B站视频播放量如果每次都直接写DB肯定扛不住,用Redis怎么设计这个计数器,并保证最终落库不丢失?
在B站这种千万级甚至亿级日活的平台,视频播放量(以及点赞、投币等)的更新频率极高。如果每次播放都直接执行 UPDATE table SET views = views + 1,数据库的行锁竞争和磁盘 I/O 会瞬间把 DB 打挂。
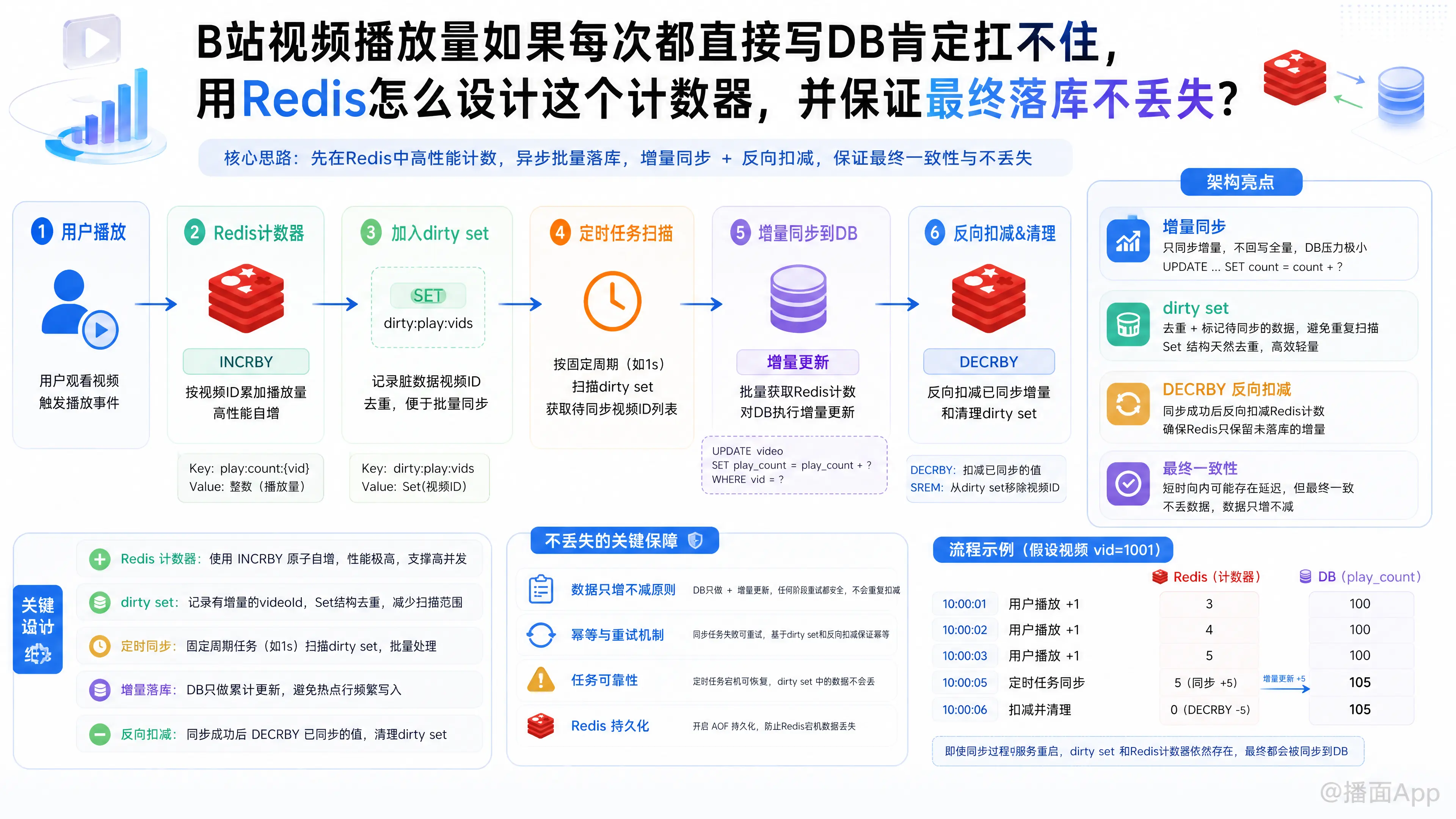
使用 Redis 作为缓冲层是标准做法,但要解决高并发写入、热点视频(Hot Key)以及同步落库时不丢数据的问题,需要一套严密的系统设计。
以下是完整的架构设计方案:
一、 核心设计思想:变“绝对总数”为“增量同步”
不要在 Redis 中维护视频的“总播放量”(总播放量应该以 DB 为准),而是在 Redis 中维护“增量(Delta)”。
1. Redis 数据结构设计
我们需要两个结构来配合:
- 增量计数器 (String):记录自上次落库以来的新增播放量。
- Key:
video:views:delta:{video_id} - Value: 新增的播放次数。
- 操作:
INCR或INCRBY
- Key:
- 脏数据集合 (Set):记录哪些视频的播放量发生了变化,方便后台任务知道该去抓取哪些 Key 写入 DB,避免全量扫描。
- Key:
video:views:dirty_set - Value: 发生改变的
{video_id} - 操作:
SADD
- Key:
2. 播放动作触发时的流程
当用户观看视频触发播放量增加时:
# 1. 增加该视频的增量
INCR video:views:delta:1001
# 2. 将该视频ID加入待同步集合
SADD video:views:dirty_set 1001(这两个操作可以通过 Redis Pipeline 或 Lua 脚本打包,减少网络开销)
二、 如何保证最终落库不丢失?(解决并发与宕机痛点)
把 Redis 数据同步到 DB,最容易犯的错误是:“读出 Redis 数量 -> 写入 DB -> 删除 Redis Key”。如果在这三步之间又有用户播放了视频,删除 Key 的操作就会把这部分新播放量误删,导致数据丢失。
为了绝对保证不丢数据,我们采用 “读取 -> DB累加 -> 反向扣减” 的模式。
同步落库的闭环流程(定时任务/异步线程执行):
- 获取发生变化的视频 ID 批次:
从 Set 中取出一批待更新的视频 ID。SRANDMEMBER video:views:dirty_set 100(或使用SSCAN) - 获取增量:
遍历这批 ID,获取当前的增量播放数。假设拿到video_id=1001的增量是50。GET video:views:delta:1001 - 写入数据库(批量处理):
在 DB 中执行增量更新(注意是+ 50,而不是直接SET = 50)。sqlUPDATE video_table SET views = views + 50 WHERE video_id = 1001; - 安全清理 Redis(关键点):
DB 更新成功后,千万不能 DEL key!而是把你刚才读到的数值(50)给减掉。DECRBY video:views:delta:1001 50 - 清理集合:
如果DECRBY之后的值变成了0,说明期间没有新的增量,可以从 Set 中移除。SREM video:views:dirty_set 1001
为什么这样不丢数据?
