线上 Kafka Topic 由于业务量增加扩容了几个 Partition。正在运行的 Flink 作业在不重启的情况下,能否自动发现并消费新 Partition 中的数据?如何配置?
是的,完全可以。
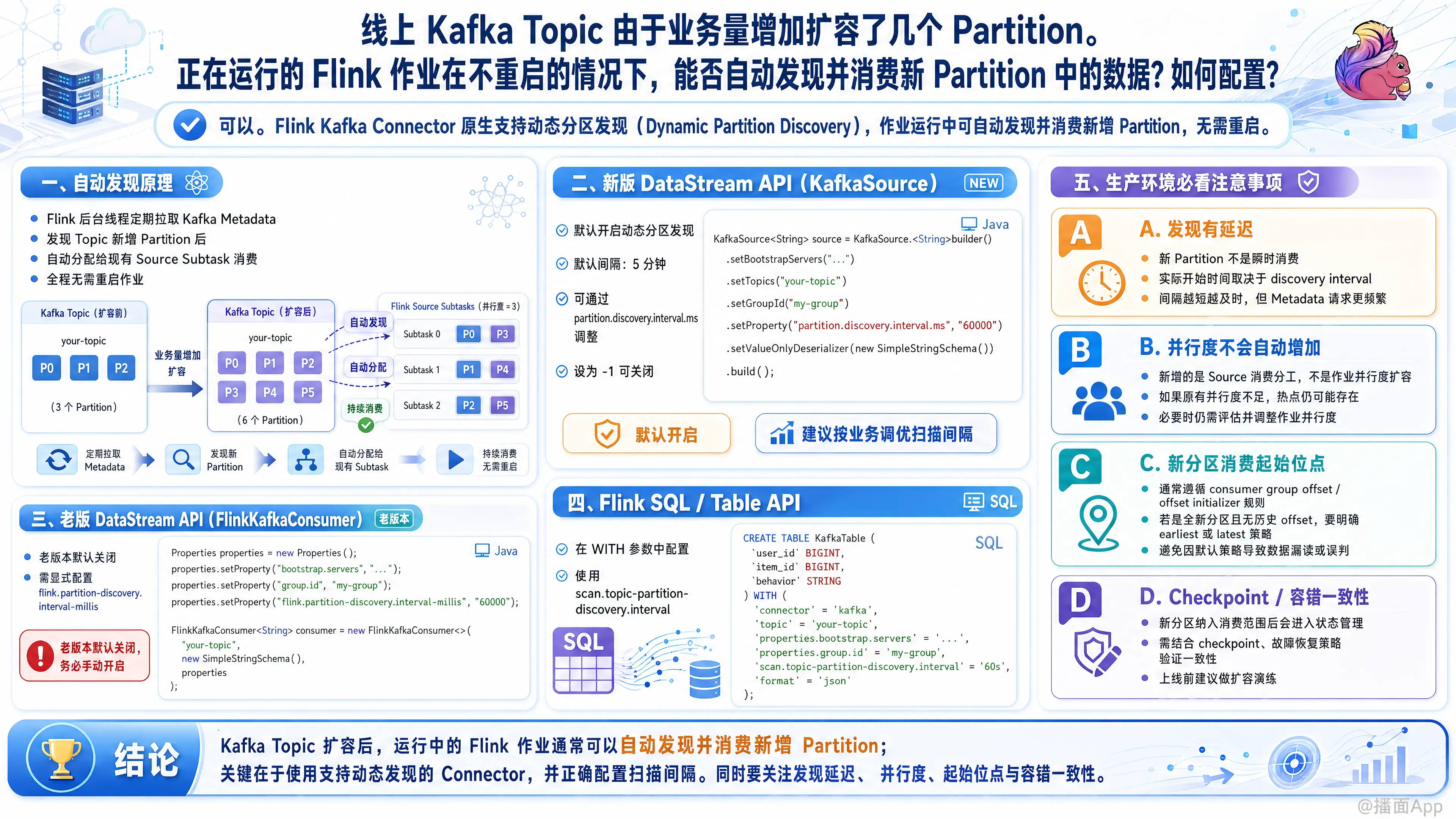
Flink 的 Kafka Connector 原生支持动态分区发现(Dynamic Partition Discovery)。只要配置得当,正在运行的 Flink 作业会通过一个后台线程定期向 Kafka 集群拉取最新的 Metadata。一旦发现 Topic 增加了新的 Partition,Flink 会自动将其分配给现有的 Source Subtask 进行消费,全程不需要重启作业。
以下是针对不同 Flink API 的具体配置方法,以及在生产环境中使用该特性的重要注意事项。
一、 如何配置自动发现?
