客户端在作业运行期间,是如何获取作业执行进度和状态的?
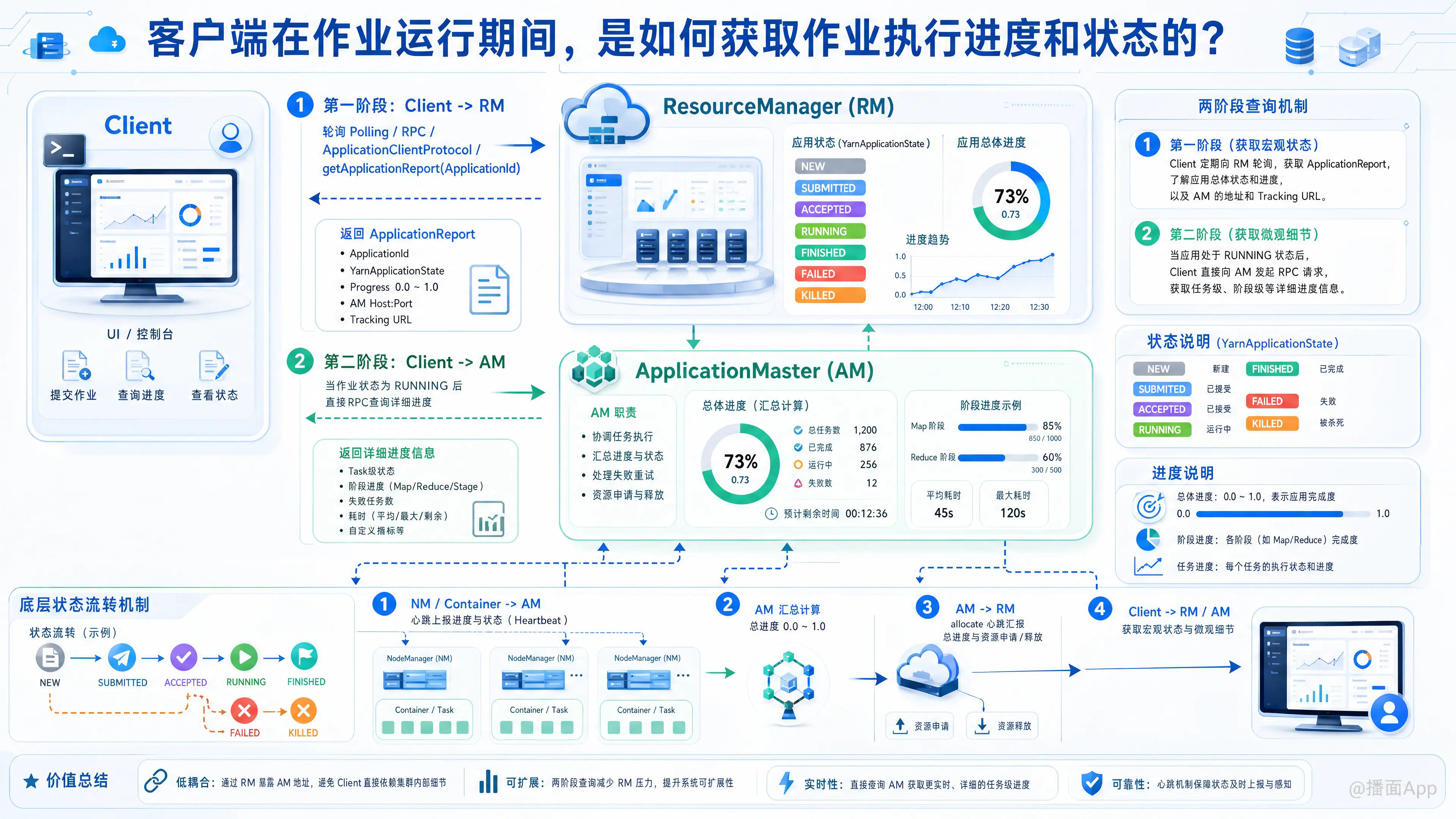
在 Apache YARN 架构中,客户端(Client)在作业运行期间获取作业执行进度和状态的过程是一个分层查询、基于轮询(Polling)的机制。
为了高效且不过度增加系统负载,YARN 将“整体状态”和“详细进度”的管理分离开来。具体来说,客户端主要与 ResourceManager (RM) 和 ApplicationMaster (AM) 两个组件进行交互。
以下是详细的获取流程和内部机制:
1. 核心交互流程(客户端视角)
第一阶段:向 ResourceManager (RM) 查询宏观状态
- 获取 ApplicationId:客户端在提交作业时,会从 RM 获得一个全局唯一的
ApplicationId。 - 轮询 RM:在作业刚提交(处于
NEW,SUBMITTED,ACCEPTED状态)或运行期间,客户端会通过 RPC 接口(ApplicationClientProtocol)定期向 RM 发送状态查询请求(如getApplicationReport(ApplicationId))。 - 获取 ApplicationReport:RM 会返回一个包含作业宏观信息的报告,主要包括:
- YARN 状态 (YarnApplicationState):如
ACCEPTED(已接受等待资源)、RUNNING(正在运行)、FINISHED、FAILED、KILLED。 - 聚合进度 (Progress):一个从 0.0 到 1.0 的浮点数(即 0% 到 100%)。
- AM 的地址 (Host:Port):如果作业已进入
RUNNING状态,报告中会包含该作业对应的 ApplicationMaster 的网络地址。 - Tracking URL:指向 AM Web UI 的链接,供用户通过浏览器查看详细信息。
- YARN 状态 (YarnApplicationState):如
第二阶段:向 ApplicationMaster (AM) 查询微观进度(针对特定计算框架)
虽然 RM 知道作业完成了百分之几,但它不知道具体的任务细节(比如 MapReduce 中的 Map 阶段完成了多少,Reduce 阶段完成了多少,或者 Spark 的某个 Stage 运行到哪了)。
- 当客户端发现作业处于
RUNNING状态,并且需要获取更详细的进度(如 Task 级别的状态)时,客户端会直接通过 RPC 连接到 ApplicationMaster。 - AM 负责具体应用程序的调度和监控,它掌握着所有底层 Container(Task)的实时状态。
- 客户端向 AM 发送查询请求,AM 返回详细的执行进度、失败的任务数、各个阶段的耗时等框架特定的信息。
2. YARN 内部的状态流转机制(底层视角)
客户端之所以能查询到最新的状态,依赖于 YARN 内部组件之间持续的心跳汇报(Heartbeat)机制:
