上游数据存在严重的乱序情况,最大乱序时间难以预估。如果把 Watermark 的延迟时间设置得过长,会导致什么问题?设置得过短又会有什么后果?
在流式计算(如 Apache Flink)中,处理“严重且难以预估的最大乱序时间”是一个非常经典的难题。Watermark(水位线)的核心作用是平衡计算的“延迟(Latency)”和“准确性(Correctness)”。
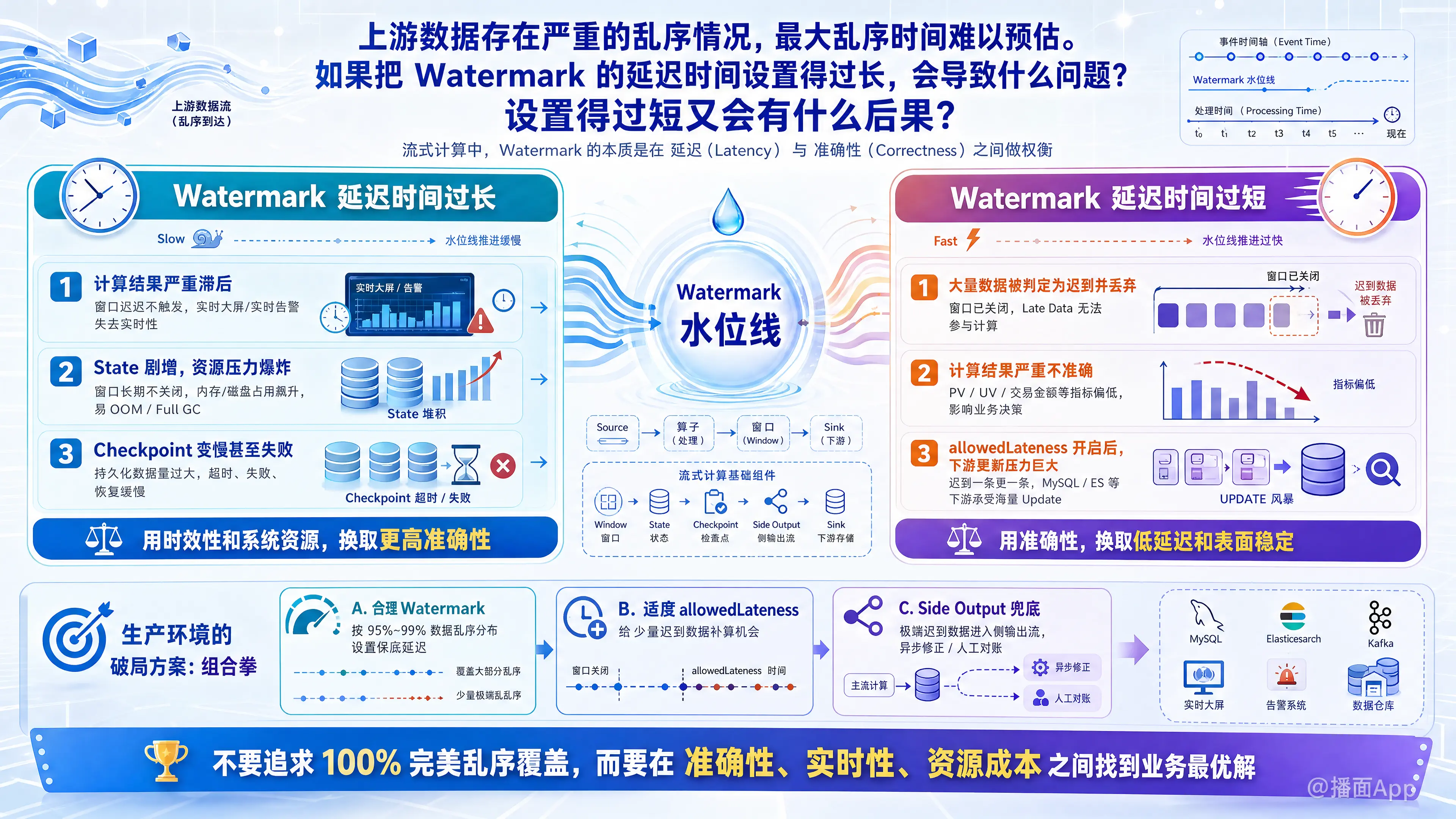
如果上游乱序严重,Watermark 延迟时间设置得过长或过短,都会带来极其显著的负面影响。以下是具体的后果分析:
一、 如果 Watermark 延迟时间设置得 过长
将延迟时间设置得很长(例如设置为了覆盖所有可能的乱序,设为几个小时),本质上是在牺牲时效性和系统资源,来换取数据的绝对准确。
带来的问题:
- 计算结果严重滞后(失去实时性):
- Watermark 的推进会非常缓慢,导致基于 Event Time 的窗口(Window)迟迟不能触发计算并输出结果。
- 后果:原本需要秒级、分钟级响应的实时大屏、实时告警系统,变成了“准实时”甚至“批处理”,流计算失去了其核心业务价值。
- 状态(State)剧增,内存/磁盘压力爆炸(极易 OOM):
- 因为窗口迟迟不关闭,所有进入这些窗口的数据(或聚合状态)都需要长期保存在 Flink 的 State 中。
- 后果:如果数据流量很大,State 体积会迅速膨胀,导致 JVM 堆内存耗尽(OOM)、频繁的 Full GC(导致任务假死),或者 RocksDB 占用极大的磁盘空间。
- Checkpoint 耗时过长甚至频繁失败:
- State 体积变大后,每次 Checkpoint 需要持久化到底层存储(如 HDFS/OSS)的数据量也会成倍增加。
- 后果:Checkpoint 耗时变长,容易发生超时失败(Timeout)。一旦任务发生异常重启,从庞大的 Checkpoint/Savepoint 恢复也会极其缓慢。
二、 如果 Watermark 延迟时间设置得 过短
将延迟时间设置得很短(例如只设置几秒钟),本质上是在牺牲数据的准确性,来换取极致的低延迟和系统稳定性。
带来的问题:
- 大量数据被判定为“迟到(Late Data)”并被丢弃:
- Watermark 推进得很快。当严重乱序的数据姗姗来迟时,它所属的窗口已经被 Watermark 触发并关闭了。
