客户读取 HBase数据时,什么是 Scan 操作的 Caching 和 Batching?
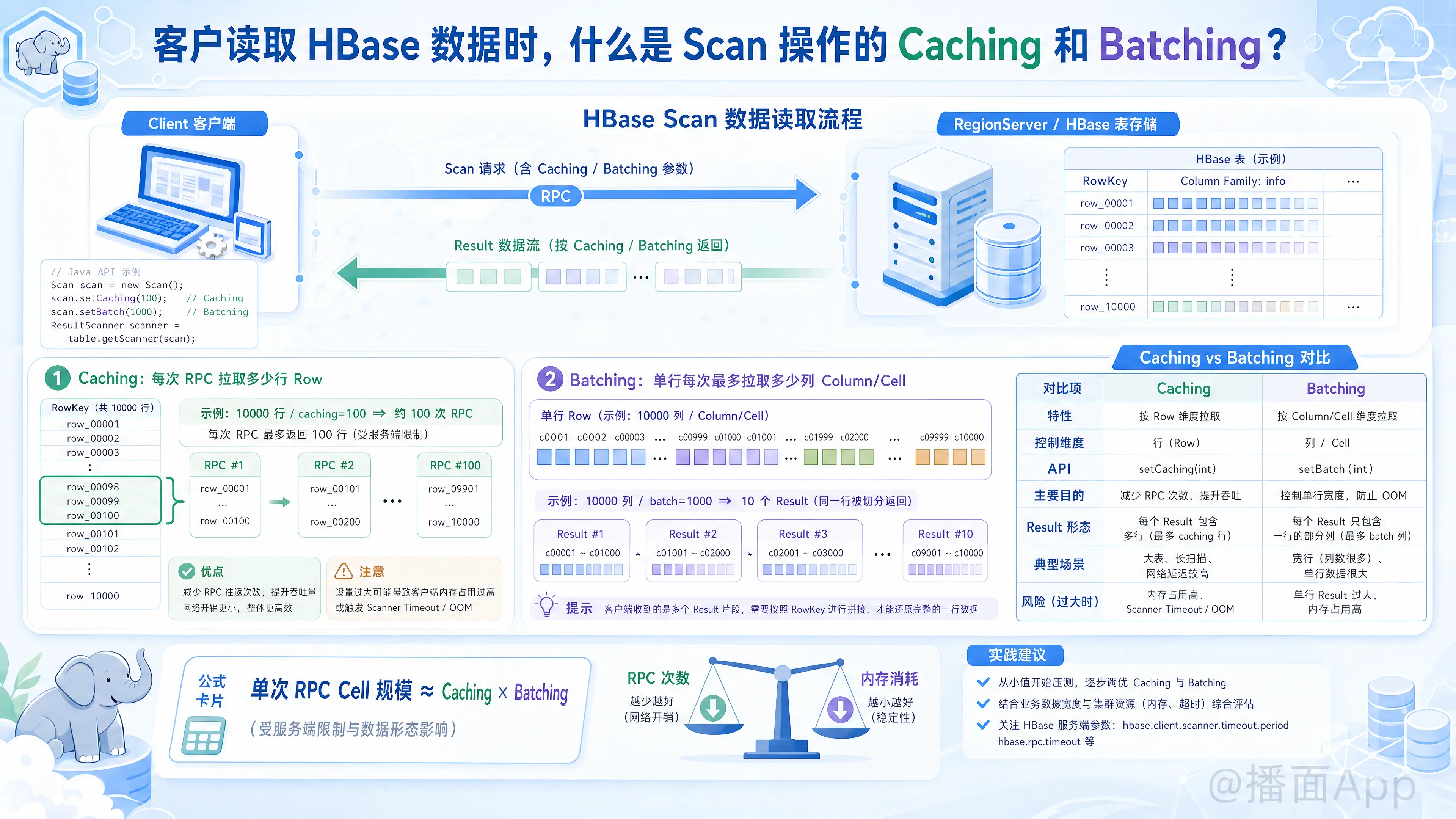
在 HBase 中,Scan 操作是用来批量读取多行数据的核心机制。由于 HBase 数据可能非常庞大,如果一次性将所有数据从服务端(RegionServer)拉取到客户端(Client),会导致网络拥堵甚至内存溢出(OOM)。
为了平衡 网络 RPC 次数 和 内存消耗,HBase 提供了两个极其重要的参数:Caching(缓存) 和 Batching(批处理)。
简单来说:Caching 是控制“行(Row)”维度的获取数量,而 Batching 是控制“列(Column/Cell)”维度的获取数量。
以下是详细解释:
1. Caching(基于“行”维度的优化)
- 定义:Caching 指的是客户端每次向服务端发起一次 RPC 请求时,最多拉取多少“行(Row)” 的数据。
- 对应 API:
scan.setCaching(int caching) - 作用机制:
- 假设你要扫描 10000 行数据,如果 Caching 设置为 100,客户端会向服务端发起 次 RPC 请求。每次请求带回 100 行数据放在客户端内存中遍历。
- 优点:增大 Caching 值可以显著减少客户端与服务端之间的网络 RPC 通信次数,从而提高全表或大范围扫描的速度。
- 风险:
- 如果 Caching 设置得太大,一次拉取的数据量过大,可能会导致客户端或服务端的内存溢出(OOM)。
- 同时,单次 RPC 处理时间变长,可能会触发 Scanner Timeout(扫描器超时)异常。
2. Batching(基于“列”维度的优化)
- 定义:Batching 指的是在读取某一行(Row)时,如果这一行非常宽(包含了成千上万个列/Cell),每次 RPC 请求最多拉取这一行中的多少“列(Column/Cell)”。
- 对应 API:
scan.setBatch(int batch) - 作用机制:
- HBase 是宽表模型,一行数据可能有上百万列。如果一次性把这一行的数据全部拉到客户端,内存肯定会撑爆。
- 假设某一行有 10000 个列,如果 Batching 设置为 1000。那么为了读取这一行的数据,客户端会产生 个
Result对象(相当于把一行数据拆成了 10 份返回)。
- 优点:专用于解决“超级宽表”或“单行数据量极大”的问题,防止读取单行数据时发生内存溢出。
- 风险:
- 如果业务逻辑期望一次拿到完整的一行数据进行计算,设置 Batching 后,开发者需要在客户端代码中自行拼接被拆分的行(判断 RowKey 是否相同)。
