Spring Cloud LoadBalancer 原理详解
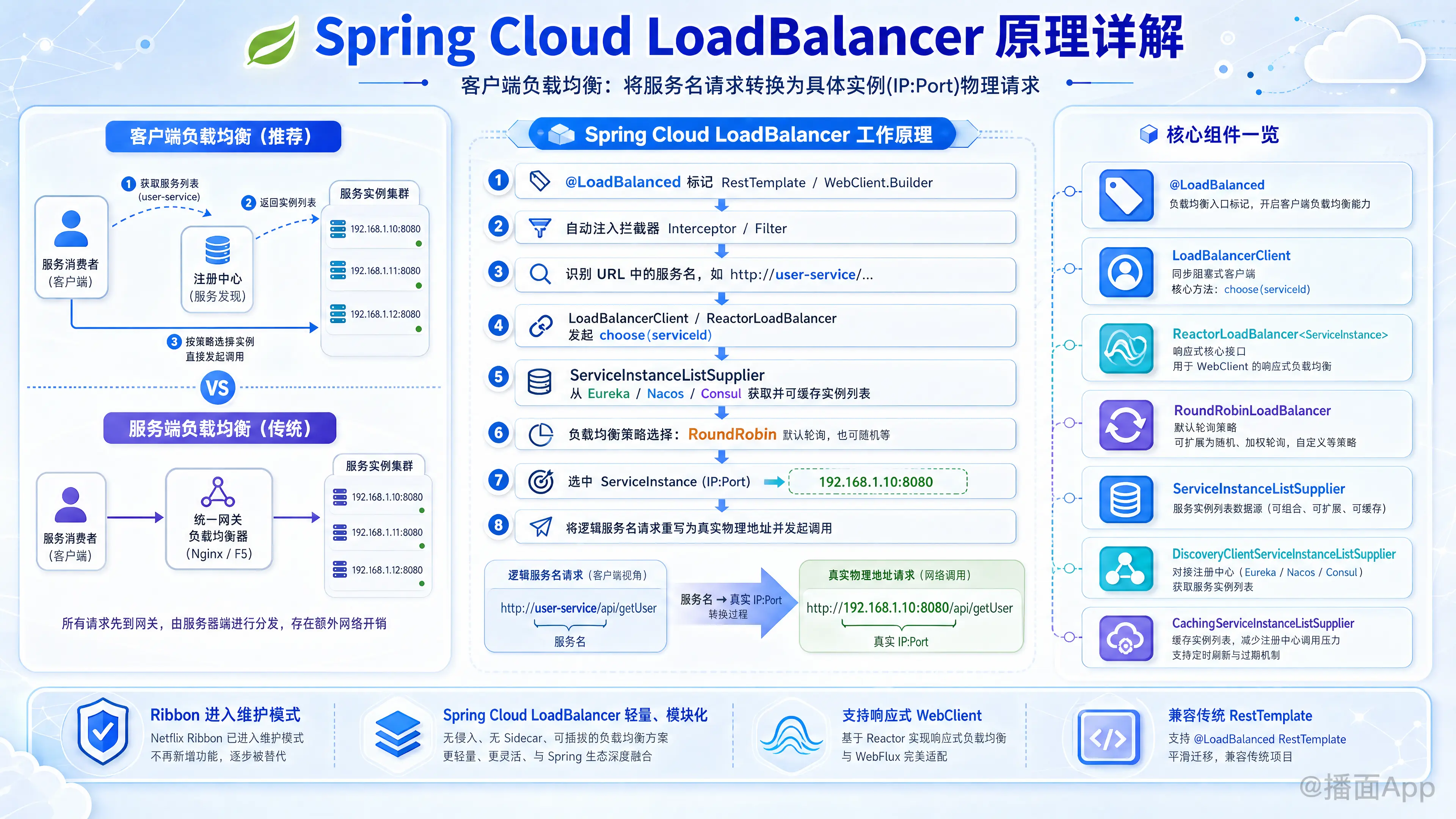
本文剖析Spring Cloud LoadBalancer工作原理:通过拦截器将服务名请求,经由服务发现、策略选择(如轮询)等步骤,最终转换为对具体服务实例(IP:Port)的物理请求,实现客户端负载均衡。
我们来深入、详细地剖析一下 Spring Cloud LoadBalancer 的工作原理。
Spring Cloud LoadBalancer 是 Spring Cloud 官方提供的客户端负载均衡器,用于替代进入维护模式的 Netflix Ribbon。它是一个轻量级、模块化、支持响应式编程的解决方案。
一、 核心思想:客户端负载均衡
首先要理解什么是客户端负载均衡。与 Nginx、F5 这类服务端负载均衡不同,客户端负载均衡器是集成在服务消费者(客户端)代码中的。
- 服务端负载均衡:客户端将请求发送给一个负载均衡服务器(如 Nginx),由该服务器根据策略将请求转发到后端的某一个服务实例。客户端对此过程无感知。
- 客户端负载均衡:客户端从服务注册中心(如 Eureka, Nacos, Consul)获取一个可用服务实例的列表,然后自己根据某种负载均衡策略(如轮询、随机)选择一个实例,直接向这个实例的 IP 和端口发起请求。
Spring Cloud LoadBalancer 正是实现了这一思想。
二、 背景:为什么需要 Spring Cloud LoadBalancer?
