如何在 HBase 中使用过滤器(Filter)进行高效的数据检索?
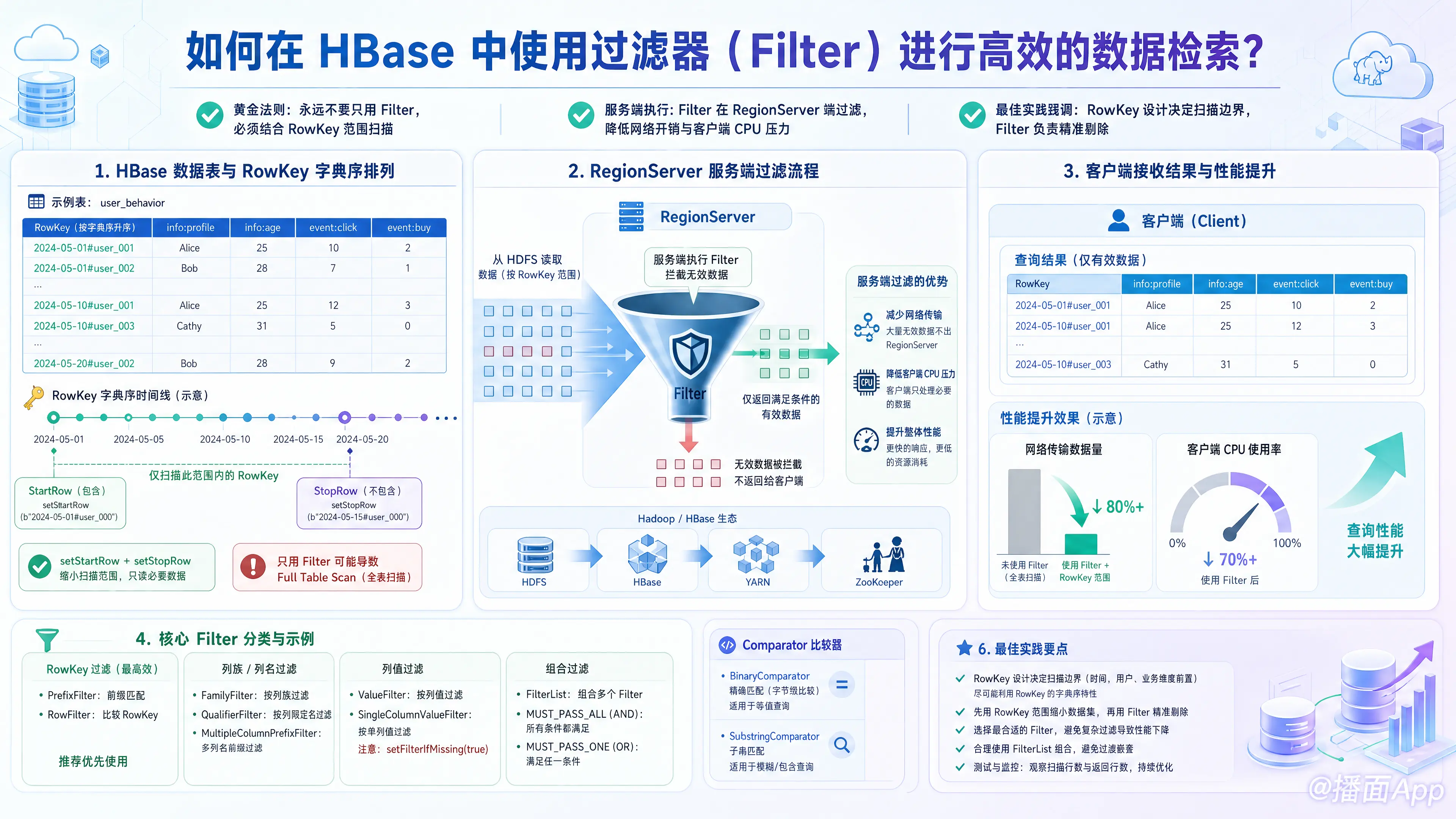
在 HBase 中,过滤器(Filter)是实现复杂查询和数据筛选的核心机制。HBase 的过滤器是在 RegionServer 端(服务端) 执行的,这意味着它可以将不符合条件的数据直接在服务端过滤掉,避免将无用数据传输到客户端,从而大幅降低网络开销和客户端的 CPU 压力。
但是,“使用过滤器”并不等于“高效”。如果不正确地使用,过滤器可能会导致全表扫描(Full Table Scan),造成严重的性能问题。
以下是在 HBase 中使用过滤器进行高效数据检索的完整指南和最佳实践:
一、 高效检索的“黄金法则”
在深入了解过滤器之前,必须牢记 HBase 的底层原理:HBase 唯一的索引是 RowKey(行键),且数据是按 RowKey 字典序排列的。
黄金法则: 永远不要只用 Filter,必须将其与 RowKey 的范围扫描(setStartRow 和 setStopRow)结合使用。
- 如果不设置 StartRow 和 StopRow,即使加了 Filter,HBase 也会逐行扫描整张表。
- 高效的做法:通过 RowKey 设计缩小扫描的上下界,然后在该有限的数据范围内使用 Filter 进行精准的数据剔除。
二、 常用的核心 Filter 及其应用场景
HBase 提供了丰富的内置 Filter,通常结合比较运算符(CompareOperator)和比较器(Comparator)使用。
1. RowKey 相关的 Filter(最高效)
虽然设置 Start/Stop Row 是首选,但在某些复杂场景下仍需使用 RowKey 过滤器。
PrefixFilter(前缀过滤器):匹配 RowKey 以特定前缀开头的行。- 场景:查询某个特定前缀的所有数据(如
userId_开头的日志)。 - 注意:底层已经做了优化,遇到不匹配的前缀会提前结束扫描,效率很高。
- 场景:查询某个特定前缀的所有数据(如
RowFilter(行键过滤器):对 RowKey 进行正则匹配或子串匹配。- 场景:RowKey 中包含特定字符(如
RowFilter(CompareOperator.EQUAL, new SubstringComparator("2023")))。
- 场景:RowKey 中包含特定字符(如
2. 列族与列名相关的 Filter
FamilyFilter:过滤特定的列族。QualifierFilter:过滤特定的列(Qualifier)。MultipleColumnPrefixFilter:同时匹配多个列名的前缀,这在宽表设计中提取特定几类属性时非常高效。
3. 列值相关的 Filter(最常用)
ValueFilter:针对全表所有的 Cell 的 Value 进行过滤(不区分是哪一列)。SingleColumnValueFilter(单列值过滤器):最常用的 Filter,相当于 SQL 中的WHERE col_name = 'value'。- 场景:判断某一行的特定列的值是否符合条件。如果不符合,则整行数据被过滤掉。
- 避坑指南:默认情况下,如果某一行不存在该列,该行会被包含在结果集中。必须调用
setFilterIfMissing(true)才能真正过滤掉缺少该列的行。
