什么是 Apache Phoenix?它是如何让 HBase 支持标准的 SQL 查询和二级索引的?
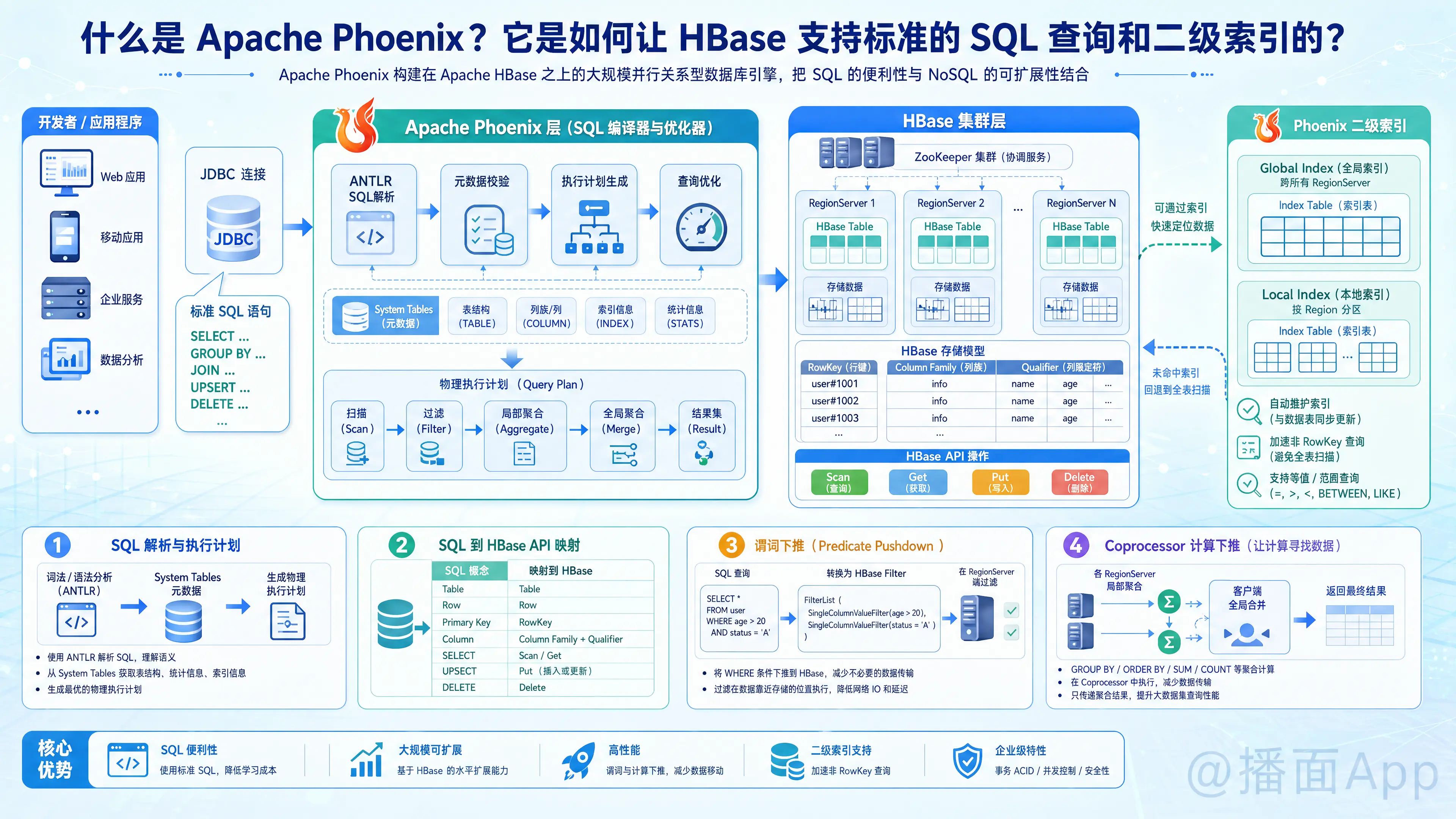
什么是 Apache Phoenix?
Apache Phoenix 是一个开源的、构建在 Apache HBase 之上的大规模并行关系型数据库引擎。
简单来说,你可以把 Phoenix 看作是 HBase 的一个“SQL 皮肤”或中间件。HBase 本身是一个 NoSQL 的键值对(Key-Value)数据库,只支持简单的 Get、Put、Scan 等基于 RowKey 的 API 操作。而 Phoenix 允许开发者使用标准的 JDBC API 和标准的 SQL 语句(如 SELECT、GROUP BY、JOIN 等)来操作 HBase 中的数据。
Phoenix 的核心理念是:“将 SQL 的便利性与 NoSQL 的可扩展性结合起来”。它主要面向低延迟的 OLTP(在线事务处理)和操作型分析场景,而不是像 Hive 那样面向纯粹的批处理。
Phoenix 是如何让 HBase 支持标准 SQL 查询的?
