JobHistoryServer 和 YARN Timeline Server 有什么区别?
JobHistoryServer 和 YARN Timeline Server 都是 Hadoop 生态系统中用于查看历史任务信息的组件,但它们的设计初衷、适用范围和底层架构有着本质的区别。
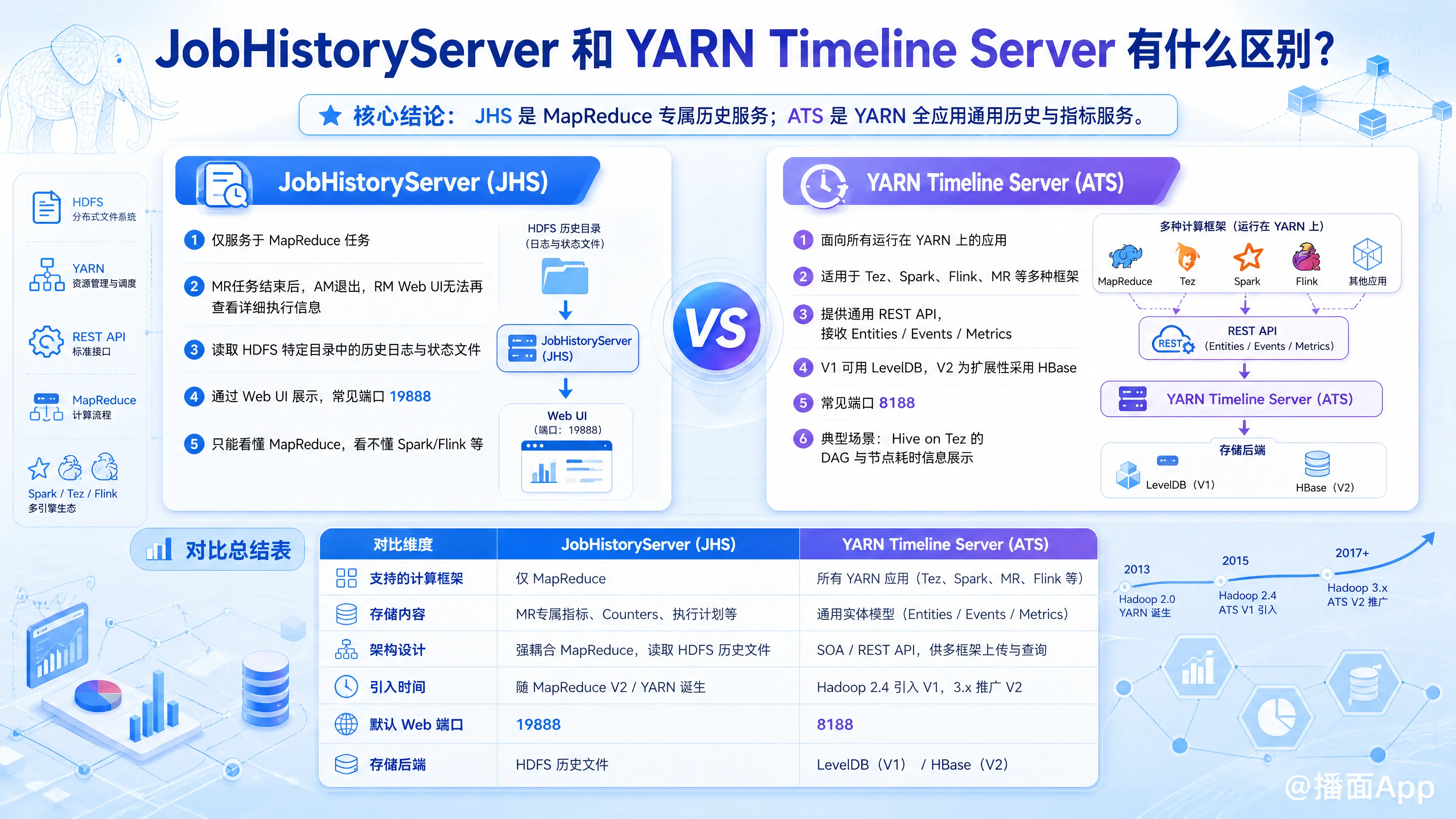
简单来说:JobHistoryServer 是专门为 MapReduce 定制的,而 YARN Timeline Server 是为所有运行在 YARN 上的通用应用(如 Spark、Tez、Flink 等)设计的。
以下是详细的区别和对比:
1. JobHistoryServer (JHS)
- 专属领域:仅服务于 MapReduce 任务。
- 为什么需要它:在 YARN 架构中,当一个 MapReduce 任务运行结束时,管理该任务的 ApplicationMaster (AM) 也会随之退出并销毁。这意味着你无法再通过 ResourceManager 的 Web UI 查看该任务的详细信息(如 Map/Reduce 阶段的耗时、计数器、具体报错日志等)。
- 工作原理:MapReduce 任务在运行和结束时,会将日志和状态信息写入 HDFS 的特定目录。JobHistoryServer 会监控并读取这些 HDFS 上的文件,然后通过 Web UI(通常是
19888端口)展示给用户。 - 局限性:它完全看不懂除了 MapReduce 以外的任何任务。如果你在 YARN 上跑了一个 Spark 或 Flink 任务,JobHistoryServer 对此一无所知。
2. YARN Timeline Server (ATS)
- 专属领域:服务于所有 YARN 上的应用(跨计算框架)。
- 为什么需要它:随着 Hadoop 的发展,YARN 上不再只有 MapReduce,还跑着 Tez、Spark、Flink 等多种计算框架。Hadoop 社区意识到,需要一个通用的历史信息收集和展示服务,来记录所有 YARN 应用的生命周期和指标,而不是让每个框架都自己去写一个类似 JobHistoryServer 的东西。
- 工作原理:它提供了一套通用的 REST API,不同的计算框架(如 Spark, Tez)可以将自己的特定事件(Event)、实体(Entity)和指标(Metrics)推送到 Timeline Server。Timeline Server 会将这些信息持久化存储(V1 版本存在本地 LevelDB,V2 版本为了解决扩展性问题使用了 HBase)。
- 典型应用场景:Hive on Tez 的底层执行引擎是 Tez,Tez 任务的执行图(DAG)、每个节点的耗时等详细信息,就是通过 YARN Timeline Server 来存储并由 Tez UI 展示的。