- NodeManager (NM) -> ApplicationMaster (AM):
运行在各个节点上的任务(Container)会向管理它们的 AM 汇报进度和状态(比如读取了多少字节,处理了多少条记录)。 - ApplicationMaster (AM) 汇总:
AM 收集所有 Task 的进度,按照特定框架的逻辑(如 MapReduce 逻辑或 Spark 逻辑)计算出一个总进度值(0.0 - 1.0)。 - ApplicationMaster (AM) -> ResourceManager (RM):
AM 会定期(通常是每隔几秒)向 RM 发送心跳请求(allocate请求)。在这个心跳中,除了申请或释放资源外,AM 会将计算好的总进度汇报给 RM。 - Client -> RM / AM:
此时,客户端向 RM 查询时,RM 就能把 AM 最新汇报的总进度返回给客户端;若向 AM 查询,就能得到最新的详细细节。
3. 客户端获取状态的具体方式(用户接口)
在实际使用中,用户或客户端程序可以通过以下几种途径获取进度和状态:
- 命令行工具 (CLI):
用户可以在终端执行命令,底层本质是客户端代码在轮询 RM:yarn application -status <ApplicationId> - Web UI (浏览器):
- 访问 RM 的 Web 界面(默认端口 8088),可以看到所有作业的列表和总进度。
- 点击某个作业的
Tracking UI(ApplicationMaster 链接),会被重定向到 AM 提供的专属页面,查看详细的 Task/Stage 进度。
- REST API:
YARN 提供了丰富的 REST API,方便第三方系统(如调度系统、监控大盘)集成:GET http://<rm-http-address:port>/ws/v1/cluster/apps/<appid> - Java API:
开发者可以直接使用 Hadoop 的YarnClient类:javaYarnClient yarnClient = YarnClient.createYarnClient(); yarnClient.init(conf); yarnClient.start(); ApplicationReport report = yarnClient.getApplicationReport(appId); System.out.println("状态: " + report.getYarnApplicationState()); System.out.println("进度: " + report.getProgress());
总结
在 YARN 中,客户端在作业运行期间获取状态遵循“整体看 RM,细节找 AM”的原则。底层依赖于任务到 AM、AM 到 RM 的层层心跳汇报机制,而客户端则是通过定期拉取(Pull/Polling)的方式从 RM 或 AM 获取这些聚合后的信息。
右滑查看面试常问