在Flink中,使用 StreamingFileSink(或 FileSink)向 HDFS/S3 写入实时日志,由于 Checkpoint 时间间隔很短,导致产生了成千上万的小文件,拖垮了 NameNode,如何解决小文件合并问题?
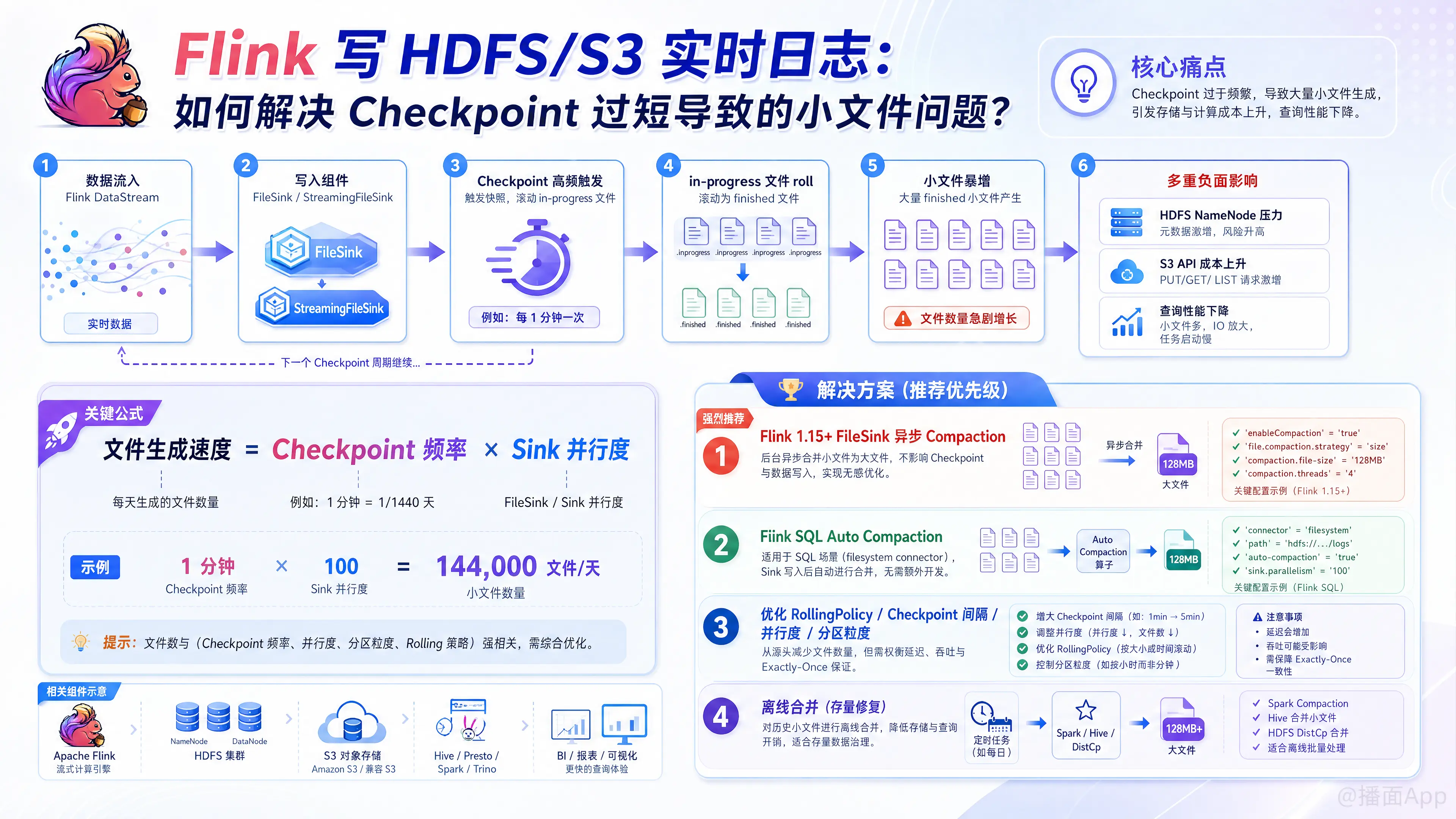
在 Flink 中,由于 Exactly-Once 语义的保证,StreamingFileSink(在较新版本中被替换为 FileSink)在每次 Checkpoint 触发时,都会强制将“进行中(in-progress)”的文件滚动(roll)并提交为“已完成(finished)”状态。
因此,文件生成速度 = Checkpoint 频率 × Sink 算子的并行度。如果 Checkpoint 间隔是 1 分钟,并行度是 100,那么每天将产生 144,000 个文件,这会迅速拖垮 HDFS NameNode 或导致 S3 API 请求费用飙升及查询性能下降。
解决这个问题,通常有以下几种方案,按推荐程度和技术栈从易到难排列:
方案一:使用 Flink 1.15+ 原生的 Sink 异步合并功能(强烈推荐)
如果你使用的是 Flink 1.15 及以上版本,Flink 官方终于在 DataStream API 的 FileSink 中内置了小文件合并(Compaction)功能。它会在文件写入后,异步地将多个小文件合并成大文件,并且不会影响 Checkpoint 的时长。
实现代码示例:
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.connector.file.sink.compaction.FileCompactStrategy;
// 1. 定义合并策略
FileCompactStrategy compactStrategy = FileCompactStrategy.Builder.newBuilder()
.setNumCompactThreads(2) // 合并线程数
.setSizeThreshold(128 * 1024 * 1024) // 目标文件大小 (例如 128MB)
.build();
// 2. 创建 FileSink 并启用合并
FileSink<String> sink = FileSink.forRowFormat(new Path("hdfs://namenode:8020/output"), new SimpleStringEncoder<String>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(1)) // Checkpoint 或时间间隔滚动
.build()
)
// 关键点:配置 compaction
.enableCompaction(compactStrategy, new RecordWiseFileCompactor<>(...))