4. 组合过滤器(FilterList)
FilterList:用于将多个 Filter 组合起来,支持MUST_PASS_ALL(相当于 AND) 和MUST_PASS_ONE(相当于 OR)。
三、 比较器 (Comparator)
Filter 通常需要配合比较器来定义“如何匹配”:
BinaryComparator:精确匹配(字节数组级别)。SubstringComparator:子串匹配(包含该字符串即可)。RegexStringComparator:正则表达式匹配。BinaryPrefixComparator:前缀匹配。
四、 Java API 实战代码示例
假设我们有一个表,RowKey 格式为 [userId]-[timestamp]。我们需要查询 userId=1001,且在 info:status 列的值为 active 的所有记录。
import org.apache.hadoop.hbase.CompareOperator;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.*;
import org.apache.hadoop.hbase.util.Bytes;
public class HBaseFilterExample {
public void scanWithFilter(Connection connection) throws Exception {
Table table = connection.getTable(TableName.valueOf("user_table"));
// 1. 设置 Scan 的范围 (极其重要,避免全表扫描)
String userId = "1001";
Scan scan = new Scan();
scan.withStartRow(Bytes.toBytes(userId + "-"));
scan.withStopRow(Bytes.toBytes(userId + "-|")); // '|' 的 ASCII 码大于所有数字和字母
// 2. 为了减少网络传输,只读取需要的列族和列
scan.addColumn(Bytes.toBytes("info"), Bytes.toBytes("status"));
scan.addColumn(Bytes.toBytes("info"), Bytes.toBytes("data"));
// 3. 创建单列值过滤器: info:status = 'active'
SingleColumnValueFilter statusFilter = new SingleColumnValueFilter(
Bytes.toBytes("info"),
Bytes.toBytes("status"),
CompareOperator.EQUAL,
Bytes.toBytes("active")
);
// 【关键】如果该行没有 status 列,则丢弃该行
statusFilter.setFilterIfMissing(true);
// 4. (可选) 如果有多个条件,使用 FilterList
// FilterList filterList = new FilterList(FilterList.Operator.MUST_PASS_ALL);
