业务需要根据用户名或手机号进行模糊搜索(LIKE '%xx%'),导致索引失效走全表扫描,如何解决?
在MySQL中,使用 LIKE '%xx%'(双头模糊匹配)会破坏B+树索引的最左前缀原则,从而导致索引失效、触发全表扫描。如果数据量较大,这会引起严重的性能问题。
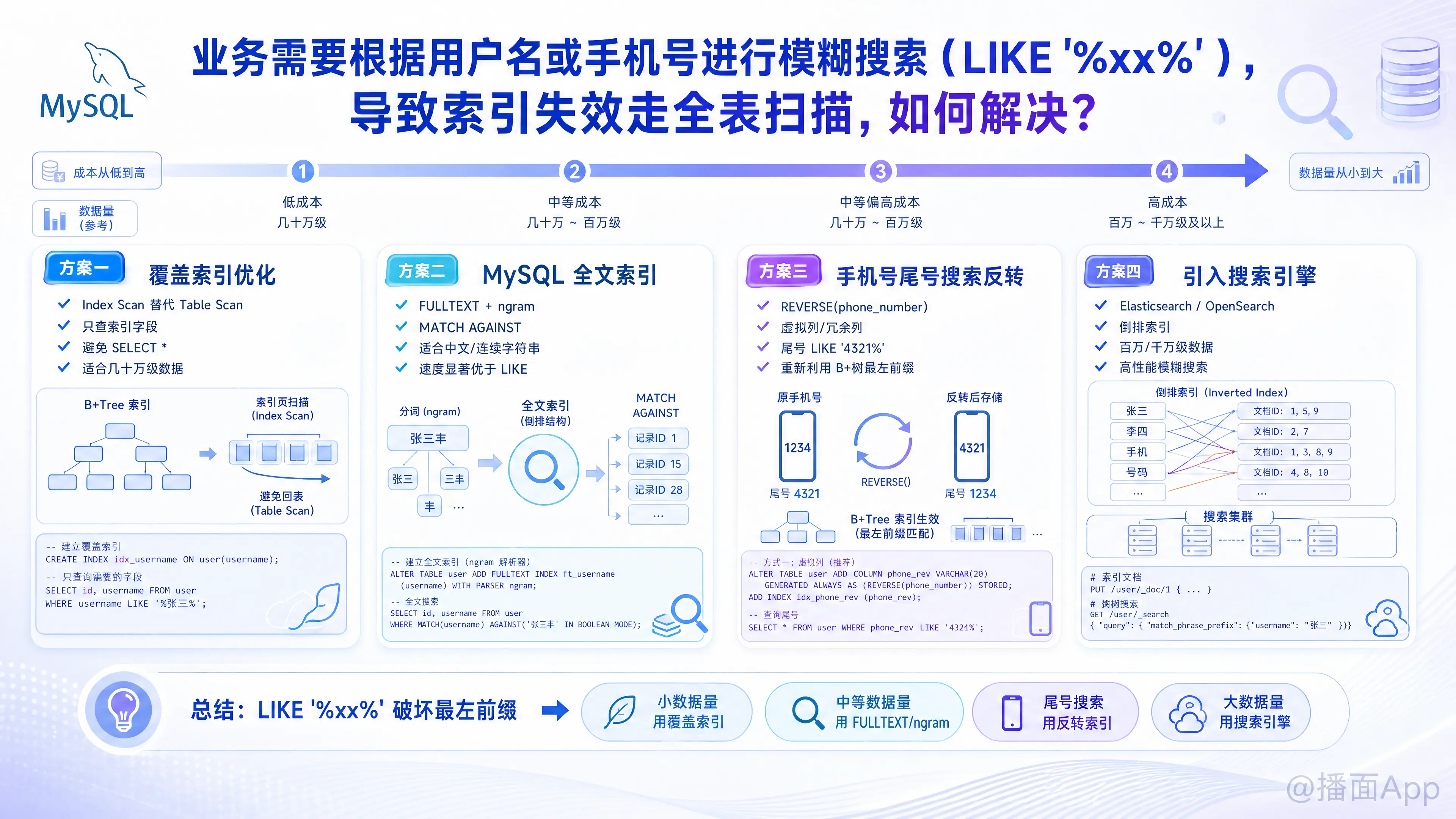
针对“用户名”或“手机号”的模糊搜索需求,业内通常有以下几种解决方案,按实现成本从低到高、适用数据量从小到大排序:
方案一:使用“覆盖索引”优化(最简单,不改架构)
虽然 LIKE '%xx%' 无法使用索引树进行快速定位,但我们可以让它走索引全扫描(Index Scan),而不是全表扫描(Table Scan)。索引树的体积远小于全表数据,在内存中扫描的速度要快得多。
- 做法:建立一个包含你要查询的所有字段的联合索引(比如
id,username,phone_number)。 - 前提:绝对不能用
SELECT *,只能 SELECT 索引里存在的字段。 - SQL示例:sql
-- 创建联合索引 ALTER TABLE users ADD INDEX idx_user_phone (username, phone_number); -- 查询时只查这几个字段(此时执行计划的 Extra 会显示 Using index,即覆盖索引) SELECT id, username, phone_number FROM users WHERE username LIKE '%xx%' OR phone_number LIKE '%xx%'; - 适用场景:单表数据量不大(几十万级别),且只需要返回基础信息。如果需要其他字段,可以先通过覆盖索引查出
id,再做一次回表查询。
方案二:使用 MySQL 原生全文索引 (Full-Text Search)
从 MySQL 5.7 开始,InnoDB 引擎原生支持全文索引,并且支持 ngram 分词器(非常适合处理中文和连续的英数字符串)。
- 做法:给用户名和手机号添加全文索引。
- SQL示例:sql
-- 添加全文索引,并指定 ngram 分词器(必须加 ngram,否则无法按字/词切分连续字符串) ALTER TABLE users ADD FULLTEXT INDEX ft_user_phone (username, phone_number) WITH PARSER ngram; -- 查询语法(使用 MATCH ... AGAINST) SELECT * FROM users WHERE MATCH(username, phone_number) AGAINST('张三' IN BOOLEAN MODE); - 优点:不需要引入外部中间件,纯 MySQL 实现,查询速度比
LIKE快几个数量级。 - 缺点:
- ngram 分词器会增加索引存储空间。
- 默认的分词长度(
ngram_token_size)通常是 2,这意味着搜单字可能会搜不到(需要修改 MySQL 配置文件my.cnf将其改为 1 或 2 根据业务定,并重建索引)。
方案三:针对“手机号尾号搜索”的特殊优化(反转字符串)
