如果 Flink 挂掉后从上一个 Checkpoint 恢复,重放了一部分数据,你的 Sink 是写入到 HBase/Redis 或 MySQL,如何设计业务侧的幂等操作来容忍这部分重放?
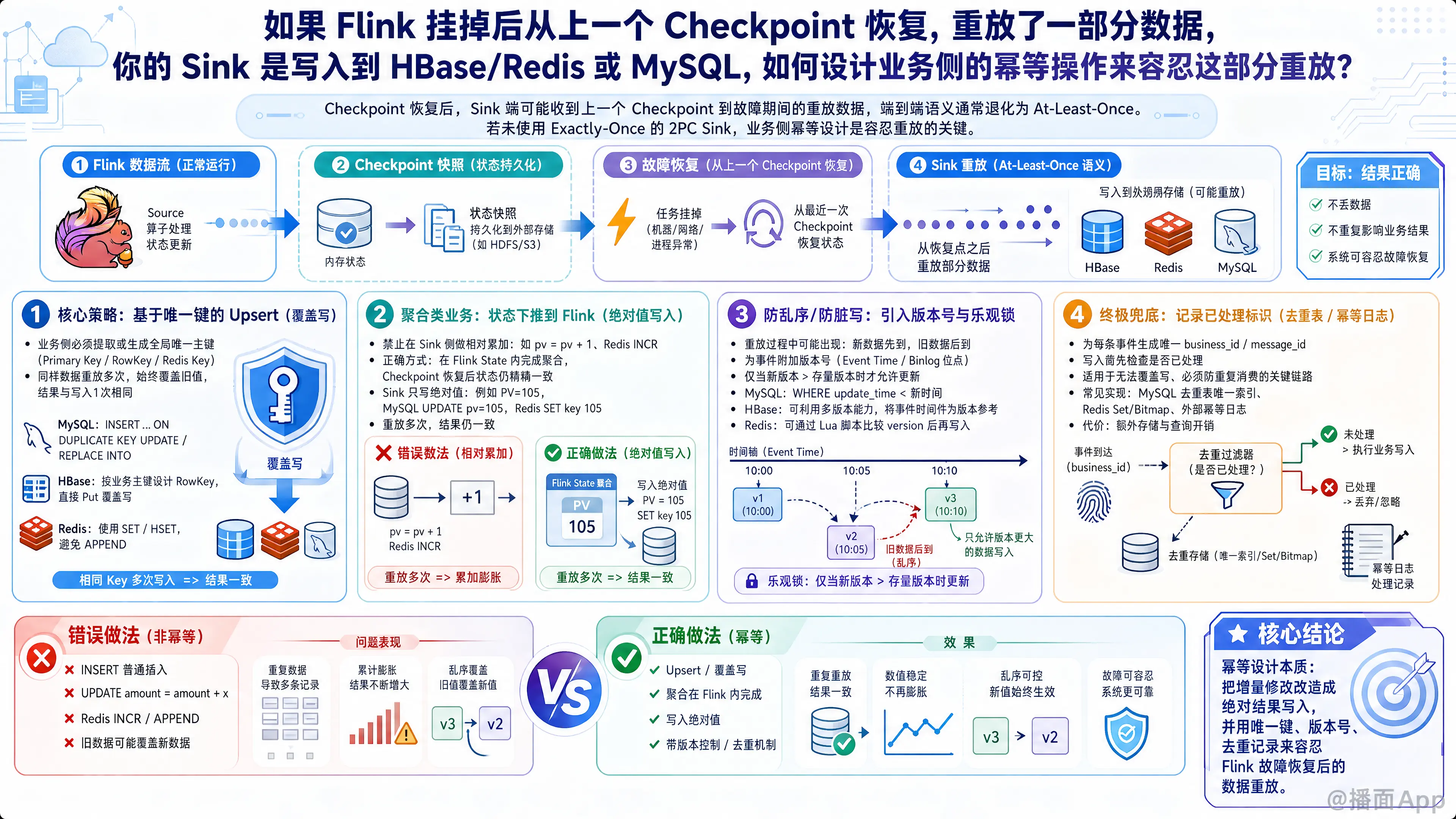
在 Flink 挂掉并从 Checkpoint 恢复的场景下,由于 Checkpoint 机制的特性,Sink 端不可避免地会收到从上一个 Checkpoint 到故障发生期间的“重放数据”。这就导致了端到端的语义退化为 At-Least-Once(至少一次)。
如果你没有使用支持精确一次(Exactly-Once)的二阶段提交(2PC)Sink,那么在业务侧设计幂等性(Idempotence)是容忍数据重放的唯一且最有效的手段。
针对 HBase、Redis 和 MySQL 等通常的存储介质,设计幂等操作的核心原则是:将“增量/相对修改”转化为“绝对/覆盖修改”。具体可以通过以下几种设计模式来实现:
1. 核心策略:基于唯一键的 Upsert(覆盖写)
这是最基础也最常用的幂等设计。业务侧必须能从数据中提取或生成一个全局唯一的主键(Primary Key / RowKey / Redis Key)。
- 设计原则:无论同样的数据重放多少次,写入存储时都直接覆盖旧值。由于重放的数据内容是完全一致的,所以覆盖 n 次和写入 1 次的结果完全相同。
- 各组件实现:
- MySQL:禁止使用普通的
INSERT,必须使用INSERT ... ON DUPLICATE KEY UPDATE或者REPLACE INTO。 - HBase:天然支持覆盖写。根据业务主键设计
RowKey,直接执行Put操作。相同RowKey的数据重放时会自动覆盖。 - Redis:直接使用
SET、HSET。不要使用APPEND。
- MySQL:禁止使用普通的
2. 聚合类业务:状态下推到 Flink(绝对值写入)
如果你的业务是做聚合(如:计算 PV、UV、订单总金额),绝对不能在 Sink 侧做相对累加。
- 错误示范(非幂等):Flink 每处理一条数据,向 MySQL 发送
UPDATE table SET pv = pv + 1,或者向 Redis 发送INCR key。一旦重放,数据就会多加。 - 正确设计(幂等):
- 利用 Flink 内部强大的 State 机制,在 Flink 内部完成聚合。
- 由于 Flink 的 State 在 Checkpoint 恢复时是精确一致的(回滚到了故障前的状态),Flink 重新计算后输出给 Sink 的是一个绝对值(例如:当前 PV 是 105)。
- Sink 端收到
105后,直接执行覆盖写:MySQL 执行UPDATE table SET pv = 105,Redis 执行SET key 105。重放多次依然是 105。
3. 防乱序/防脏写:引入版本号与乐观锁(Version Control)
在重放过程中,由于网络延迟或并发执行,可能会出现新数据先到,重放的旧数据后到的乱序情况。如果旧数据覆盖了新数据,业务就错了。
- 设计原则:为每一条数据附加一个版本号(通常是事件发生时的 Event Time,或 Binlog 的自增位点)。在写入时比较版本号,只有当新数据的版本号大于存储中的版本号时,才允许写入。
- 各组件实现:
- MySQL:sql
