为什么 HBase 表中的数据量过大时,会发生频繁的 HStore/Region 阻塞现象?
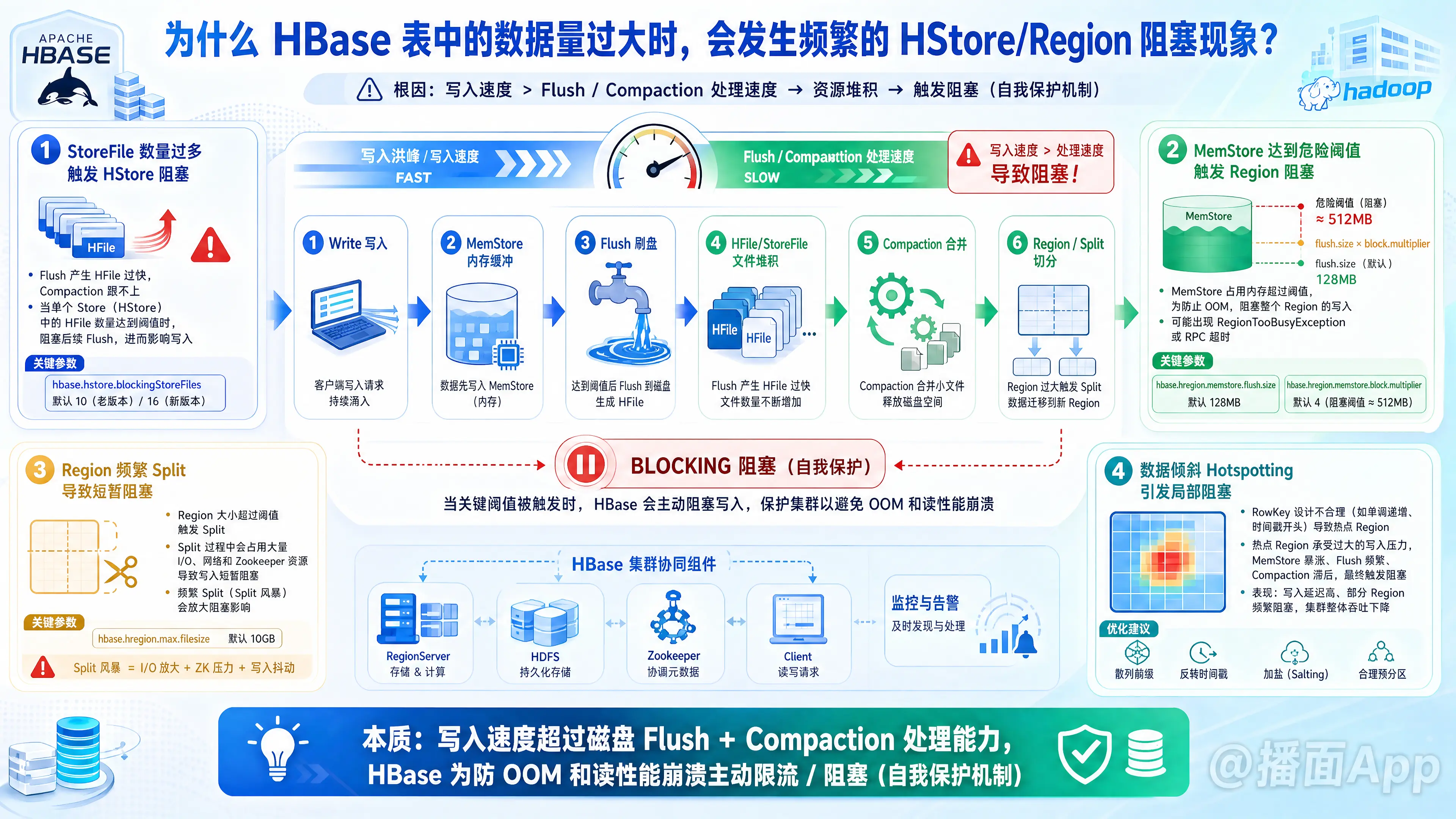
在 HBase 中,当表的数据量过大或写入并发极高时,发生频繁的 HStore/Region 阻塞(Blocking) 现象,本质上是 HBase 的一种自我保护机制。
简单来说:写入的速度超过了底层磁盘处理(Flush 和 Compaction)的速度,为了防止内存溢出(OOM)或读性能急剧下降,HBase 主动暂停了该 Region 的写入。
具体原因可以沿着 HBase 的写入链路(Write -> MemStore -> Flush -> HFile -> Compaction)逐步拆解为以下几个核心因素:
1. StoreFile 数量过多触发 HStore 阻塞(最常见原因)
这是导致 HStore 阻塞最直接的原因。
- 机制:当 HBase 接收写入请求时,数据先写入内存(MemStore)。当 MemStore 写满后,会刷写(Flush)到磁盘,生成一个个的 HFile(StoreFile)。为了保证查询性能,HBase 会在后台执行 Compaction(合并),将多个小 HFile 合并成大 HFile。
- 瓶颈:当数据量极大、写入极快时,Flush 产生 HFile 的速度远远超过了后台 Compaction 合并 HFile 的速度。
- 触发阻塞:当一个 HStore 中的 HFile 数量达到了配置参数
hbase.hstore.blockingStoreFiles(默认值通常是 10 或 16)时,HBase 会认为此时如果继续 Flush,会导致底层文件过多,严重拖垮读性能。因此,HBase 会阻塞后续的 Flush 操作,并强制等待 Compaction 运行。 - 连锁反应:Flush 被阻塞后,内存中的 MemStore 无法清空,随着新数据不断写入,MemStore 迅速膨胀,进而触发内存级别的阻塞。
2. MemStore 达到危险阈值触发 Region 阻塞(内存级别)
- 机制:每个 Region 有一个标准的 MemStore 刷写阈值
hbase.hregion.memstore.flush.size(默认 128MB)。达到该值会触发正常的异步 Flush。 - 触发阻塞:如果由于上述的 HStore 阻塞,或者磁盘 I/O 极慢,导致 MemStore 无法及时 Flush,而前端依然有海量数据涌入,MemStore 的大小会继续飙升。
- 自我保护:当 MemStore 的大小达到
hbase.hregion.memstore.flush.size×hbase.hregion.memstore.block.multiplier(默认乘积为 128MB × 4 = 512MB 或更大)时,HBase 为了防止 RegionServer 内存被撑爆(OOM),会彻底阻塞该 Region 的所有写入请求,直到 Flush 完成。此时客户端会看到大量的RegionTooBusyException或 RPC 超时。
3. Region 频繁 Split(分裂)导致短暂阻塞
- 机制:当一个 Region 内的所有 HFile 总大小超过