// filterList.addFilter(statusFilter);
// filterList.addFilter(anotherFilter);
// 5. 将过滤器应用到 Scan
scan.setFilter(statusFilter);
// 6. 执行查询
try (ResultScanner scanner = table.getScanner(scan)) {
for (Result result : scanner) {
// 处理结果
System.out.println("Found row: " + Bytes.toString(result.getRow()));
}
}
table.close();
}
}五、 提升 Filter 性能的 6 大高级技巧
如果想让 Filter 跑得飞快,请严格遵守以下优化策略:
- FilterList 的顺序优化(Fail-Fast 机制)
在构建FilterList (MUST_PASS_ALL)时,把最严格的、最容易将数据过滤掉的 Filter 放在最前面。HBase 会按顺序评估 Filter,一旦前面的 Filter 不通过,后面的 Filter 就不会执行了,以此节省 CPU 资源。 - 善用
scan.addColumn()代替部分 Filter
如果你只是想要某些列的数据,不要使用QualifierFilter,而是直接调用scan.addColumn()或scan.addFamily()。直接在 Scan 层指定列,HBase 在读取底层 HFile 时会直接跳过不需要的数据块,效率远高于读取后用 Filter 过滤。 - 提取公共前缀优化(Hinting)
如果是非常复杂的行键过滤,可以利用Filter.getNextCellHint()机制(高级开发者可通过自定义 Filter 实现),告诉 RegionServer 直接跳过一大段不满足条件的 HFile Block,而不是逐行比较。 - 合理设置 Scan 缓存 (
setCaching和setBatch)scan.setCaching(int):设置一次 RPC 请求从服务端取回多少行(Row)。如果带了 Filter,很多行在服务端被抛弃,适当调大此值可以减少 RPC 次数。- 注意:不要设置太大,避免客户端 OOM。
- 避免使用耗时的比较器
RegexStringComparator(正则表达式比较器)非常消耗服务端 CPU 资源。在海量数据扫描时,尽量通过 RowKey 设计规避使用正则,或者改用简单的SubstringComparator或精确匹配。 - 自定义 Filter(终极方案)
如果内置 Filter 无法满足复杂的业务逻辑,或者组合 Filter 性能太差,你可以编写 Custom Filter(继承FilterBase)。- 缺点:需要将编译好的 Jar 包部署到所有 RegionServer 的 classpath 下并重启集群,运维成本较高。
总结
HBase 的 Filter 是一把双刃剑。“RowKey 范围扫描 + 精准的 Filter 剔除 + 指定需要的 Column” 是 HBase 复杂查询的标准高效套路。永远把利用 RowKey 的有序性放在第一位,把 Filter 作为数据提取的最后一道关卡。