UPDATE table SET status = 'PAID', update_time = '2023-10-01 10:00:05' WHERE order_id = 123 AND update_time < '2023-10-01 10:00:05'; -- 乐观锁条件 - HBase:HBase 天然支持多版本(Versions)。可以在 Flink Sink 执行
Put时,显式地将事件的 Event Time 作为 HBase Cell 的 Timestamp。如果重放的是旧数据,其 Timestamp 较小,HBase 查询时默认返回最新 Timestamp 的数据,旧数据会被自然“屏蔽”。 - Redis:结合 Lua 脚本保证原子性。plaintext
local current_version = tonumber(redis.call('HGET', KEYS[1], 'version')) local new_version = tonumber(ARGV[1]) if (not current_version) or (new_version > current_version) then redis.call('HSET', KEYS[1], 'value', ARGV[2], 'version', ARGV[1]) return 1 else return 0 end
- MySQL:
4. 明细类/事件流业务:去重表/唯一凭证(Token/Dedup)
有时业务操作无法设计成覆盖写(例如:向外部系统发送短信、触发不可逆的 API、或者 MySQL 中没有合适主键的明细流水表)。
- 设计原则:为每个事件生成唯一 ID(Message ID / Event ID),在执行业务逻辑前先查重。
- 各组件实现:
- MySQL:建立一张独立的去重表(以 Event ID 为主键)。利用数据库的事务机制,将业务操作和写入去重表放在一个事务中。如果重放,写入去重表会报
Duplicate Key异常,此时捕获异常并忽略本次操作即可。 - Redis:维护一个已处理 Event ID 的 Set 或带 TTL 的 String(例如
SET event_id 1 EX 86400 NX)。只有返回OK(代表之前没处理过)时,才执行实际的下游操作。 - HBase:可以利用
checkAndPut原语来实现仅当记录不存在时才写入。
- MySQL:建立一张独立的去重表(以 Event ID 为主键)。利用数据库的事务机制,将业务操作和写入去重表放在一个事务中。如果重放,写入去重表会报
总结:架构设计的最佳实践
当评估 Flink Sink 容忍数据重放时,可以按以下优先级思考:
- 优先依赖 Flink State:把复杂的计算逻辑留在 Flink 内部,利用 Flink Checkpoint 保证内部状态的 Exactly-Once,Sink 只负责最简单的“最终结果无脑覆盖写”。
- 必须保证主键的确定性:用来做 Upsert 的 Key 必须是根据业务数据确定性生成的(例如
MD5(user_id + action + timestamp)),千万不能在 Flink 里用UUID.randomUUID()作为主键输出,否则重放时生成的新 UUID 会导致 Upsert 变成不断插入新数据。 - 时间戳是乱序的救星:永远在你的消息模型中带上业务发生时间(Event Time),并在存储端基于时间戳做高水位(Watermark)拦截,这是防止重放导致数据回退的最强护城河。
右滑查看面试常问