机房网络波动导致Redis集群短时间不可用,如何设计降级策略避免DB被打挂(缓存雪崩)
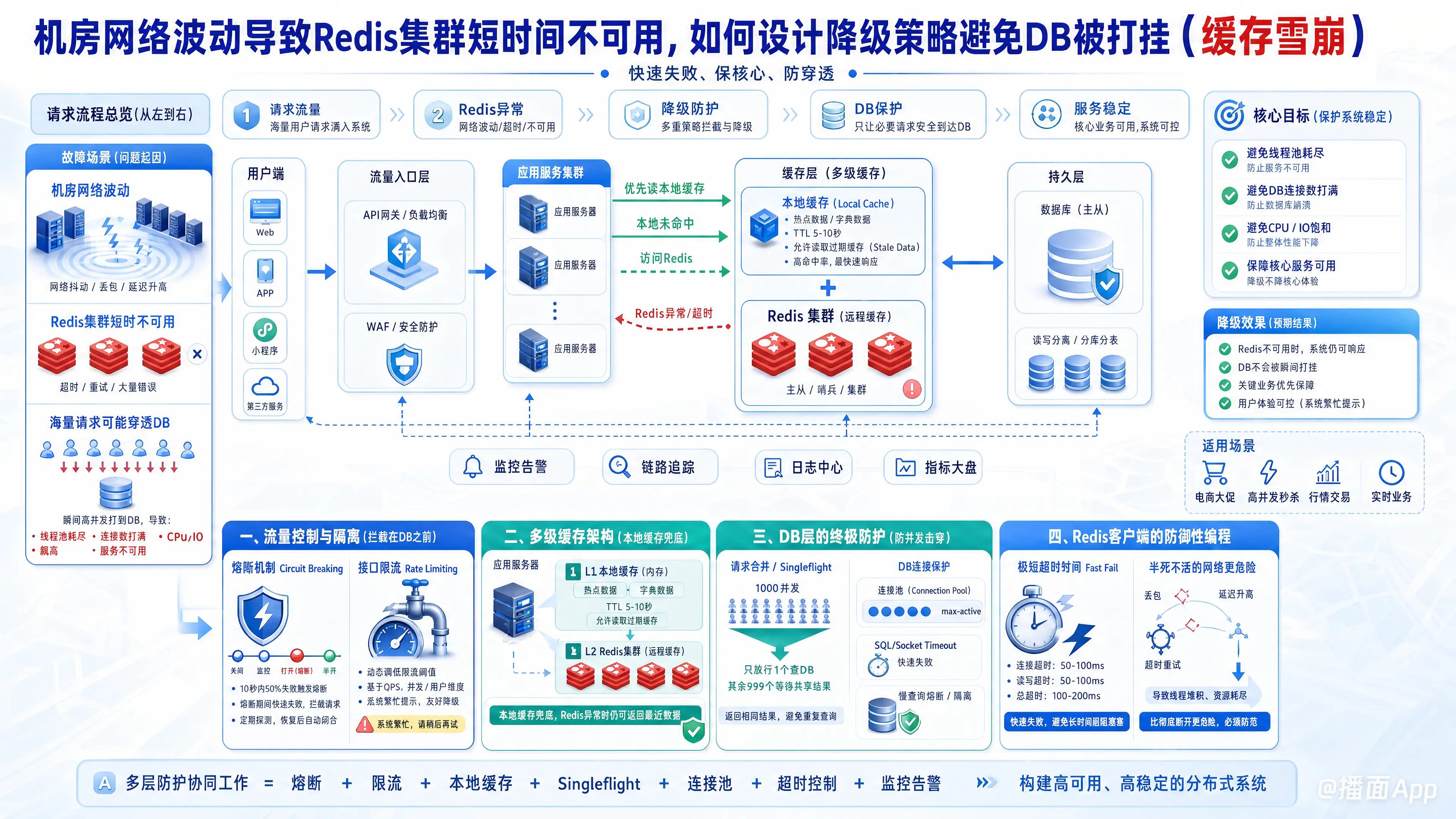
机房网络波动导致 Redis 集群短时间不可用,是典型的引发缓存雪崩的场景。此时如果所有原本打向 Redis 的海量读写请求全部穿透到数据库(DB),DB 会在瞬间因为连接数耗尽、CPU 打满或 IO 饱和而宕机,进而引发整个系统的瘫痪。
为了避免这种情况,系统设计必须遵循“快速失败、保核心、防穿透”的原则。以下是多维度的降级与防护策略设计:
一、 流量控制与隔离(拦截在 DB 之前)
这是最外层的防御,目的是控制进入 DB 的总流量,确保 DB 只处理其能力范围内的请求。
1. 熔断机制(Circuit Breaking)
- 策略:在业务应用与 Redis 客户端之间引入熔断器(如 Sentinel, Resilience4j)。当探测到 Redis 响应超时或失败率达到阈值(例如 10秒内 50% 请求失败),立即触发熔断。
- 效果:熔断后,业务应用不再尝试连接 Redis,避免大量线程阻塞等待 Redis 响应而导致应用服务器线程池耗尽。
2. 接口限流(Rate Limiting)
- 策略:在网关层或服务层对高频接口进行限流。当 Redis 不可用触发降级时,动态调低限流阈值,使其匹配 DB 的真实吞吐能力(通常 DB 的 QPS 处理能力只有 Redis 的 1/10 甚至更低)。
- 效果:超出的流量直接返回“系统繁忙,请稍后再试”,宁可牺牲部分用户的体验,也要保住 DB 不挂。
二、 多级缓存架构(本地缓存兜底)
当远端 Redis 不可用时,应用服务器的本地内存是最好的降级替代品。
1. 引入本地缓存(Local Cache)
- 策略:采用
Caffeine(Java)、Go-Cache等构建 Local Cache + Redis 的多级缓存架构。对于高频读取的“热点数据”和“字典类数据”,在本地缓存一份。 - 应对波动:当 Redis 连不上时,降级读取本地缓存。即使本地缓存的数据有轻微延迟(例如设置了 5-10 秒的 TTL),在短时网络波动期间也是完全可以接受的(最终一致性)。
2. 本地缓存的降级模式
- 正常情况下,本地缓存 TTL 很短,依赖 Redis 更新。
- 当触发 Redis 熔断时,可以暂时延长本地缓存的过期时间(返回旧数据),或者允许直接读取已过期的本地缓存数据(Stale Data),直到 Redis 恢复。
三、 DB 层的终极防护(防并发击穿)
即使有降级和限流,依然会有部分请求打到 DB,此时必须防止并发查询同一条数据把 DB 打挂。
1. 请求合并 / 并发控制(Singleflight)
- 策略:当 1000 个并发请求同时查询同一个 Key,且 Redis 挂了,绝对不能让这 1000 个请求同时打到 DB。使用