Netflix Ribbon 曾是 Spring Cloud 中默认的客户端负载均衡器,但它已经进入维护模式,不再积极开发。主要原因有:
- 阻塞式 API:Ribbon 的核心 API 是基于阻塞式 I/O 的,这与 Spring 5 之后大力推行的响应式编程模型(Project Reactor, WebFlux)不兼容。
- 技术栈老旧:依赖了一些较旧的库。
因此,Spring Cloud 团队开发了 Spring Cloud LoadBalancer,它基于响应式编程模型,能更好地与 WebClient 等非阻塞客户端集成,同时也完全兼容传统的 RestTemplate。
三、 核心组件
要理解其工作原理,首先要了解它的几个关键组件:
@LoadBalanced:- 这是一个标记注解。当你在
RestTemplate或WebClient.Builder的 Bean 上添加此注解时,Spring 会自动为其配置一个拦截器(Interceptor/Filter),这个拦截器就是实现负载均衡的关键入口。
- 这是一个标记注解。当你在
LoadBalancerClient:- 这是一个核心接口,提供了负载均衡的基本操作。它最重要的方法是
choose(String serviceId),用于根据服务 ID 选择一个ServiceInstance(服务实例)。
- 这是一个核心接口,提供了负载均衡的基本操作。它最重要的方法是
ReactorLoadBalancer<ServiceInstance>:- 这是负载均衡器的响应式核心接口。它定义了
choose()方法,返回一个Mono<Response<ServiceInstance>>。所有负载均衡算法(如轮询、随机)都是这个接口的实现。 - 默认实现是
RoundRobinLoadBalancer(轮询)。
- 这是负载均衡器的响应式核心接口。它定义了
ServiceInstanceListSupplier:- 这是整个机制的数据源,负责提供可用服务实例的列表。它是一个非常灵活的设计,通过责任链模式组合了多个功能。
- 常见的
Supplier实现:DiscoveryClientServiceInstanceListSupplier:最基础的 Supplier,它通过DiscoveryClient(服务发现客户端) 从 Eureka, Nacos 等注册中心获取原始的服务实例列表。CachingServiceInstanceListSupplier:在其上层包装一层缓存,避免每次请求都去查询注册中心,提高性能。HealthCheckServiceInstanceListSupplier:在缓存层之上,它会定期或在获取实例后对实例进行健康检查,并过滤掉不健康的实例。ZonePreferenceServiceInstanceListSupplier:用于实现区域(Zone)亲和性的负载均衡,优先选择同一区域内的服务实例。
拦截器/过滤器:
LoadBalancerInterceptor:用于RestTemplate。它会拦截RestTemplate的请求。ReactorLoadBalancerExchangeFilterFunction:用于WebClient。它是一个ExchangeFilterFunction,会拦截WebClient的请求。
四、 工作原理详解(以 RestTemplate 为例)
下面是 Spring Cloud LoadBalancer 的完整工作流程,一步步拆解:
场景:一个服务 A(消费者)通过 RestTemplate 调用服务 B(提供者),URL 为 http://service-b/api/users。
请求发起:
- 服务 A 的代码调用
restTemplate.getForObject("http://service-b/api/users", String.class)。
- 服务 A 的代码调用
拦截请求:
- 由于
RestTemplateBean 上标注了@LoadBalanced,Spring 自动配置的LoadBalancerInterceptor会拦截这个请求。 - 拦截器发现 URL 的 host 部分 (
service-b) 不是一个标准的 IP 地址或域名,它会将其识别为一个服务 ID (Service ID)。
- 由于
选择服务实例 (The Core Logic):
- 拦截器调用
LoadBalancerClient的execute方法。 LoadBalancerClient内部会委托给ReactorLoadBalancer(例如默认的RoundRobinLoadBalancer)来选择一个实例。ReactorLoadBalancer的choose()方法被调用。
- 拦截器调用
获取可用实例列表 (ServiceInstanceListSupplier 的工作):
ReactorLoadBalancer首先会调用ServiceInstanceListSupplier来获取一个service-b的可用实例列表。- 这个过程通常是链式的:
a. 健康检查层 (HealthCheckServiceInstanceListSupplier) 向下请求实例列表。
b. 缓存层 (CachingServiceInstanceListSupplier) 检查缓存中是否有service-b的实例列表并且未过期。如果有,直接返回;如果没有,向下请求。
c. 服务发现层 (DiscoveryClientServiceInstanceListSupplier) 调用DiscoveryClient,向 Nacos 或 Eureka 发起请求,获取service-b的所有注册实例(例如:192.168.1.100:8080,192.168.1.101:8081)。
