业务要求实现端到端的 Exactly-Once,你的 Source 是 Kafka,Sink 也是 Kafka。如果在写出到目标 Kafka 时由于两阶段提交(2PC)超时导致数据不可见,怎么排查和解决
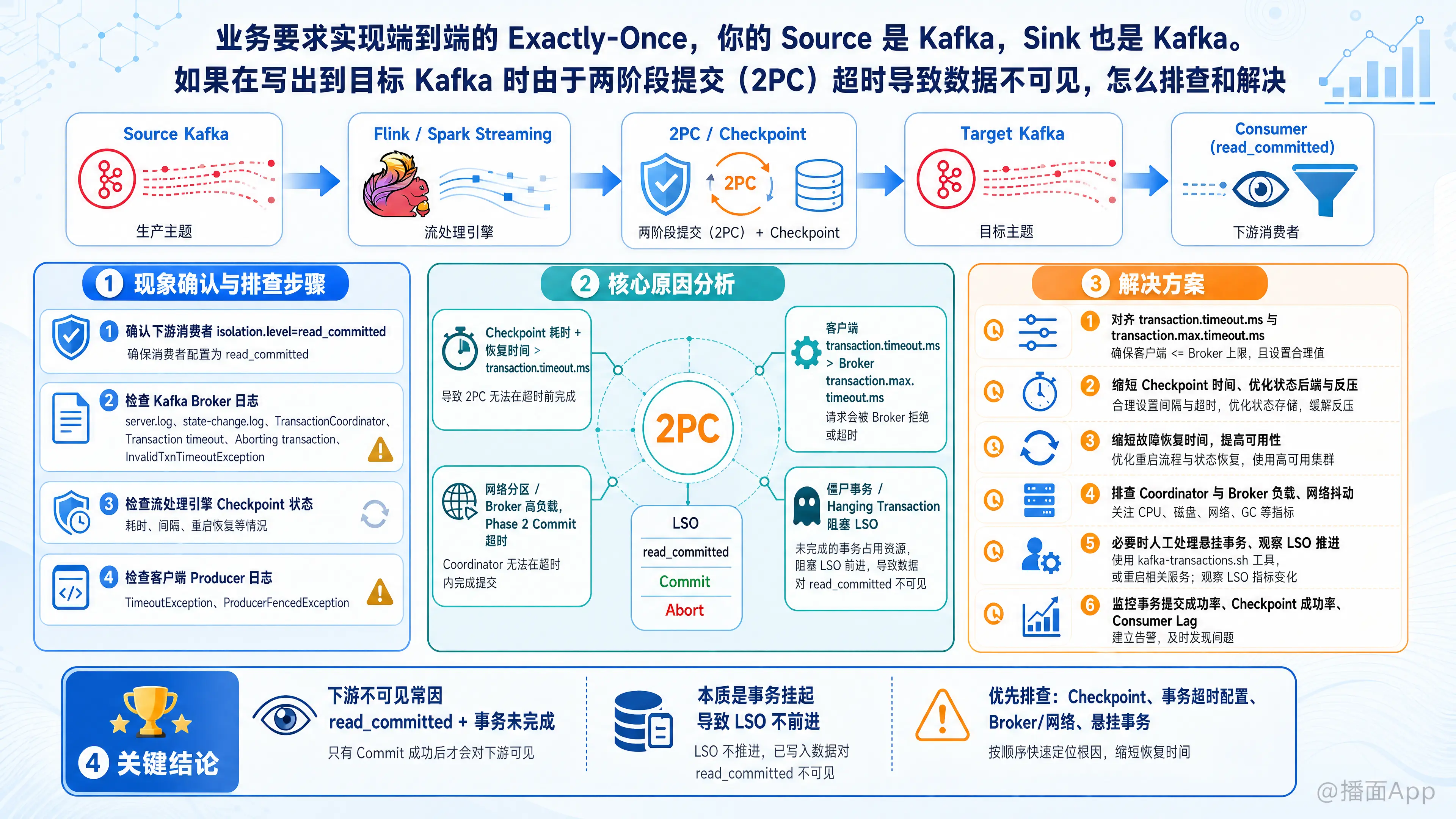
在流处理(通常是 Flink 或 Spark Streaming)中实现端到端的 Exactly-Once 语义(EOS),Source 和 Sink 都是 Kafka 且使用两阶段提交(2PC)是非常经典的架构。
如果在写出到目标 Kafka 时,由于 2PC 超时导致下游消费者数据不可见,通常是因为下游消费者配置了 isolation.level=read_committed,而 Kafka 端的事务处于挂起(Pending)状态,导致最后稳定偏移量(LSO, Last Stable Offset)没有向前推进,从而阻塞了消费。
以下是详细的排查过程和解决方案:
一、 现象确认与排查步骤
1. 确认下游消费者的隔离级别
检查下游消费者的配置,确认是否设置了 isolation.level = read_committed。如果是,消费者只能看到已经 Commit 的事务数据。如果事务未提交或卡住,消费者的 Lag 会持续增加,但无法拉取新数据。
2. 检查 Kafka Broker 日志
去目标集群的 Kafka Broker 节点查看 server.log 和 state-change.log,搜索 TransactionCoordinator 相关的日志。
- 寻找是否有类似
Transaction timeout、Aborting transaction的日志。 - 确认是否有
InvalidTxnTimeoutException(通常是因为客户端请求的超时时间大于 Broker 允许的最大值)。
3. 检查流处理引擎(如 Flink)的 Checkpoint 状态
2PC 的第一阶段(Pre-commit)在 Checkpoint 的快照阶段执行,第二阶段(Commit)在 Checkpoint 完成后的通知回调中执行。
- 查看 Checkpoint 耗时: Checkpoint 的持续时间是否过长?