如果在你执行第2步(读出50)和第4步(扣减50)之间,又有 10 个用户看了视频,Redis 中的值会变成 60。当你执行 DECRBY ... 50 后,Redis 里的值还剩下 10。这 10 个播放量会在下一次定时任务中被同步,完美避免了并发导致的数据丢失。同时,如果第3步DB挂了,第4步就不会执行,数据依然安全保留在 Redis 中。
三、 应对极端高并发:如何处理“现象级爆款视频”?
当 B 站出现类似《黑神话悟空》实机演示这种千万级并发的爆款视频时,单一的 Redis INCR 依然可能遇到网络带宽或单节点 CPU 瓶颈(Hot Key 问题)。
升级方案 1:应用层本地内存合并(Local Cache Batching)
不要每次播放都去请求 Redis。在每台业务服务器(Java/Go 进程)内部,使用 Guava 或 Caffeine 做一个本地聚合。
- 服务器 A 接收到爆款视频 1001 的 500 次播放请求,在本地内存中累加
count=500。 - 每隔 1~3 秒,服务器 A 将这 500 次聚合,作为一次请求发送给 Redis:
INCRBY video:views:delta:1001 500。 - 效果:即使 QPS 是 100万,打到 Redis 上的写 QPS 也会降到几百(取决于应用服务器节点数量),彻底解决热点问题。
升级方案 2:防刷与去重(UV vs PV)
播放量通常不是单纯的 PV(刷新页面就加 1),需要有一定的防刷机制。
- 在写入增量之前,可以结合 Redis 的
HyperLogLog(统计算法) 或者简单的SETNX (user_id + video_id)做短时间内的去重,校验通过后才执行上述的INCR。
四、 应对 Redis 宕机:如何做到真正的“零丢失”?
必须要承认,即使做了 AOF(Append Only File)每秒刷盘,如果 Redis 服务器突然断电,依然存在丢失这 1 秒内数据的理论可能。
如果业务要求绝对的金融级不丢失(虽然播放量通常不需要这么严格,但如果是“投币”或“充电”金额则必须),单纯依靠 Redis 写盘是不够的,必须引入 消息队列(MQ)。
B站真实的工业级架构(Kafka + Flink + Redis + DB):
- 消息发送:用户看完视频 -> 前端上报埋点 -> 网关直接将“播放事件”写入 Kafka。只要 Kafka 写入成功(acks=all),数据就绝对不会丢。
- 实时流处理(写 Redis 供前端展示):Flink 消费 Kafka,进行窗口聚合(比如每 5 秒聚合一次),把结果更新到 Redis。前端直接读取 Redis 里的总数展示给用户看,保证实时性。
- 异步落库(写 DB 保证持久化):另一路消费者批量拉取 Kafka 消息,或者 Flink 将聚合后的数据按批次执行
UPDATE db SET views = views + X。
五、 总结与选型建议
- 中小型规模 / 追求开发效率:
采用 “Redis 增量计数 (INCR) + 脏数据集 (Set) + DECRBY 安全扣减同步”。足以支撑绝大多数高并发场景,兼顾了性能和最终一致性。 - 现象级高并发:
在方案 1 的基础上,增加 “应用层本地缓存聚合 (Local Buffer)”,把打向 Redis 的流量降低千倍。 - B站亿级规模 / 绝对零丢失:
引入 Kafka 作为数据的“蓄水池”。Redis 退化为纯粹的读缓存,所有的更新由 MQ 消费驱动,彻底解耦,保证极致的高可用与数据安全。