讲讲HBase 内部的负载均衡器(Load Balancer)及其工作原理,常用的均衡策略有哪些?
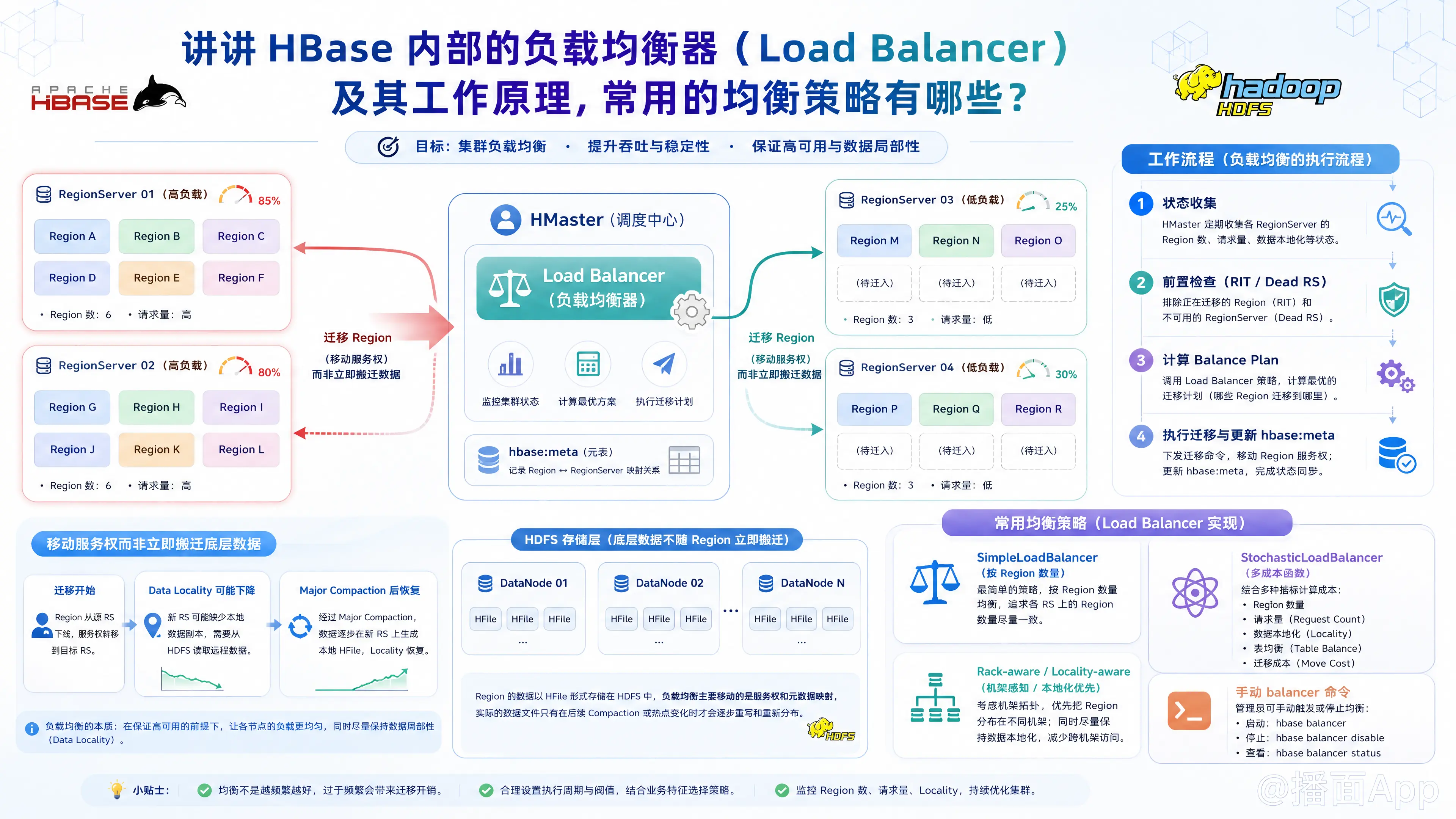
在 HBase 中,负载均衡器(Load Balancer)是确保整个分布式数据库集群高效、稳定运行的核心组件。由于数据写入、Region 分裂(Split)、节点宕机或新节点加入等原因,HBase 集群中的 Region 分布不可避免地会出现不均衡的现象。如果某些 RegionServer 承载了过多的 Region 或过高的读写请求,就会产生“热点”,导致系统性能下降。
HBase 的 Load Balancer 就是为了解决这个问题而存在的。下面为您详细讲解它的内部工作原理及常用的均衡策略。
一、 Load Balancer 的工作原理
HBase 的负载均衡是由 HMaster 节点负责调度和执行的。它作为一个后台线程(Chore)周期性地运行,或者由管理员手动触发。
1. 工作流程(Step-by-Step)
- 状态收集(Cluster State Snapshot):
HMaster 会收集当前集群的状态信息,包括:存活的 RegionServer 列表、每个 RegionServer 上分配了哪些 Region、每个 Region 的读写请求量、StoreFile 大小、数据本地化率(Data Locality)等。 - 前置检查(Pre-check):
在真正开始计算之前,HMaster 会进行一些安全检查:- 集群中是否有死节点(Dead RegionServers)尚未处理完毕?
- 是否有 Region 处于过渡状态(Region In Transition, RIT)?
- 如果有上述情况,均衡器通常会被跳过,以保证集群状态的稳定性。
- 计算均衡计划(Calculate Balance Plan):
HMaster 将收集到的集群状态交给配置的 LoadBalancer 策略算法。算法经过计算后,生成一个均衡计划(Balance Plan)。均衡计划本质上是一个包含多个 Region 移动指令的列表(例如:将 Region A 从节点 X 移动到节点 Y)。 - 执行计划(Execute Plan):
HMaster 开始根据计划移动 Region:- HMaster 通知源 RegionServer 关闭该 Region(Flush MemStore 到 HDFS,释放内存,更新元数据)。
- HMaster 通知目标 RegionServer 打开该 Region。
- 更新
hbase:meta表中的 Region 路由信息。
2. 关键特性:计算与存储分离
在 HBase 中,“移动 Region”是一个非常轻量级的操作。因为 HBase 底层依赖 HDFS,移动 Region 并不会立即跨网络复制底层的 HFile 数据块。它仅仅是把该 Region 的“服务权”从一台机器交给了另一台机器。
