生产者使用默认的粘性分区策略(Sticky Partitioner)相比于传统的轮询策略,在网络传输性能上有什么显著优势?
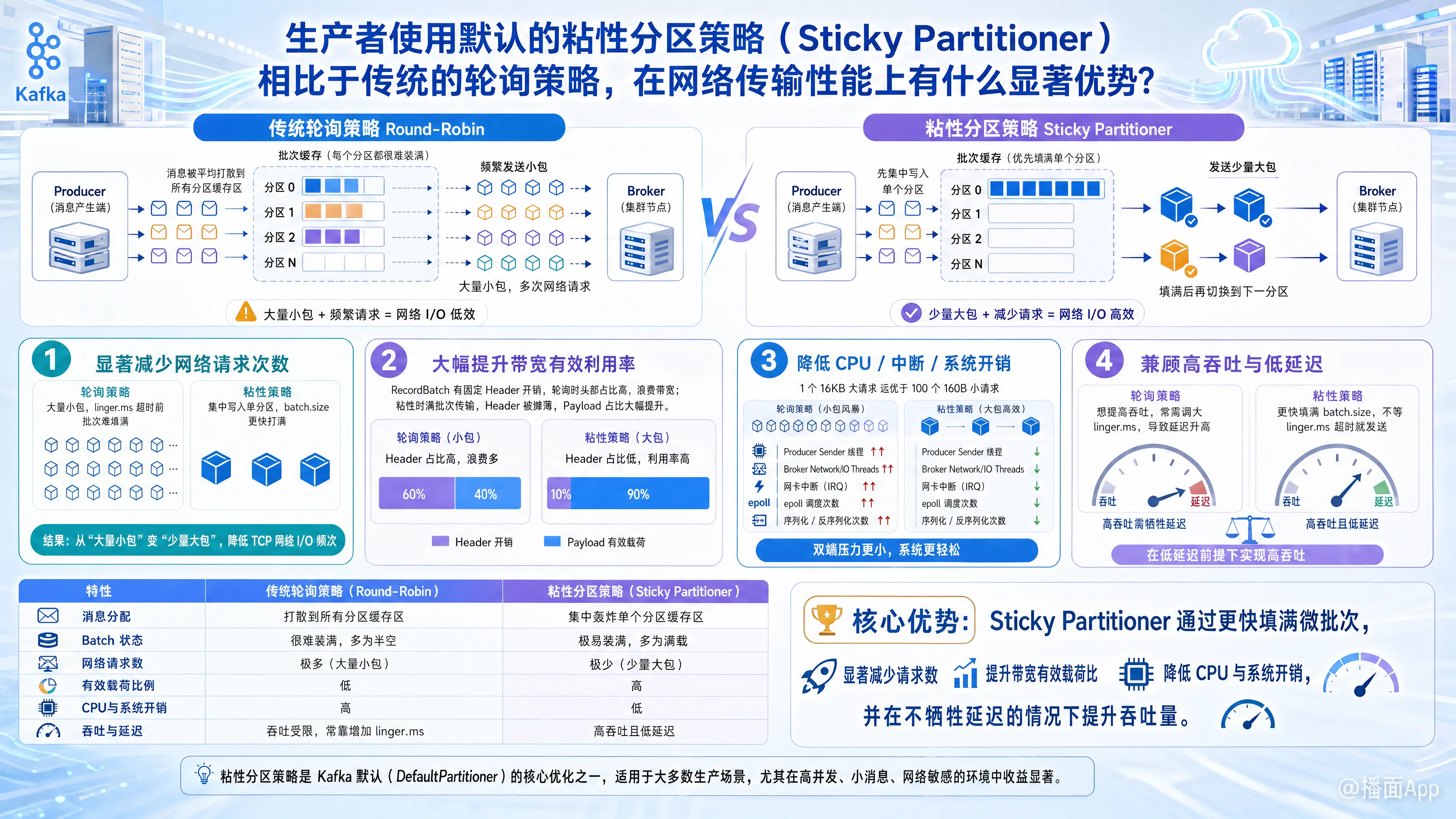
在 Kafka 中,自 2.4 版本引入(KIP-480)并成为无 Key 消息默认策略的粘性分区器(Sticky Partitioner),相比于传统的轮询策略(Round-Robin),在网络传输性能上的核心优势可以总结为一句话:极大提升了微批次(Batch)的填充效率,从而显著降低了网络请求开销并提升了吞吐量。
要理解这个优势,必须结合 Kafka 生产者的底层批处理机制(RecordAccumulator)来分析。
以下是粘性分区策略在网络传输性能上的具体显著优势:
1. 显著减少网络请求次数(降低网络 I/O 开销)
- 传统轮询策略的痛点:假设有 10 个分区,生产者会将消息依次“均匀”撒在 10 个分区的缓存队列中。这就导致每个分区的批次(Batch)填充得非常慢。往往还没达到
batch.size(默认 16KB),就触发了linger.ms(最大等待时间)的超时,最终导致生产者向 Broker 发送了大量包含少量消息的“小包”。 - 粘性分区的优势:粘性策略会“黏住”一个特定的分区,将所有的无 Key 消息全部塞进这一个分区的 Batch 中,直到该 Batch 被填满(达到
batch.size)或发送出去后,才会随机选择并“黏住”下一个新分区。这使得 Batch 能在极短的时间内被填满。 - 网络收益:发送的请求数量大幅减少,从“大量小包”变成了“少量大包”,极大降低了底层的 TCP 网络 I/O 交互频次。
2. 大幅提升网络带宽的有效利用率(提高有效载荷比)
- 在 Kafka 的网络协议中,每一个 RecordBatch(消息批次)在网络传输时都有固定的头部开销(Header,包含校验和、位移、时间戳、元数据等,通常几十个字节)。
- 传统轮询策略:由于批次没填满就被发送,假设一个批次只装了 1 条消息,那么“头部开销 / 实际数据”的比例就会非常高,白白浪费了大量网络带宽在传输元数据上。
- 粘性分区的优势:因为批次通常都能被完全填满(例如装满 16KB 的消息),固定的头部开销被分摊到了成百上千条消息上。网络中传输的绝大部分字节都是业务的有效数据(Payload),带宽利用率呈指数级上升。
