为什么 HBase 底层选择 LSM-Tree(Log-Structured Merge-Tree)作为存储引擎,而不是 B+ Tree?
HBase 底层选择 LSM-Tree(Log-Structured Merge-Tree) 而不是传统关系型数据库常用的 B+ Tree,主要是由 HBase 的设计目标(海量数据、极高并发写) 以及其 底层依赖的存储系统(HDFS)的物理特性 共同决定的。
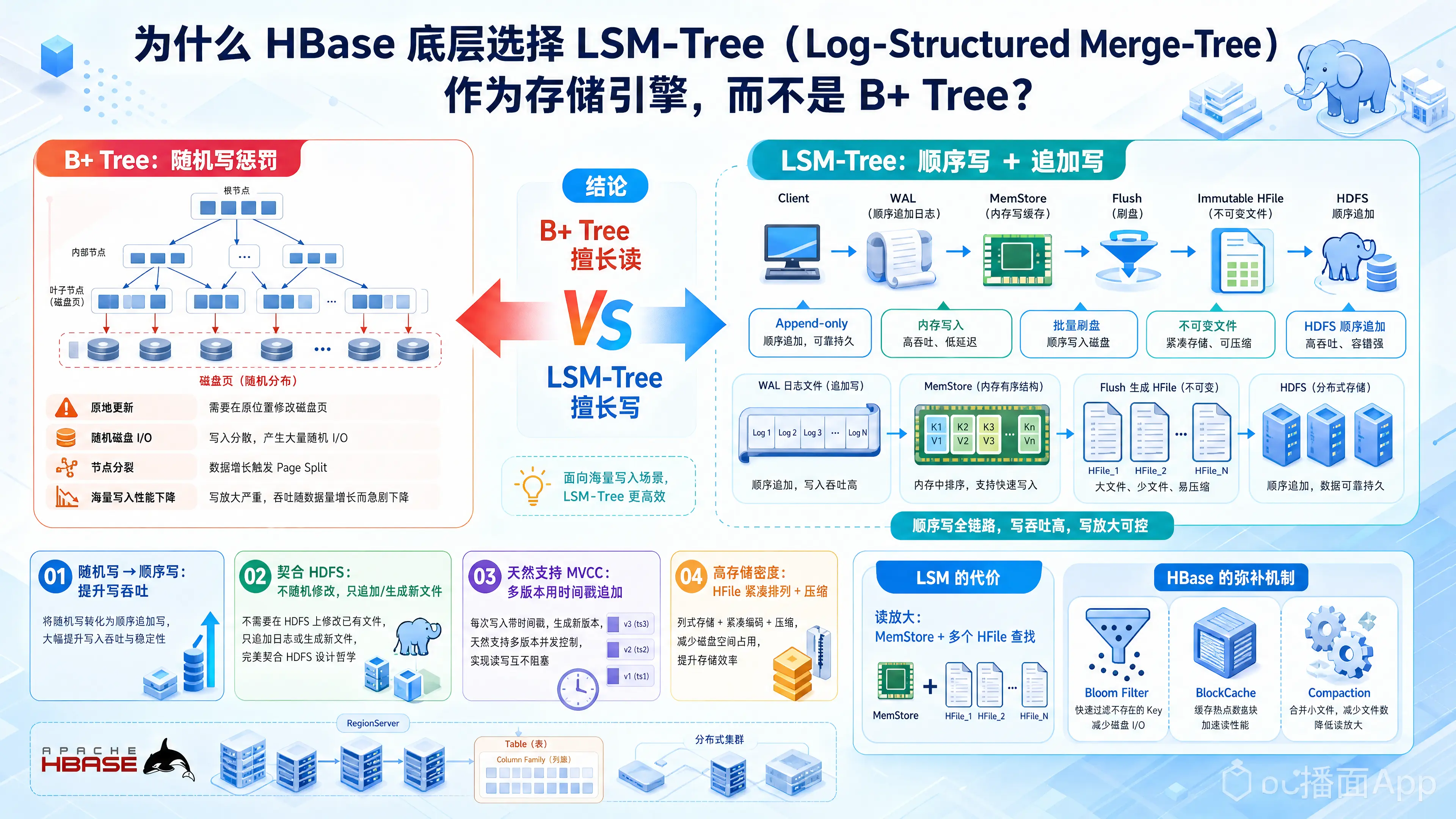
简单来说,B+ Tree 擅长读,而 LSM-Tree 擅长写。
以下是具体的深度对比和原因分析:
1. 核心瓶颈:随机写 vs 顺序写
- B+ Tree 的困境(随机写惩罚):
B+ Tree 是一种“原地更新(In-place update)”的数据结构。当海量数据进行随机写入时,B+ Tree 会产生大量的随机磁盘 I/O。此外,插入数据可能会导致节点分裂(Page Split),这不仅加剧了 I/O 负担,还会产生写放大。当数据量远大于内存,缓存命中率下降时,B+ Tree 的写入性能会呈现断崖式下跌。在机械硬盘时代,随机寻道的时间成本是极其昂贵的。 - LSM-Tree 的破局(顺序写转化为随机写):
LSM-Tree 的核心思想是“追加写(Append-only)”。无论是插入、修改还是删除(删除其实是插入一条带 Tombstone 标记的记录),在 LSM-Tree 中都只是在内存(MemStore)中进行操作,并顺序追加记录到日志(WAL)中。当内存满了之后,直接把内存里的数据 Flush 到磁盘,形成一个连续的、不可变的文件(HFile)。它将极其昂贵的磁盘随机写转换成了高效的磁盘顺序写,从而实现了极高的写入吞吐量。
2. 底层文件系统的限制:HDFS 的特性
这是一个专门针对 HBase 的极其重要的原因。
- HBase 构建在 HDFS 之上。HDFS 的设计初衷是存储超大文件,它的特性是支持顺序追加(Append),但不支持文件的随机修改(Random modification)。
- 如果 HBase 使用 B+ Tree,由于 B+ Tree 需要频繁在文件的任意位置进行节点的修改和分裂,这在 HDFS 上根本无法直接实现(除非将整个 Block 读入内存修改后再重写,这代价极其恐怖)。
- LSM-Tree 每次都是生成新的、不可变的小文件(HFile),这完美契合了 HDFS 不支持修改、只支持追加写入的物理特性。
3. 数据特性的契合:多版本与稀疏矩阵
- 多版本并发控制(MVCC): HBase 支持保留同一行的多个历史版本(基于 Timestamp)。B+ Tree 的原地更新天然不适合存储多版本数据;而 LSM-Tree 的 Append-only 特性,使得新版本数据只需要不断追加即可,旧版本数据在后续的合并(Compaction)过程中才会被清理,天然契合多版本的设计。