- 代价:移动 Region 后,目标 RegionServer 读取该 Region 数据的本地化率(Data Locality)会立刻降低(因为数据块还存在原来节点所在的数据节点上),这会导致短暂的读取性能下降。
- 恢复:当该 Region 触发下一次 Major Compaction(大合并) 时,HDFS 会将重写的数据块保存在新的 RegionServer 本地,从而恢复数据本地化率。
二、 常用的负载均衡策略
HBase 提供了多种负载均衡策略,可以通过 hbase-site.xml 中的 hbase.master.loadbalancer.class 参数进行配置。
1. SimpleLoadBalancer(简单负载均衡器)
- 核心思想:只看 Region 的数量。
- 原理:它计算集群中所有 Region 的总数,除以在线 RegionServer 的数量,得到一个平均值。然后将 Region 数量远超平均值的节点上的 Region,移动到 Region 数量低于平均值的节点上。
- 优点:算法极其简单,计算速度极快。
- 缺点:不考虑实际负载。10 个无人访问的“冷” Region 和 10 个读写极度频繁的“热” Region 在它眼里是一样的。这很容易导致数量均衡了,但 CPU 和 IO 依然严重不均。
- 适用场景:早期的 HBase 版本默认策略,现在基本已被淘汰。
2. StochasticLoadBalancer(随机/启发式负载均衡器)
这是 HBase 1.x 和 2.x 版本默认且最常用的策略。它极其强大且复杂。
- 核心思想:基于成本函数(Cost Functions)的启发式算法。
- 原理:
- 它将集群的当前状态抽象为一个“总成本(Total Cost)”,数值越低代表集群越均衡。
- 它内置了多个成本评估函数,例如:
- RegionCountSkewCostFunction:评估各个节点 Region 数量的倾斜程度。
- ReadRequestCostFunction / WriteRequestCostFunction:评估各个节点读/写请求量的倾斜程度。
- StoreFileCostFunction / MemStoreSizeCostFunction:评估存储大小和内存占用的倾斜程度。
- LocalityCostFunction:评估数据本地化率(尽量避免因为移动 Region 导致本地化率降得太低)。
- 这些函数都有各自的权重(Multiplier),总成本是这些成本乘以权重的加权总和。
- 随机变异(Mutation):算法会随机尝试成千上万次“变异”(例如随机挑选两个节点交换 Region,或把一个 Region 移到另一个节点),然后重新计算总成本。如果变异后的总成本下降了,就保留这次变异。
- 经过设定的最大迭代时间(默认很短,几百毫秒到几秒)后,输出找到的成本最低的最优解,作为 Balance Plan。
