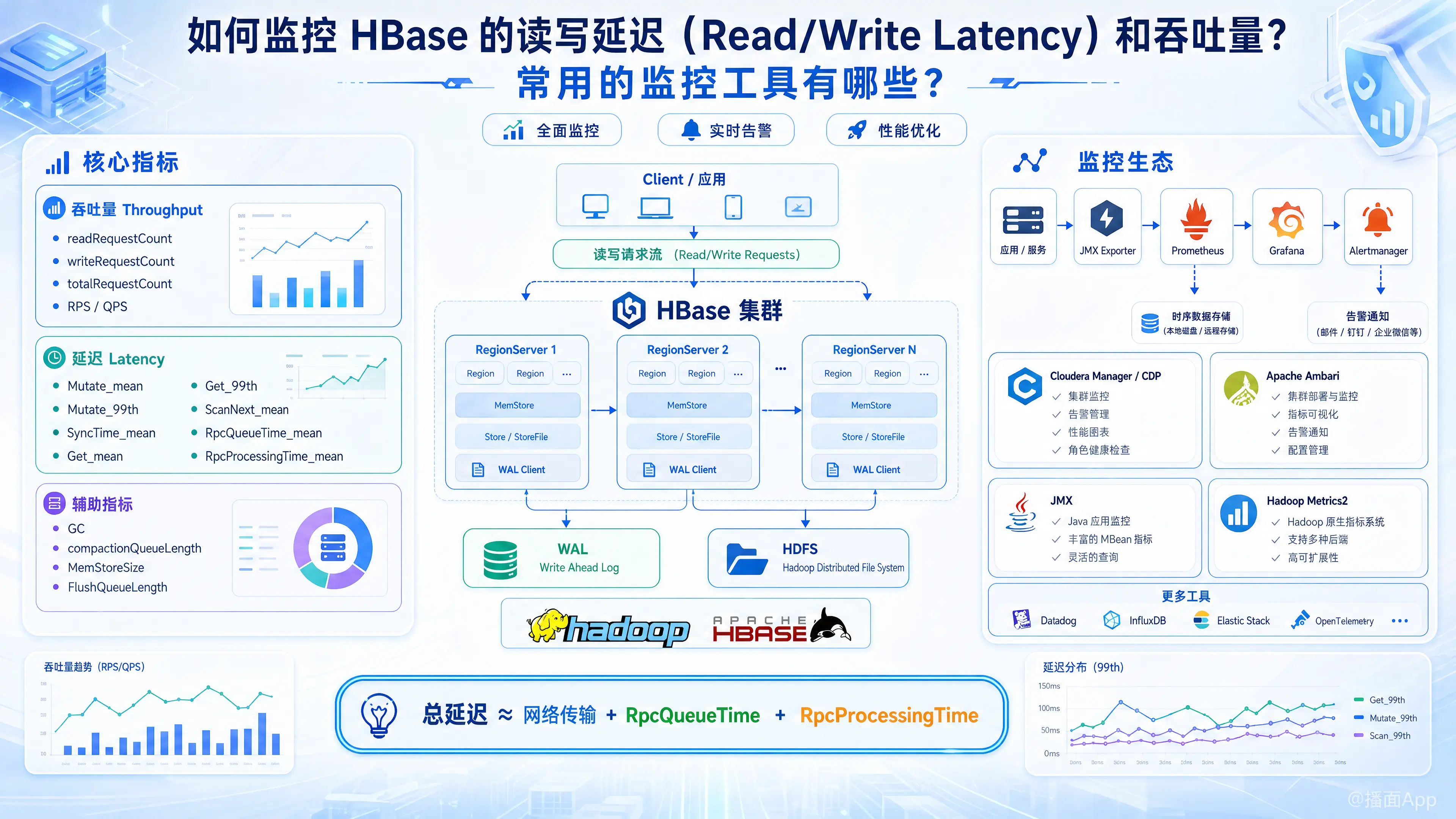
监控 HBase 的读写延迟(Latency)和吞吐量(Throughput)是保障大数据实时/离线业务稳定性的核心工作。HBase 本身通过 Hadoop Metrics2 框架和 JMX(Java Management Extensions)暴露了非常丰富的内部运行指标。
以下是关于监控哪些核心指标、如何实施监控以及常用监控工具的详细指南。
一、 核心监控指标解析
HBase 的监控重点主要集中在 RegionServer 上,因为它是实际处理读写请求的组件。
1. 吞吐量指标(Throughput)
主要监控 RPS/QPS(每秒请求数):
readRequestCount:读取请求总数(可计算每秒 Get/Scan 的数量)。writeRequestCount:写入请求总数(可计算每秒 Put/Delete 的数量)。totalRequestCount:总请求数。- 注意:这些指标可以聚合到集群级别,也可以细化到 RegionServer 甚至单个 Region 级别(用于排查数据倾斜/热点问题)。
2. 读写延迟指标(Latency)
HBase 的 JMX 提供了多种请求类型的延迟统计(包含平均值、95线、99线等):
- 写入延迟:
Mutate_mean/Mutate_99th_percentile:Put 和 Delete 操作的延迟。SyncTime_mean:WAL(预写日志)同步到 HDFS 的延迟。这是导致 HBase 写入延迟高的最常见原因。
- 读取延迟:
Get_mean/Get_99th_percentile:单行 Get 请求的延迟。ScanNext_mean/ScanNext_99th_percentile:Scan(扫描)请求的延迟。
- 队列与 RPC 延迟:
RpcQueueTime_mean:请求在 RegionServer 队列中排队等待处理的时间。(如果很高,说明服务端处理不过来了,或者 Handler 线程数不够)。RpcProcessingTime_mean:服务器实际处理请求的时间。- (总延迟 = 网络传输 + RpcQueueTime + RpcProcessingTime)。
3. 辅助排查指标(极大影响延迟)
- GC 指标:YGC 次数与时间,FGC(Full GC)次数与时间(Full GC 会导致 Stop-The-World,直接引发延迟毛刺)。
- Compaction 队列:
compactionQueueLength(如果队列过长,会导致读写性能严重下降)。 - Memstore 命中与 Flush:
MemStoreSize、FlushQueueLength。
二、 常用的监控工具(监控生态)
目前业界监控 HBase,最常用的是以下几种架构和工具:
1. Prometheus + Grafana(目前最主流、最推荐的开源方案)
- 原理:利用 JMX Exporter(一个 Java Agent)将 HBase 的 JMX 指标抓取并转换为 Prometheus 格式,Prometheus 定时拉取数据,最后通过 Grafana 进行大屏展示。
- 优点:生态极好、开源免费、告警规则灵活(Alertmanager)、社区有大量现成的 Grafana 面板(Dashboard)。
2. Cloudera Manager (CDP) / Apache Ambari(企业级 Hadoop 发行版自带)
- 原理:如果你使用的是 CDH/CDP 或 HDP 商业/开源发行版,它们自带完善的监控系统。
- 优点:开箱即用,无需额外配置,图形化界面友好,不仅能监控还能做集群管理和参数下发。
- 缺点:重量级,与特定的发行版深度绑定。
3. 商业 APM / 云原生监控工具
- Datadog / Dynatrace / New Relic:商业级监控工具,提供官方的 HBase 集成插件,配置极其简单,且拥有强大的机器学习异常检测能力。
- 阿里云 CloudMonitor / AWS CloudWatch:如果你使用的是云厂商的托管 HBase(如阿里云 Lindorm/HBase),直接看云监控控制台即可。
4. OpenTSDB (传统方案)
- 原理:HBase 官方原生支持将 Metrics2 数据推送到 OpenTSDB(一个基于 HBase 自身的时间序列数据库)。