.build();
dataStream.sinkTo(sink);方案二:Flink SQL 的 Auto Compaction(适用于 SQL API 场景)
如果你使用的是 Flink SQL,那么解决起来非常简单。Flink SQL 的 FileSystem Connector 原生支持自动合并小文件。底层原理是在 Sink 算子之后悄悄加了一个合并算子。
建表 DDL 配置:
CREATE TABLE hdfs_table (
id INT,
name STRING,
log_time TIMESTAMP(3)
) PARTITIONED BY (dt STRING, hr STRING) WITH (
'connector' = 'filesystem',
'path' = 'hdfs://namenode:8020/output/',
'format' = 'parquet',
-- 开启自动合并
'auto-compaction' = 'true',
-- 目标文件大小(默认 256MB)
'compaction.file-size' = '256MB'
);方案三:降低 Sink 算子的并行度(缓解方案)
如果不方便升级 Flink 或改写代码,最直接的缓解方法是减少最终写入文件的并发数。
例如,前面的算子并行度是 100(为了处理高吞吐运算),但在写入 HDFS 前,进行数据重分布(rescale 或 rebalance),将 Sink 的并行度设为 10。这样生成的文件数直接减少 10 倍。
代码示例:
// 在 sink 之前重新分区,并强制指定 sink 的并行度
dataStream
.rebalance() // 或者根据某个不倾斜的 key 进行 keyBy
.sinkTo(fileSink)
.name("HDFS Sink")
.setParallelism(10); // 降低并发注意:这可能会导致写入 HDFS/S3 的那 10 个 Task 成为性能瓶颈(背压),需要根据实际数据量评估。
方案四:引入数据湖格式(架构升级,彻底根治)
传统 FileSink 处理大数据量实时写入已经逐渐力不从心。目前的业界最佳实践是引入 Apache Iceberg、Apache Hudi 或 Apache Paimon。这些数据湖格式对小文件有极其完善的管理机制。
- Apache Iceberg:支持异步或定时的
RewriteDataFiles操作,可以无缝在后台合并小文件。 - Apache Hudi:自带 Clustering 操作,可以控制小文件合并。
- Apache Paimon (推荐 Flink 用户):由 Flink 官方孵化,采用 LSM Tree 结构,天然就没有传统意义上的“小文件困扰”,它会在后台自动进行 Compaction。
方案五:异步/离线批处理合并(传统方案)
如果你的 Flink 版本较老,且不能随意改动线上任务,那么可以采用经典的“实时写小文件 + 离线合并大文件”策略。
- Flink 正常通过
StreamingFileSink写入按小时/天分区的目录。 - 配置一个定时的 Spark Batch 任务或 Hive SQL 任务(例如每小时执行一次)。
- 通过
INSERT OVERWRITE语法读取上一小时的分区数据,重新覆盖写入该分区。因为离线任务可以全局掌控数据,通常会输出设定好大小的大文件。
Hive 示例:
SET hive.merge.mapredfiles=true;
SET hive.merge.size.per.task=256000000;
SET hive.merge.smallfiles.avgsize=128000000;
INSERT OVERWRITE TABLE my_table PARTITION (dt='2023-10-01', hr='10')
SELECT * FROM my_table WHERE dt='2023-10-01' AND hr='10';总结与选型建议
- 首选:如果你在使用 Flink SQL,直接加上
'auto-compaction' = 'true'。 - 次选:如果使用 DataStream API 且 Flink >= 1.15,使用
FileSink.enableCompaction()。 - 长远规划:如果业务数据量大且未来有基于数据的查询/更新需求,强烈建议升级写入端为 Iceberg 或 Paimon。
- 应急处理:如果马上就要把 NameNode 搞挂了,立刻改代码:在 Sink 前加
.rebalance().setParallelism(小并发)重新发布。