d. 列表返回后,缓存层会将其缓存起来。
e. 健康检查层会(异步地)对列表中的实例进行健康检查,将不健康的实例暂时排除。最终,一个健康的、可用的实例列表被返回给ReactorLoadBalancer。
执行负载均衡策略:
RoundRobinLoadBalancer拿到健康的实例列表后,会根据其内部的计数器,采用轮询算法选择一个ServiceInstance。例如,第一次选择了192.168.1.100:8080。
重构 URL 并执行请求:
LoadBalancerInterceptor拿到了选择出的ServiceInstance对象。- 它从
ServiceInstance中获取真实的host(192.168.1.100) 和port(8080)。 - 然后,它将原始的 URL
http://service-b/api/users重构为真实的物理地址 URLhttp://192.168.1.100:8080/api/users。 - 最后,拦截器使用
RestTemplate内部的ClientHttpRequest对这个重构后的 URL 发起真正的 HTTP 请求。
返回响应:
- 服务 B (
192.168.1.100:8080) 处理请求并返回响应。 - 响应沿着调用链返回给服务 A 的业务代码。
- 服务 B (
下一次同样的请求,RoundRobinLoadBalancer 可能会选择 192.168.1.101:8081,从而实现了负载均衡。
工作流程图
[客户端代码]
|
v
restTemplate.get("http://service-b/api/users")
|
v
[LoadBalancerInterceptor] (拦截请求)
|
v
[LoadBalancerClient.choose("service-b")] (选择实例)
|
v
[ReactorLoadBalancer (e.g., RoundRobin)] (执行策略)
|
|--- 1. 调用 ServiceInstanceListSupplier 获取实例列表 ---
| |
| v
| [HealthCheck Filter] (过滤不健康实例)
| |
| v
| [Caching Supplier] (检查/更新缓存)
| |
| v
| [DiscoveryClient Supplier] (从 Eureka/Nacos 获取)
| |
| v
| [返回健康的实例列表: [inst1, inst2, ...]]
|
|--- 2. 根据列表和策略选择一个实例 (e.g., inst1) ---
|
v
[返回选中的 ServiceInstance(192.168.1.100:8080)]
|
v
[LoadBalancerInterceptor] (重构 URL)
| "http://service-b/api/users" -> "http://192.168.1.100:8080/api/users"
v
[发起真正的 HTTP 请求到物理地址]
|
v
[获取响应并返回给客户端代码]五、 定制与配置
Spring Cloud LoadBalancer 提供了丰富的定制能力。
- 全局配置:可以通过
application.yml配置,例如健康检查的开关和周期。 - 按服务配置:使用
@LoadBalancerClient或@LoadBalancerClients注解,可以为特定的服务(serviceId)提供自定义的ReactorLoadBalancer或ServiceInstanceListSupplier实现,从而实现更复杂的负载均衡策略,如基于权重的轮询、灰度发布等。
示例:为 service-b 自定义负载均衡策略
@Configuration
// name = "service-b" 指定了只对这个服务生效
@LoadBalancerClient(name = "service-b", configuration = ServiceBConfiguration.class)
public class MyLoadBalancerConfig {
// 全局配置可以放在这里
}
class ServiceBConfiguration {
@Bean
public ReactorLoadBalancer<ServiceInstance> randomLoadBalancer(Environment environment,
LoadBalancerClientFactory loadBalancerClientFactory) {
String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME);
// 使用随机负载均衡器,而不是默认的轮询
return new RandomLoadBalancer(loadBalancerClientFactory
.getLazyProvider(name, ServiceInstanceListSupplier.class), name);
}
}总结
Spring Cloud LoadBalancer 的工作原理可以概括为:通过拦截器/过滤器,将基于服务名的逻辑请求,转换为基于 IP 地址的物理请求。 其核心在于一个灵活的、可插拔的服务实例供应链(ServiceInstanceListSupplier)和一个响应式的负载均衡策略执行器(ReactorLoadBalancer)。这种设计使其不仅现代化、高性能,而且具有极高的扩展性。