- 查看 Checkpoint 间隔: 两次 Checkpoint 之间的间隔是否过长?
- 查看重启日志: 任务是否在 Checkpoint 完成后、发送 Commit 之前发生了重启,且恢复时间过长?
4. 检查客户端 Producer 日志
查看 Sink 端的日志,寻找 TimeoutException、ProducerFencedException 或 KafkaProducer 相关的 WARN/ERROR 日志。
二、 核心原因分析
导致 2PC 超时进而数据不可见,通常有以下几个根本原因:
- Checkpoint 耗时 + 恢复时间 > 事务超时时间
Kafka Producer 的transaction.timeout.ms(默认 1分钟 或 15分钟,取决于版本和引擎)。如果 Flink 的 Checkpoint 做得太慢,或者任务崩溃后重启恢复的时间超过了该值,Kafka Broker 会单方面 abort 这个事务。当 Flink 恢复后尝试 commit 时会失败,或者导致状态不一致。 - 配置冲突(客户端超时 > 服务端最大超时)
客户端代码中设置了较大的transaction.timeout.ms(例如 1小时),但是 Kafka Broker 端配置的transaction.max.timeout.ms(默认 15分钟)较小。Broker 会拒绝该请求,导致事务无法正常创建或提前被 Broker 终止。 - 网络分区或 Broker 负载过高
在 Phase 2(Commit)阶段,客户端发送 EndTxnRequest 到 Kafka 所在的 Transaction Coordinator 失败或超时。 - “僵尸”事务阻塞 LSO
在极端异常(如网络隔离+脑裂)下,可能产生悬挂事务(Hanging Transaction),既不 Commit 也不 Abort。这会使得该 Partition 的 LSO 永远停滞,下游read_committed消费者完全卡死。
三、 解决方案与参数调优
1. 紧急恢复(让数据先可见)
如果下游已经卡死,且你需要立刻恢复业务消费:
- 临时方案: 将下游消费者的隔离级别临时改为
isolation.level = read_uncommitted(默认值)。这会让下游跳过 LSO 限制,直接读到最新数据。- 代价: 会破坏端到端的 Exactly-Once 语义,下游可能会读到重复数据或被 Abort 的数据(需要结合下游业务幂等性来兜底)。
- 清理挂起事务: 如果确认是“僵尸事务”卡住了 Partition,可以通过修改 Flink Sink 的
transactional.id前缀重启任务,或者编写脚本强制触发该transactional.id的 abort。
2. 核心参数对齐(根本解决配置问题)
必须确保以下三个时间参数满足不等式关系:Checkpoint 间隔 + Checkpoint 超时时间 < 客户端 transaction.timeout.ms ≤ Broker 端 transaction.max.timeout.ms
- 修改 Kafka Broker 端(需要重启 Broker):
修改server.properties,调大事务最大超时时间(推荐 1 小时或更高):plaintexttransaction.max.timeout.ms=3600000 - 修改流计算引擎端(以 Flink 为例):
调大 Kafka Sink Producer 的事务超时时间:javaProperties sinkProperties = new Properties(); // 设置为小于等于 Broker 的 max.timeout,例如 1 小时 sinkProperties.setProperty("transaction.timeout.ms", "3600000");
3. 优化 Checkpoint(解决超时根源)
如果是因为 Checkpoint 太慢导致的超时,需要优化流处理引擎的 Checkpoint 流程:
- 开启增量 Checkpoint: 比如 Flink 中使用 RocksDB 状态后端并开启增量快照,大幅减少快照时间。
- 缩短 Checkpoint 周期: 如果当前是 15 分钟一次,可以尝试缩短到 3 分钟一次,这样每次需要 flush 的状态和数据更少。
- 解决数据倾斜与反压: Checkpoint 慢通常是因为反压(Backpressure)导致 Barrier 无法顺利流动。排查业务逻辑,解决数据倾斜。
- 开启非对齐 Checkpoint(Unaligned Checkpoints): 在 Flink 中,如果反压严重,可以开启 UAC,让 Barrier 越过积压的数据,强行完成 Checkpoint,从而快速触发 2PC 的 Commit。
4. 优化 Kafka 集群性能
- Transaction Topic 副本健康度: 检查 Kafka 内部 Topic
__transaction_state的健康状况。如果存储它的磁盘 IO 瓶颈,会导致 2PC 提交极慢。 - 网络调优: 确保 Flink TaskManager 与 Kafka Broker 之间的网络延迟稳定。
总结排查口诀
“一查下游隔离,二看 Broker 拒绝,三对 Checkpoint 耗时,四调超时上限。”
在实际生产中,90% 的 Kafka 2PC 超时问题都是因为 Flink 反压导致 Checkpoint 耗时增加,进而突破了默认的 15 分钟事务超时限制。调大 transaction.max.timeout.ms 并优化 Checkpoint 是最标准的解决路径。