Singleflight模式(Go 语言标准库有golang.org/x/sync/singleflight,Java 可以用ConcurrentHashMap+CountDownLatch或分布式锁机制的本地化版本实现)。 - 效果:1000 个请求中,只放行 1 个请求去查询 DB,其余 999 个请求阻塞等待。等这 1 个请求从 DB 拿到数据后,共享给另外 999 个请求。极大地保护了 DB。
2. DB 连接池与超时控制
- 严格限制最大连接数:绝不能配置无限大的 DB 连接池,配置合理的
max-active。 - 快速失败的 SQL 超时:将 DB 的查询超时时间(Socket Timeout / Statement Timeout)设置得更严格。遇到慢查询尽早掐断,防止连接被长期占用。
四、 Redis 客户端的防御性编程
网络波动时最怕的是“半死不活”(TCP 丢包导致的大量超时),这比彻底断网更可怕。
1. 极短的超时时间(Fast Fail)
- 设置极短的 Redis 连接超时(Connect Timeout)和读取超时(Read Timeout),例如 50ms - 100ms。
- 一旦超时,立刻抛出异常并走降级逻辑,绝不让请求在 Redis 客户端处长时间阻塞。
2. 谨慎的重试策略
- 网络波动时,严禁使用无脑的同步重试(会导致重试风暴,加剧网络拥塞)。
- 如果必须重试,最多重试 1 次,或者采用指数退避(Exponential Backoff)的异步重试。
五、 业务维度的优雅降级(核心与非核心分离)
在系统设计之初,就应该对业务进行分级(核心业务 vs 非核心业务)。
1. 非核心业务:直接阻断
- 例如:用户头像加载、评论点赞数、推荐列表、排行榜等。
- 策略:Redis 挂了,直接返回空列表、默认值、或者隐藏该模块。绝对不查 DB。
2. 核心业务:有限度放行 + 异步削峰
- 例如:交易下单、支付状态查询。
- 策略:读请求通过 Singleflight 打到 DB;写请求如果原本强依赖 Redis(如扣减库存),可降级为写入本地消息表或发往 MQ(消息队列),由消费者异步在 DB 中排队执行,将突发写流量削峰填谷。
总结:标准处理流程 (SOP)
当机房网络波动发生时的系统表现应该是这样的:
- 0-1秒:Redis 出现大面积超时,应用端因为设置了 100ms 超时(快速失败),线程没有被大量阻塞。
- 1-3秒:由于超时错误激增,Sentinel/Resilience4j 触发熔断,切断与 Redis 的交互。
- 3秒-恢复前:
- 非核心接口:直接返回默认值或空数据(业务降级)。
- 核心读接口:优先读取 Local Cache。未命中的请求,经过 限流器 和 Singleflight(请求合并) 后,以极低的并发量进入 DB。
- 核心写接口:转入 MQ 异步处理。
- 网络恢复后:熔断器进入半开(Half-Open)状态,放行少量请求探测 Redis。探测成功后,熔断器闭合,系统平滑恢复到正常状态。
右滑查看面试常问