3. 降低系统级 CPU 和网络中断开销(Producer 与 Broker 双赢)
- 网络传输不仅仅是线缆上的事,还涉及网卡中断、操作系统内核上下文切换(epoll)、应用层序列化与反序列化。
- 处理 1 个包含 1000 条消息的 16KB 网络请求,其 CPU 和系统开销,远远小于处理 100 个只包含 10 条消息的 160B 网络请求。
- 粘性分区的优势:通过发送大批次,生产者的 Sender 线程唤醒次数减少,Broker 端处理网络请求的处理线程(Network Threads / IO Threads)压力骤降。Broker 不再需要频繁地解析大量零碎的网络请求,可以支撑更高的整体集群并发。
4. 优化了“高吞吐”与“低延迟”的矛盾
- 传统轮询策略:如果不调整参数,在高并发下会导致吞吐量上不去;如果为了提高吞吐量而刻意调大
linger.ms来强制攒大批次,又会导致消息延迟急剧增加。 - 粘性分区的优势:因为它能非常快速地填满一个
batch.size,所以批次一旦填满就会立刻触发网络发送,根本不需要等待linger.ms超时。这意味着它在不增加(甚至降低了)消息端到端延迟的前提下,实现了极高的吞吐量。
总结对比图景
| 特性 | 传统轮询策略 (Round-Robin) | 粘性分区策略 (Sticky Partitioner) |
|---|---|---|
| 消息分配 | 打散到所有分区缓存区 | 集中轰炸单个分区缓存区 |
| Batch 状态 | 很难装满,多为“半空”状态 | 极易装满,多为“满载”状态 |
| 网络请求数 | 极多(大量小包) | 极少(少量大包) |
| 有效载荷比例 | 低(报文头开销占比大) | 极高(报文头开销被平摊) |
| 网络/CPU负载 | 高(频繁的网卡中断、系统调用) | 低(高效的批量 I/O) |
结论: 粘性分区策略完美地契合了 Kafka 面向“批处理”设计的核心思想。在网络传输性能上,它用最小的元数据开销、最少的系统调用次数,实现了最大的数据传输吞吐量。这也是为什么自 Kafka 2.4 之后,官方将其作为默认策略的原因。
右滑查看面试常问