根据你使用的 Flink API 版本不同,配置方式有所区别:
1. 新版 DataStream API (Flink 1.14+ 使用 KafkaSource)
在最新的 KafkaSource 中,分区发现是默认开启的,默认间隔为 5 分钟。你可以通过 setProperty 修改发现间隔时间:
java
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("...")
.setTopics("your-topic")
.setGroupId("my-group")
// 设置分区发现间隔为 60 秒 (60000 毫秒)
.setProperty("partition.discovery.interval.ms", "60000")
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();(注:如果想关闭自动发现,将该值设为 "-1" 即可)
2. 老版 DataStream API (Flink 1.14 之前使用 FlinkKafkaConsumer)
在老版本中,该功能默认是关闭的。需要在 Properties 中增加特定的配置项:
java
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "...");
properties.setProperty("group.id", "my-group");
// 设置分区发现间隔为 60 秒 (注意 Key 和新版不同)
properties.setProperty("flink.partition-discovery.interval-millis", "60000");
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>(
"your-topic",
new SimpleStringSchema(),
properties
);3. Flink SQL / Table API
在建表 DDL 的 WITH 语句中,配置 scan.topic-partition-discovery.interval 参数即可:
sql
CREATE TABLE KafkaTable (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING
) WITH (
'connector' = 'kafka',
'topic' = 'your-topic',
'properties.bootstrap.servers' = '...',
'properties.group.id' = 'my-group',
-- 设置动态发现分区的间隔时间,例如 60 秒
'scan.topic-partition-discovery.interval' = '60s',
'format' = 'json'
);二、 生产环境必看的 4 个“避坑”指南
虽然 Flink 能够不重启就发现新分区,但在生产环境中,直接扩容 Kafka 分区可能会带来连锁反应,请务必注意以下几点:
1. 性能瓶颈问题(极其重要)
- 现象: Flink 虽然发现了新分区,但作业的并发度(Parallelism)并不会动态增加。
- 影响: 假设你的 Kafka 分区从 3 扩容到 6,Flink Source 的并发度依然是 3。那么每个 Flink Subtask 将从原来消费 1 个分区变成消费 2 个分区,这可能会导致当前的 TaskManager 出现 CPU 或网络瓶颈。
- 建议: 如果业务量暴增导致现有 Flink 并发度处理不过来,最终还是需要通过 Savepoint 停止作业,调大 Source 的并发度(Parallelism),然后从 Savepoint 重新启动作业,才能真正利用到底层扩容带来的计算红利。
2. 新分区的消费起始位点
- 现象: 当 Flink 发现新的分区时,默认会从该新分区的最早位点(Earliest) 开始消费。
- 影响: 如果你的新分区里没有积压老数据,那没问题。但如果新分区产生了一段时间才被 Flink 发现,或者由于某些原因写入了历史数据,Flink 会将这些数据全量读入。
3. Watermark (水位线)乱序与延迟
- 现象: 如果你的作业严重依赖 Event Time 和 Watermark,新分区的加入可能会扰乱现有的 Watermark 推进。
- 影响: 因为新分区的消费进度可能与老分区不一致(特别是从最早位点开始读时),会导致整体任务的 Watermark 被这个新分区拖慢(取最小时间戳),从而导致下游窗口长时间不触发,引发状态(State)积压。
- 建议: 如果使用 Flink 1.14+,建议配置 Watermark Alignment(水位线对齐) 或开启 Idle Source(空闲数据源) 容忍机制,防止新分区或数据分布不均拖死整个作业。
4. 数据倾斜预警
- Kafka 扩容分区后,上游生产端(Producer)通常会使用 Hash 或 Round-Robin 写入新分区。在新老分区交替的瞬间,可能会导致特定 Key 的数据乱序,如果你的 Flink 作业对处理顺序有极严格的绝对保证要求(如 CDC 同步),扩容期间可能会短暂破坏严格的有序性。
总结
可以不重启自动发现,只需配置好 interval 参数。 但从长远的集群负载来看,如果是为了应对长期流量增长而扩容 Kafka,推荐的最佳实践依然是:找个低峰期 -> 打 Savepoint -> 调大 Flink 并发度 -> 重启 Flink 作业。
右滑查看面试常问