很多业务场景下,所谓的手机号模糊搜索,其实是搜索尾号(例如:查找尾号是 1234 的用户)。如果是这种情况,可以用字符串反转来解决。
- 做法:在表中增加一个虚拟列(或者通过代码控制新增一个字段)存储反转后的手机号,并给它加 B+ 树索引。
- SQL示例(MySQL 5.7+ 虚拟列):sql
-- 添加虚拟列并建普通索引 ALTER TABLE users ADD COLUMN reverse_phone VARCHAR(20) GENERATED ALWAYS AS (REVERSE(phone_number)), ADD INDEX idx_reverse_phone(reverse_phone); -- 查询尾号为 1234 的手机号(转换成左前缀匹配) SELECT * FROM users WHERE reverse_phone LIKE '4321%'; - 优点:完美利用普通 B+ 树索引,极其高效。
- 缺点:只适用于“后缀匹配”(
LIKE '%xx'),不适用于真正的“包含匹配”(LIKE '%xx%')。
方案四:引入搜索引擎(Elasticsearch / Meilisearch)(企业级终极方案)
当数据量达到几百万、千万级别,或者有极高的并发要求时,关系型数据库已经不再适合做全文检索了。这时候应该将搜索职责剥离给专业的搜索引擎。
- 做法:
- 部署 Elasticsearch (ES) 配合分词器,或者轻量级的 Meilisearch / RediSearch。
- 通过 Canal 监听 MySQL 的 Binlog,将
users表的增删改实时同步到 ES 中。 - 业务代码在搜索时,直接请求 ES 接口获取用户 ID。
- 拿到 ID 后,再去 MySQL (或 Redis) 中获取完整信息。
- 优点:性能极高,支持拼音、错别字纠错、多字段复杂权重打分,完全释放 MySQL 的压力。
- 缺点:引入了新的组件,增加了系统复杂度、运维成本以及数据一致性(同步延迟)的问题。
方案五:将 OR 拆分为 UNION(SQL写法优化)
不管你用不用 LIKE,在查询中包含 OR 往往会阻碍索引的有效使用。如果是单纯的 LIKE 'xx%'(右模糊)加上 OR,通常也会走全表扫描。
- 优化写法:(注:如果依然是sql
SELECT id, username, phone_number FROM users WHERE username LIKE '%xx%' UNION SELECT id, username, phone_number FROM users WHERE phone_number LIKE '%xx%';%xx%双头模糊,配合方案一的覆盖索引,UNION 扫描的效率通常也比直接 OR 略好一些)。
总结与技术选型建议:
- 数据量 < 50万:直接使用 方案一(覆盖索引)。代码不用改,加个索引,避免
SELECT *即可,性能多数情况能接受。 - 数据量 50万 ~ 500万:强烈建议使用 方案二(MySQL FULLTEXT + ngram)。开发成本低,性能提升显著。
- 数据量 > 500万,且搜索并发高:必须上 方案四(Elasticsearch 等独立搜索组件),花钱买平安,一劳永逸。
- 只要查手机尾号:用 方案三(反转字符串)。
右滑查看面试常问