- 优点:无需 JMX 转换,原生集成度高。
- 缺点:OpenTSDB 社区不活跃,UI 简陋,目前已逐渐被 Prometheus 淘汰。
5. HBase 自带的原生 UI
- Master UI:默认端口
16010。可以直观看到各 RegionServer 的请求数(Requests Per Second)。 - RegionServer UI:默认端口
16030。可查看当前节点的读写吞吐量、内存使用、BlockCache 命中率等。
三、 监控搭建实战:Prometheus + Grafana 方案简述
如果你想自己从零搭建监控,可以遵循以下步骤(以 JMX Exporter 为例):
Step 1: 下载 JMX Exporter
下载 jmx_prometheus_javaagent.jar 到所有 HBase 节点。
Step 2: 准备 JMX 配置文件 (hbase-jmx.yaml)
由于 HBase JMX 指标非常多,需要过滤:
lowercaseOutputName: true
lowercaseOutputLabelNames: true
rules:
- pattern: Hadoop<service=HBase, name=RegionServer, sub=Server><>([^:]+)
name: "hbase_regionserver_$1"
- pattern: Hadoop<service=HBase, name=RegionServer, sub=IPC><>([^:]+)
name: "hbase_ipc_$1"
# 可以添加更多正则规则...Step 3: 修改 HBase 启动参数
编辑 hbase-env.sh,注入 Java Agent:
export HBASE_JMX_OPTS="-javaagent:/path/to/jmx_prometheus_javaagent.jar=7070:/path/to/hbase-jmx.yaml"
export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS $HBASE_JMX_OPTS"
export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS $HBASE_JMX_OPTS"重启 HBase 集群。此时访问 http://<regionserver-ip>:7070/metrics 即可看到暴露的指标。
Step 4: 配置 Prometheus 抓取
在 prometheus.yml 中添加 Job:
scrape_configs:
- job_name: 'hbase'
static_configs:
- targets: ['rs1:7070', 'rs2:7070', 'master:7070']Step 5: Grafana 配置
在 Grafana 官网 (grafana.com/dashboards) 搜索 "HBase",下载一个 ID(例如 ID: 13204 或 10521),导入即可看到精美的读写延迟和吞吐量图表。
四、 监控中的“坑”与避坑指南
- 区分客户端延迟与服务端延迟:
- HBase 服务端 JMX 暴露的延迟(如
Mutate_mean)不包含网络传输时间和客户端处理时间。 - 如果客户端觉得慢,但服务端监控显示延迟很低(<5ms),通常问题出在网络带宽打满、网络丢包或者客户端自身的 GC/线程池拥堵。因此,除了监控 HBase,务必在你的 Java 客户端/业务层代码中埋点监控端到端延迟。
- HBase 服务端 JMX 暴露的延迟(如
- 警惕 P99 延迟(99th percentile):
- 看平均延迟(Mean)往往会掩盖问题。一定要监控 P99 甚至 P99.9 延迟。HBase 的毛刺(Spike)通常是由于 Java GC、HDFS 慢节点或 Compaction 引起的。
- 热点(Hotspotting)监控:
- 如果发现集群总吞吐量上不去,但只有某一台 RegionServer 的 CPU 和
RequestCount极高,说明出现了数据热点(RowKey 设计不合理)。需要下钻监控到 Region 级别。
- 如果发现集群总吞吐量上不去,但只有某一台 RegionServer 的 CPU 和