- 优点:极其全面,兼顾了数量、读写热点、存储压力、数据本地性等所有核心指标。
- 缺点:算法有一定随机性,且在大规模集群中计算开销略大。
3. RSGroupBasedLoadBalancer(基于 RegionServer 分组的均衡器)
- 核心思想:多租户与资源隔离。
- 原理:HBase 支持将 RegionServer 划分为不同的逻辑组(RSGroup)。例如,将一组服务器专门用于在线实时交易(OLTP),另一组专门用于离线分析(OLAP)。这个均衡器只会在这一个 RSGroup 的内部进行负载均衡,绝不会把跨组移动 Region。
- 适用场景:多租户环境,需要严格的硬件资源隔离的大型集群。
4. FavoredNodeLoadBalancer(偏好节点负载均衡器)
- 核心思想:深度绑定 HDFS 的块位置,追求极致的本地化率和容灾。
- 原理:为每个 Region 指定 3 个“偏好节点”(Favored Nodes:Primary, Secondary, Tertiary)。当向 HDFS 写数据时,强制 HDFS 将这 3 个副本写在这 3 台机器上。当发生负载均衡或节点宕机时,HMaster 优先(甚至强制)将 Region 分配给这 3 个节点中的可用节点。
- 优点:能够保持极高的数据本地化率,即使 Primary 节点挂了,Region 转移到 Secondary 节点后,依然有 100% 的本地化率。
- 缺点:维护复杂,与 HDFS 的耦合度极高。
三、 生产环境中的最佳实践与避坑指南
- 避免在业务高峰期自动均衡:
虽然 StochasticLoadBalancer 会尽量降低影响,但移动 Region 依然会造成瞬间的停顿(客户端需要重试)和短暂的性能下降(失去本地化率)。
建议:关闭 HMaster 的自动均衡(在 HBase Shell 中执行balancer_switch false),使用 Cron 定时任务在夜间业务低谷期通过 Shell 脚本触发balancer命令。 - 关注 Region in Transition (RIT):
如果集群中有长时间处于 RIT 状态的 Region,负载均衡器会罢工。在手动执行balancer前,务必先排查并修复 RIT 问题。 - 配合 Major Compaction:
在夜间低谷期,通常的运维流程是:先执行 Balancer 均衡集群 -> 接着执行 Major Compaction。这样可以将被转移的 Region 数据迅速合并到新节点本地,在第二天高峰期到来前恢复 100% 的数据本地化率。 - 调整权重治理特定的“热点”:
如果你发现 StochasticLoadBalancer 没有解决你的读写热点问题,可以去hbase-site.xml中调高hbase.master.balancer.stochastic.readRequestCost或writeRequestCost的参数权重,让算法对读写倾斜更加敏感。
右滑查看面试常问