hbase.hregion.max.filesize(默认 10GB)时,Region 会发生 Split,一分为二。 - 触发阻塞:在数据量猛增的过程中,会频繁触发 Region Split。虽然 Split 过程很快,但在切分期间,父 Region 需要下线(Offline),此时针对该 Region 的读写请求会被短暂阻塞。如果发生 "Split 风暴"(大量 Region 同时分裂),会消耗大量系统资源(I/O 和 Zookeeper 请求),加剧整个 RegionServer 的阻塞。
4. 产生了数据倾斜(Hotspotting / 热点问题)
- 现象:如果 RowKey 设计不合理(例如使用时间戳开头、单调递增的 ID),海量的数据会涌入 HBase 集群中的某一个或某几个特定的 Region。
- 后果:即使集群有 100 台机器,但也只有 1 台机器在拼命工作。这台机器上的热点 Region 会迅速经历 MemStore 撑爆、HFile 激增、疯狂 Compaction 和 Split。由于单台机器的 CPU 和磁盘 I/O 达到极限,不可避免地会发生严重的 HStore 阻塞。
5. JVM 垃圾回收(GC)引起的 Stop-The-World
- 当数据量极大时,内存中会频繁产生和销毁大量的 Java 对象(RPC 缓冲、MemStore 数据块)。
- 这会给 RegionServer 的 JVM 带来巨大的垃圾回收压力。如果触发了 Full GC,会发生 Stop-The-World(STW)暂停。在 STW 期间,RegionServer 假死,不仅阻塞写入,甚至可能因为 Zookeeper session 超时导致 RegionServer 宕机(Aborted)。
💡 如何缓解或解决这个问题?
如果在业务中遇到了频繁的阻塞,可以从以下几个方面入手调优:
调整配置参数(治标):
- 适当调大
hbase.hstore.blockingStoreFiles(例如从 10 调到 50 甚至 100),允许积累更多的 HFile,给 Compaction 喘息的时间。 - 调大
hbase.hregion.memstore.block.multiplier(如设为 8),提高内存容忍度。 - 注意:这会牺牲一定的读取性能和增加内存溢出风险。
- 适当调大
优化 Compaction 和 Flush(提升处理能力):
- 增加 Compaction 线程数:
hbase.regionserver.thread.compaction.small和large。 - 将 HBase 的 HDFS 存储介质升级为 SSD,极大地提升 I/O 速度。
- 增加 Compaction 线程数:
解决热点问题(治本):
- Pre-splitting(预分区):建表时提前划分好 Region,避免后期频繁 Split。
- RowKey 散列:对 RowKey 进行加盐(Salting)、哈希(Hashing)或反转(Reversing),确保海量写入请求均匀打散到所有 RegionServer 上。
批量与异步写入:
- 客户端使用
BufferedMutator批量写入数据,减少 RPC 交互开销。 - 如果是离线海量数据导入,千万不要直接 Put,应该使用 BulkLoad 技术(直接在 MapReduce/Spark 中生成 HFile 并加载到 HBase),这可以完全绕过 MemStore 和 Flush 机制,绝对不会引发上述阻塞。
- 客户端使用
右滑查看面试常问