3. 核心对比总结表
| 对比维度 | JobHistoryServer (JHS) | YARN Timeline Server (ATS) |
|---|---|---|
| 支持的计算框架 | 仅 MapReduce | 所有 YARN 应用 (Tez, Spark, MR, Flink 等) |
| 存储内容 | MapReduce 的专属指标(Map/Reduce 任务数、Counters、执行计划等) | 通用的实体模型(Entities, Events, Metrics),由各个框架自定义上传的内容。 |
| 架构设计 | 强耦合于 MapReduce 模型,读取 HDFS 上的特定格式历史文件。 | 面向服务(SOA),提供统一的 REST API 供不同框架调用上传和查询。 |
| 引入时间 | 伴随 MapReduce V2 (YARN) 诞生。 | 较晚引入 (Hadoop 2.4 开始引入 V1,Hadoop 3.x 推广 V2)。 |
| 默认 Web 端口 | 通常是 19888 |
通常是 8188 |
| 存储后端 | HDFS 分布式文件系统 (存放 .jhist 文件) |
LevelDB (ATS V1) 或 HBase (ATS V2) |
4. 举个实际的例子来理解
假设你的集群里同时运行了两个任务:
- 任务 A: 一个传统的 MapReduce WordCount 程序。
- 任务 B: 一个 Spark SQL 查询任务。
当这两个任务结束后,如果你想看历史执行情况:
- 你想看任务 A (MR) 有多少个 Map task,每个拉取了多少数据?你需要去 JobHistoryServer 的页面看。
- 你想看任务 B (Spark) 的详细执行计划?JobHistoryServer 里根本找不到任务 B。你需要依赖 Spark 自己的 Spark History Server,而如果你的集群配置了深度集成,Spark 也可以将通用生命周期事件注册到 YARN Timeline Server 中供全局监控。
- 如果你跑的是 Hive on Tez,Tez 引擎没有任何类似于 JobHistoryServer 的独立常驻进程,它完全依赖 YARN Timeline Server 来存储历史作业信息。
总结
- JobHistoryServer 是旧时代的产物,是 MapReduce 的“专职历史记录员”。
- YARN Timeline Server 是新时代的通用基础设施,是整个 YARN 集群所有应用的“公共档案馆”。两者在现代 Hadoop 集群中通常是共存的。
右滑查看面试常问