3. Caching 与 Batching 的对比与结合
可以用一个表格/二维矩阵来理解它们的区别:
| 特性 | Caching | Batching |
|---|---|---|
| 控制维度 | 行(Row)(纵向) | 列(Column/Cell)(横向) |
| API | setCaching(int) |
setBatch(int) |
| 解决的主要问题 | 减少网络 RPC 次数,提升吞吐量 | 防止单行数据过大导致内存溢出 |
| 默认值 | 依赖版本,早期为1,现在一般由服务端配置决定 | -1(无限制,即默认获取整行所有列) |
| 返回的结果集(Result) | 每一个 Result 代表完整的一行(如果不受Batch影响) | 每一个 Result 可能只是一行的部分列 |
结合使用的场景:
这两个参数可以一起使用,共同控制每次 RPC 返回的最大 Cell(单元格)数量。
单次 RPC 获取的 Cell 总数上限 = Caching × Batching
举例说明:
假设你设置scan.setCaching(10)和scan.setBatch(5)。
这意味着:每次 RPC 请求,客户端最多向服务端要 10 行数据;并且每一行最多只要 5 列数据。那么单次 RPC 请求最多返回 个 Cell。
4. 最佳实践(如何调优?)
- 常规情况(普通表):
- 数据行不宽(每行就几十列,几 KB),只需要调整 Caching。一般设置为
100到1000之间,具体取决于单行的大小和客户端可用内存。 - 不需要设置 Batching(保持默认)。
- 数据行不宽(每行就几十列,几 KB),只需要调整 Caching。一般设置为
- 极端情况(超大宽表):
- 如果某一行数据极大(比如每行几 MB 甚至几十 MB,包含大量列),必须设置 Batching。
- 此时可以把 Batching 设置为
100或500,同时把 Caching 设置小一点(比如1或10)。
- HBase 2.x 的新特性提醒:
- 在较新的 HBase 版本中,除了这两个参数,HBase 引入了按数据大小(Size)限制的机制(
scan.setMaxResultSize(long))。HBase 会智能判断,如果达到了指定的数据量大小(默认通常是 2MB),即使没有达到 Caching 设定的行数,也会提前返回数据,这大大降低了 OOM 的风险,减轻了手动微调 Caching 的负担。
- 在较新的 HBase 版本中,除了这两个参数,HBase 引入了按数据大小(Size)限制的机制(
右滑查看面试常问