业务不仅要求输出窗口聚合的最终结果,还要求如果在窗口计算完毕后、但仍在 AllowedLateness 范围内有新数据到达时,能够发出更新(Retract/Update)记录。应该怎么做?
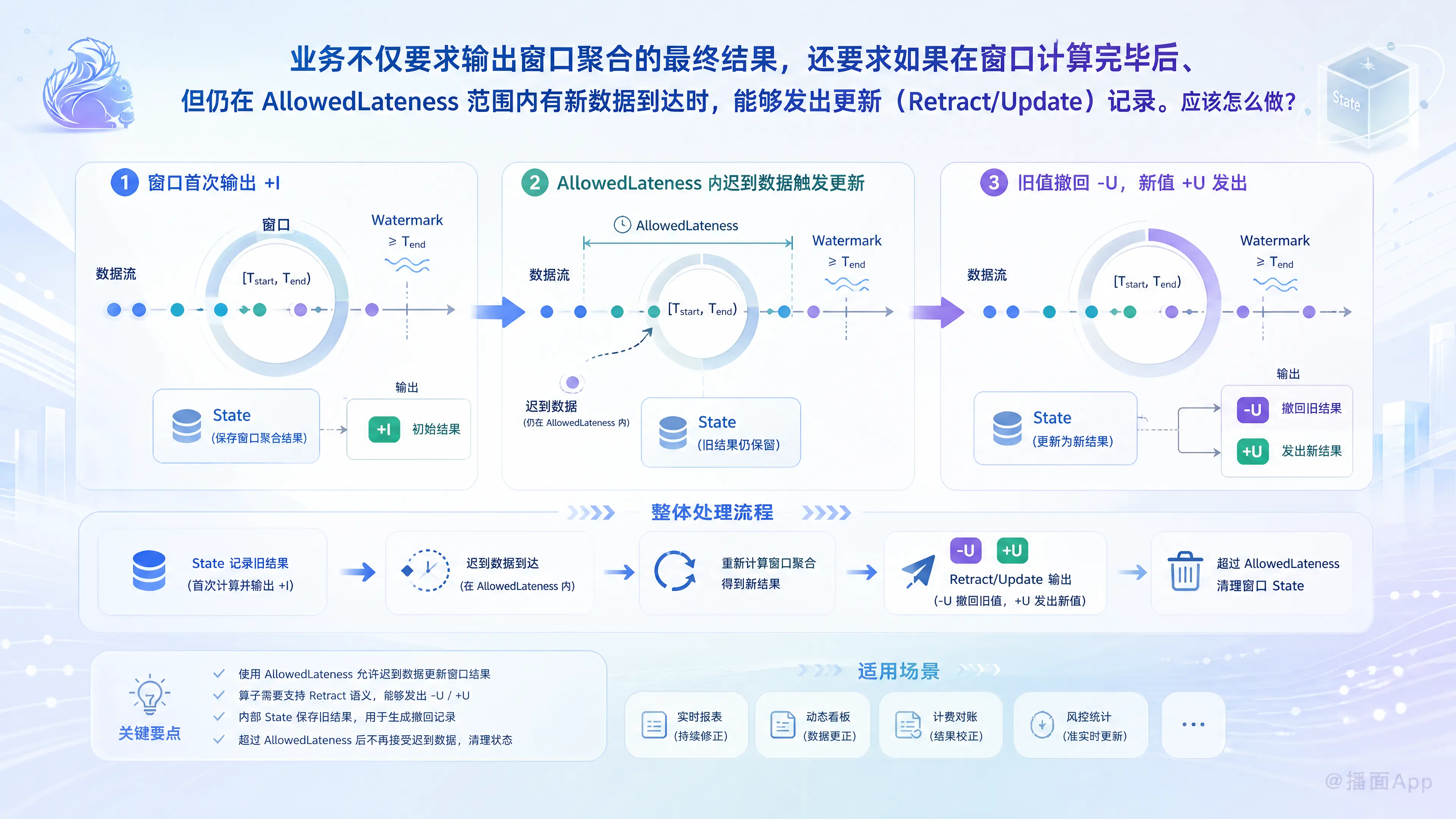
在流处理引擎(如 Apache Flink)中,处理带有 AllowedLateness(允许延迟)的窗口时,默认情况下,Flink DataStream API 遇到延迟数据会触发窗口的重新计算,并 再次输出一条新的结果(Append模式),而不是自动发出“撤回(Retract)”和“更新(Update)”记录。
如果业务明确要求输出带有撤回(Retract)和更新(Update)标识的变更流(Changelog Stream),我们需要通过自定义逻辑来实现。
以下是三种常见的解决方案,按推荐程度和适用场景排序:
方法一:DataStream API + 自定义状态(最精准、最契合需求)
如果你的下游需要明确的 [-U, +U](更新前、更新后)指令,你可以通过在 ProcessWindowFunction 中引入状态(State)来记录上一次触发时输出的结果。
核心原理:
- 窗口闭合(Watermark 过线)时,触发第一次计算,输出
[+I](插入)。 - 将此次结果保存到该窗口的
ValueState中。 - 在
AllowedLateness期间,如果有迟到数据到达,窗口再次触发。 - 从
ValueState取出旧结果,向下游发出[-U](撤回旧数据)。 - 发出重新计算后的新结果
[+U](输出新数据),并更新ValueState。 - 当
AllowedLateness时间到达,窗口彻底销毁,Flink 会自动清理与该窗口绑定的ValueState,不会造成状态泄露。
代码示例(Java):
// 假设数据结构为 Tuple3<String(Key), Long(Timestamp), Long(Value)>
DataStream<Tuple3<String, Long, Long>> stream = ...;
stream.keyBy(data -> data.f0)
.window(TumblingEventTimeWindows.of(Time.minutes(1)))
.allowedLateness(Time.minutes(5)) // 允许 5 分钟迟到
// 使用 AggregateFunction 提前增量聚合,ProcessWindowFunction 负责处理输出和状态
.aggregate(new MyAggregateFunction(), new RetractProcessWindowFunction())
.print();
// 自定义 ProcessWindowFunction 生成 Retract 流
public class RetractProcessWindowFunction
extends ProcessWindowFunction<Long, Row, String, TimeWindow> {
// 用于保存上一次输出的结果。注意:这里的 State 是 Window 级别的,会自动随窗口销毁而清理!