- 后果:默认情况下,窗口关闭后到达的数据会被直接丢弃,造成严重的数据丢失。
- 计算结果严重不准确:
- 由于大量迟到数据未参与窗口的聚合计算。
- 后果:输出的统计指标(如 PV、UV、交易金额等)会比真实值偏低,导致业务决策失误或对账失败。
- 下游系统面临频繁的“撤回/更新”冲击(如果开启了 allowedLateness):
- 如果你为了弥补短 Watermark 带来的丢数据问题,开启了
allowedLateness(允许窗口保持存活一段时间来接收迟到数据)。 - 后果:每来一条迟到数据,窗口就会重新计算并向下游发送一条更新(Retract/Update)记录。如果乱序数据非常多,下游数据库(如 MySQL, ElasticSearch)将承受海量的 Update 请求,可能导致下游被打垮。
- 如果你为了弥补短 Watermark 带来的丢数据问题,开启了
三、 面对“最大乱序时间难以预估”的破局方案
既然单纯调节 Watermark 的长短都无法完美解决问题,在实际生产中,通常采用“组合拳”来应对这种极端场景:
最佳实践组合:合理的 Watermark + 适度的 allowedLateness + 侧输出流(Side Output)兜底
- 设定“保底”的 Watermark:
根据大部分数据(如 95% 或 99% 的数据)的乱序时间来设置 Watermark 延迟(例如 10 秒)。保证 99% 的业务计算既准时又准确,同时控制了 State 的大小。 - 设置
allowedLateness应对中度乱序:
允许窗口在触发后继续保留一段时间(例如 5 分钟或 1 小时)。这期间来到的迟到数据,会触发窗口的增量更新。这兼顾了时效性(第一批结果先出)和最终准确性。 - 使用
Side Output收集极端迟到数据:
对于超过了allowedLateness的极端乱序数据(难以预估的那部分),将其打入侧输出流(Side Output),写入 Kafka 或 HDFS/Hive。- 后续可以通过离线批处理任务(如 T+1)将这部分数据合并,用于最终的财务对账或离线报表修正。
- 从源头治理(最高优先级):
“数据难以预估的严重乱序”通常意味着上游链路存在架构问题(如设备时钟不齐、网络分区缓存后突发上传、不同分区消费极度不均衡等)。如果可能,应该推动上游优化,而不是完全由 Flink 计算层来默默承受物理极限。
右滑查看面试常问