HBase 本身不理解 SQL。Phoenix 之所以能支持 SQL,是因为它在客户端和 HBase 之间充当了一个“SQL 编译器和优化器”的角色。它的实现原理主要依赖以下几个核心机制:
1. SQL 解析与执行计划生成
当通过 Phoenix 的 JDBC 驱动发送一条 SQL 语句时,Phoenix 客户端会做以下事情:
- 词法/语法分析:使用 ANTLR 解析 SQL 语句。
- 元数据校验:Phoenix 在 HBase 中维护了系统表(System Tables),用于存储表结构、列族、数据类型等元数据。Phoenix 会校验 SQL 中的表名和列名是否合法。
- 生成执行计划:Phoenix 将 SQL 转化为一系列针对 HBase 的原生操作(如
Scan和Get),并生成最优的物理执行计划。
2. SQL 到 HBase API 的映射
Phoenix 将关系型数据库的概念完美映射到了 HBase 的底层结构上:
- 表 (Table) 映射为 HBase 的 Table。
- 行 (Row) 映射为 HBase 的 Row。
- 主键 (Primary Key) 映射为 HBase 的 RowKey。
- 列 (Column) 映射为 HBase 的 Column Family + Column Qualifier。
SELECT映射为Scan或Get。UPSERT(Phoenix 插入/更新数据的语法)映射为Put。DELETE映射为Delete。
3. 谓词下推(Predicate Pushdown)
这是 Phoenix 高效查询的关键。如果你的 SQL 包含 WHERE age > 20,Phoenix 不会把所有数据拉到客户端再过滤,而是将这个条件转换为 HBase 的 Filter(过滤器)(如 SingleColumnValueFilter),推送到 HBase 的 RegionServer 端执行。只有符合条件的数据才会通过网络返回给客户端。
4. 利用 HBase Coprocessor(协处理器)进行计算下推
对于 GROUP BY、ORDER BY、聚合函数(如 SUM、COUNT)等复杂操作,HBase 原生 API 是不支持的。
Phoenix 利用了 HBase 的 Coprocessor(协处理器) 机制。你可以把协处理器看作是部署在 HBase 服务端的“存储过程”。
- Phoenix 将聚合计算的代码下发到各个 RegionServer 上。
- 每个 RegionServer 在本地遍历数据并进行局部聚合(例如计算本区域的
SUM)。 - 最后,Phoenix 客户端收集各个 RegionServer 的局部结果,进行最终的全局合并。
- 这种“让计算寻找数据”的方式大大减少了网络传输,极大提升了查询性能。
Phoenix 是如何让 HBase 支持二级索引的?
痛点: HBase 默认只对 RowKey(行键) 建立索引。如果你的查询条件不是 RowKey(例如 SELECT * FROM user WHERE name = '张三'),HBase 只能进行全表扫描(Full Scan),这在海量数据下是灾难性的。
Phoenix 的解决方案: 通过自动创建和维护索引表来实现二级索引。
1. 二级索引的分类
Phoenix 支持多种类型的二级索引,以应对不同的场景:
- 全局索引 (Global Index): 适用于读多写少的场景。Phoenix 会在 HBase 中创建一张独立的物理表作为索引表。索引表的 RowKey 通常由“被索引的列值 + 原表 RowKey”组成。查询时,先查索引表拿到原表 RowKey,再去原表获取数据。
- 本地索引 (Local Index): 适用于写多读少或存储空间受限的场景。索引数据和原表数据存储在同一个 Region 中。这样写入时没有跨节点的网络开销,但查询时可能需要扫描所有的 Region。
- 覆盖索引 (Covered Index): 这是一种优化手段。在创建索引时,通过
INCLUDE关键字将查询需要返回的其他列也冗余存储到索引表中。这样查询时,只需读取索引表就能拿到所有需要的数据,无需回表(查原表),性能极高。
2. 索引的自动同步机制(如何保证数据一致性?)
当你往原表写入或删除数据时,Phoenix 是如何保证索引表也被更新的呢?这依然归功于 HBase 的 Coprocessor(协处理器)机制。
- 拦截写入操作: Phoenix 在原表上挂载了特定的 Coprocessor(如
IndexRegionObserver,相当于关系型数据库的触发器 Trigger)。 - 计算索引更新: 当客户端向原表发起
UPSERT或DELETE操作时,Coprocessor 会在数据真正落盘前(prePut/preDelete阶段)拦截这个请求。 - 双写机制: Coprocessor 会根据原表的数据变化,自动计算出索引表需要发生的变化,然后在服务端自动构建对索引表的
Put或Delete请求,并将其与原表的更新在同一个批次/事务中执行。 - 透明性: 对开发者而言,这个过程是完全透明的。你只需要用 SQL 往原表插入数据,Phoenix 会自动维护背后的 HBase 索引表。查询时,Phoenix 的优化器也会自动判断是否可以使用索引表来代替扫描原表。
总结
Apache Phoenix 通过巧妙地结合 SQL 语法解析引擎、HBase Filter 机制 和 HBase 协处理器 (Coprocessor),硬是在一个纯粹的 KV 存储系统之上,构建出了一个支持复杂 SQL 查询、聚合计算和二级索引的现代关系型数据库层。