private ValueState<Long> lastResultState;
@Override
public void open(Configuration parameters) throws Exception {
ValueStateDescriptor<Long> descriptor = new ValueStateDescriptor<>(
"last-result", Long.class);
lastResultState = getRuntimeContext().getState(descriptor);
}
@Override
public void process(String key, Context context, Iterable<Long> elements, Collector<Row> out) throws Exception {
// 1. 获取当前窗口的最新聚合结果 (因为前面接了 AggregateFunction,这里 elements 只有一条记录)
Long currentResult = elements.iterator().next();
// 2. 获取上一次输出的结果
Long lastResult = lastResultState.value();
if (lastResult == null) {
// 第一次输出(窗口正常闭合时)
Row insertRow = Row.withRowKind(RowKind.INSERT); // +I
insertRow.addField(key);
insertRow.addField(context.window().getEnd());
insertRow.addField(currentResult);
out.collect(insertRow);
} else {
// 迟到数据触发的更新
if (!lastResult.equals(currentResult)) { // 如果结果变了才输出
// 发出撤回(Retract)记录
Row retractRow = Row.withRowKind(RowKind.UPDATE_BEFORE); // -U
retractRow.addField(key);
retractRow.addField(context.window().getEnd());
retractRow.addField(lastResult);
out.collect(retractRow);
// 发出更新后的记录
Row updateRow = Row.withRowKind(RowKind.UPDATE_AFTER); // +U
updateRow.addField(key);
updateRow.addField(context.window().getEnd());
updateRow.addField(currentResult);
out.collect(updateRow);
}
}
// 3. 更新状态
lastResultState.update(currentResult);
}
}方法二:利用下游存储的 Upsert 特性(最实用、工程中最常用)
在实际工程中,我们通常不要求 Flink 强行发出 Retract 流,而是利用下游数据库(如 MySQL、Redis、Elasticsearch、HBase 等)的 Upsert(幂等更新) 能力。
核心原理:
- Flink DataStream 默认行为是:迟到数据到达后,直接输出一条最新的计算结果(Append 模式)。
- 我们只需要在输出的结果中,包含能够唯一确定该窗口的主键(Primary Key):通常是
Key + WindowEnd。 - 当数据写入下游数据库时,执行
INSERT ... ON DUPLICATE KEY UPDATE(MySQL)或者直接PUT(Redis/HBase/ES)。
效果:
- 窗口正常闭合时:写入
Key="A", Window="10:00", Value=100。 - 迟到数据到达时:Flink 重新计算得出 105,直接输出并覆盖数据库中对应的记录,数据库最终变为
Value=105。
优点: 不需要维护额外的 State,不增加 Flink 的计算负担,实现极其简单。
方法三:使用 Flink SQL 的常规 Group By + 开启 MiniBatch(SQL方案)
如果你希望使用 Flink SQL,并且必须输出 Retract 流。需要注意:Flink SQL 的 Window TVF(TUMBLE/HOP 等)目前不支持发射迟到数据的更新(它们是 Append-only 的)。
为了实现类似窗口且带有撤回流的效果,可以通过时间戳取整将其转化为普通的 GROUP BY 聚合,普通聚合在 Flink SQL 中天生就是产生 Retract/Update 流的动态表(Dynamic Table)。
核心原理:
将事件时间向下取整作为“窗口键”,当作普通的 Group By 来做。
SQL 示例:
-- 配置允许数据晚到(State TTL,替代 AllowedLateness 的作用)
SET 'table.exec.state.ttl' = '1 h';
SELECT
user_id,
-- 将 event_time 向下取整到分钟级别,模拟 1 分钟的滚动窗口
TUMBLE_START(event_time, INTERVAL '1' MINUTE) as window_start,
COUNT(1) as pv
FROM source_table
GROUP BY
user_id,
TUMBLE_START(event_time, INTERVAL '1' MINUTE);注意:这不是官方标准的 Window TVF 语法,而是传统的分组聚合。这种写法下,每来一条数据(包括正常数据和迟到数据),Flink 都会输出 -U 和 +U。为了避免更新过于频繁,通常会配合开启 MiniBatch(微批处理)来减少输出量。
总结建议
- 如果下游是关系型数据库或 KV 存储:强烈建议使用 方法二(Upsert 模式)。只需要把
Key + 窗口结束时间作为联合主键即可,这是业内最通用、性能最高的做法。 - 如果下游是 Kafka,且消费端严格依赖
[-U, +U]格式(例如 Debezium 格式):使用 方法一(ProcessWindowFunction + ValueState),这是在 DataStream API 中完美解决此问题的标准范式。