- 稀疏数据: HBase 是一个列族数据库,允许极度的稀疏性(空列不占用存储空间)。LSM-Tree 序列化为文件(HFile)时,只需记录有值的 Key-Value 对,非常紧凑。
4. B+ Tree 针对海量数据的存储效率问题
B+ Tree 为了保持树的平衡,其页(Page)通常会有一定的碎片率(比如 B-Tree 的利用率通常在 67% 左右)。在 PB 级别的海量数据下,这会浪费巨大的存储空间。而 LSM-Tree 刷写到磁盘上的 HFile 是紧密排列的,且不可修改,存储密度极高,非常适合配合各种压缩算法(如 Snappy, GZIP)进行极致压缩,大幅节省 HDFS 存储成本。
那么,LSM-Tree 牺牲了什么?HBase 是如何弥补的?
世界上没有免费的午餐,LSM-Tree 用极致的写入性能牺牲了部分读取性能(这被称为读放大 Read Amplification)。
在 B+ Tree 中,读取一条记录的时间复杂度是极度稳定的 。但在 LSM-Tree 中,读取一条数据可能需要先查内存(MemStore),再按时间倒序查找磁盘上的多个 HFile。
为了弥补 LSM-Tree 在查询上的短板,HBase 做了大量优化:
- 布隆过滤器(Bloom Filter): 可以在不读磁盘的情况下,快速判断某一行数据是否在某个 HFile 中,过滤掉绝大多数无效的磁盘 I/O。
- 块缓存(BlockCache): 将频繁访问的 HFile 数据块缓存在内存中,加速热点数据的读取。
- 后台合并(Compaction): 这是 LSM-Tree 的核心机制。HBase 会在后台不断将零散的小 HFile 合并成大 HFile(Minor/Major Compaction),清理掉过期或被删除的数据,从而减少查询时需要遍历的文件数量,将读性能拉回一个可接受的水平。
总结
如果把数据库比作仓库管理:
- B+ Tree 就像图书管理员,每次有新书(新数据),都要精准地找到书架上的位置(寻道),把旁边的书挪开(节点分裂),然后放进去。如果书架比房子大(数据大于内存),每天还要跑去外面的大仓库找位置,效率极低。
- LSM-Tree 则像是一个前台收发室。所有新来的书先堆在前台桌子上(MemStore),并做个记录(WAL)。桌子满了,就直接打个大包扔到仓库里(Flush 成 HFile)。等晚上闲的时候,再在后台把打包好的箱子重新整理归类(Compaction)。
对于像 HBase 这样面临海量日志、监控数据、物联网等“写多读少”或“极高并发写”场景的大数据利器,选择 LSM-Tree 是一种必然。
右滑查看面试常问