如果NameNode的元数据(FsImage和EditLog)全部损坏了,应该如何恢复?
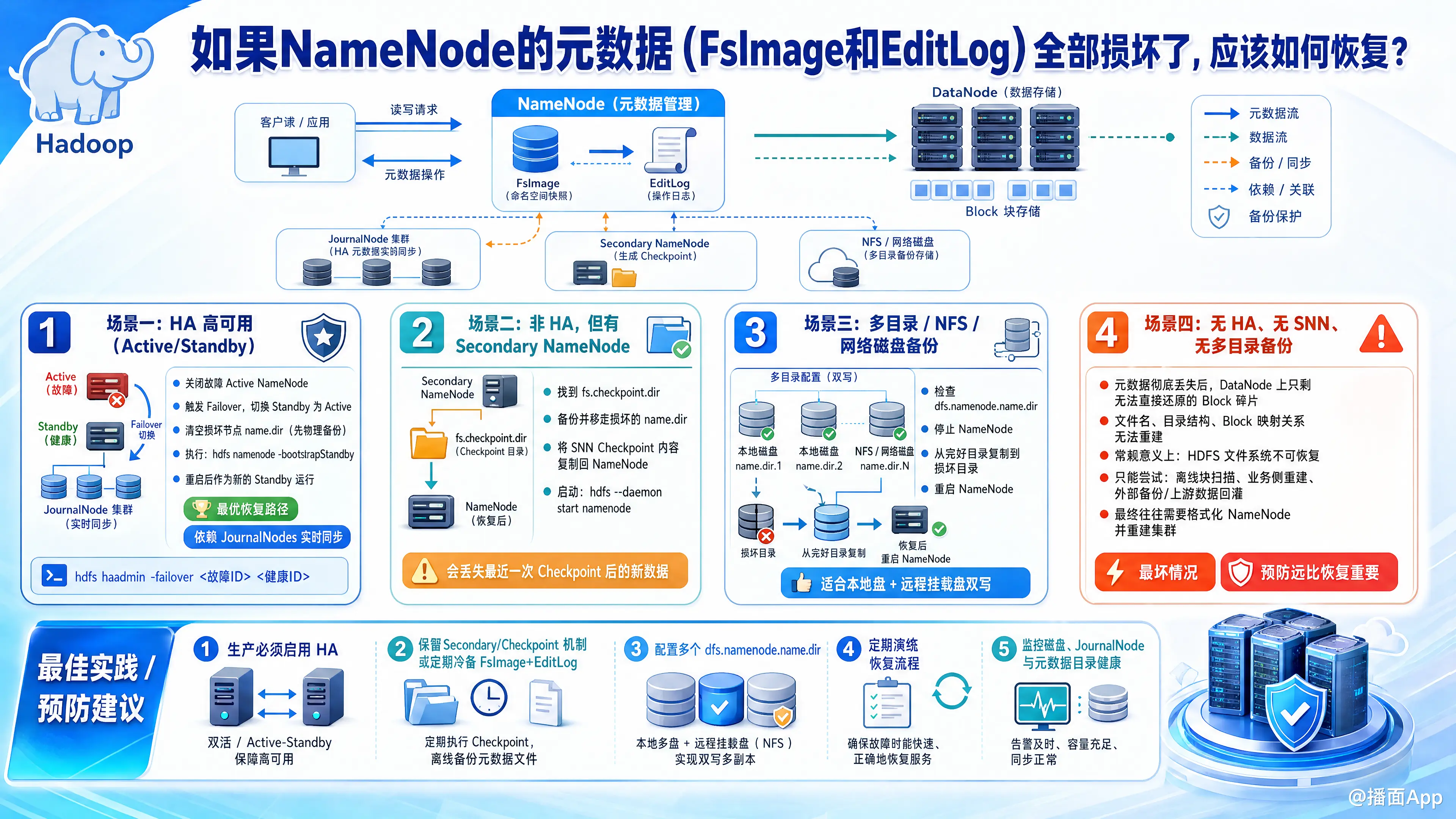
如果 HDFS NameNode 的元数据(FsImage 和 EditLog)全部彻底损坏且原节点无法读取,这是 Hadoop 集群中最严重的灾难性故障。因为 NameNode 的元数据记录了“文件名到数据块(Block)的映射关系”,如果没有这些元数据,DataNode 上存储的 PB 级数据块就只是一堆无法还原的无意义二进制碎片。
针对这种情况,恢复的成功率完全取决于你的集群架构和备份机制。请严格按照以下从“最优”到“最坏”的场景进行排查和恢复:
场景一:集群配置了高可用(HA,Active/Standby 架构)
这是最幸运的情况。HA 架构下,Standby NameNode 通过 JournalNodes 实时同步了 EditLog,并且自己也会定期生成 FsImage。
恢复步骤:
- 隔离故障节点:立刻关闭损坏的 Active NameNode 进程。
- 触发故障转移:如果配置了 ZKFC,集群会自动将 Standby NameNode 切换为 Active。如果没有自动切换,可以手动执行:bash
hdfs haadmin -failover <损坏的节点ID> <健康的节点ID> - 修复损坏的节点:
- 清空损坏节点上
hdfs-site.xml中dfs.namenode.name.dir指定的目录内容(确保清空前做个死马当活马医的物理备份)。 - 在损坏的节点上执行数据同步命令,从新的 Active 节点拉取元数据:bash
hdfs namenode -bootstrapStandby
- 清空损坏节点上
- 重新启动:启动修复后的 NameNode,它将作为新的 Standby 节点运行。
场景二:集群是非 HA 架构,但有 Secondary NameNode (SNN)
非 HA 架构下,如果有 Secondary NameNode,它会定期(默认每小时或 EditLog 达到 100万条时)合并 FsImage 和 EditLog,生成新的检查点(Checkpoint)。
恢复步骤:
- 定位 SNN 的元数据目录:查看 SNN 所在机器的
core-site.xml/hdfs-site.xml,找到fs.checkpoint.dir配置的路径。 - 备份现场:将主 NameNode 损坏的
dfs.namenode.name.dir目录改名或移走。 - 拷贝元数据:将 Secondary NameNode 的
fs.checkpoint.dir目录下的所有内容,原封不动地 SCP/拷贝到主 NameNode 的dfs.namenode.name.dir目录下。 - 启动 NameNode:bash
hdfs --daemon start namenode
⚠️ 注意:这种方法会丢失“上一次 Checkpoint 之后到宕机之间”产生的新数据(通常是最近一小时的数据),但能保住绝大部分历史数据。
场景三:配置了多个元数据存储目录(如 NFS/网络磁盘备份)
Hadoop 强烈建议在 dfs.namenode.name.dir 中配置多个目录(用逗号分隔),例如一个是本地磁盘,一个是远程 NFS 挂载盘。NameNode 会向这些目录同时写入元数据。
恢复步骤:
- 检查配置文件中的
dfs.namenode.name.dir。 - 如果配置了多个目录,并且其中某个目录(比如 NFS 目录)的数据没有损坏:
- 停止 NameNode。
- 清空损坏目录下的文件。
- 将完好目录下的所有文件复制到损坏目录下。
- 重启 NameNode。
场景四:没有任何备份(无 HA、无 SNN、无多目录备份)—— 最坏情况
如果你既没有 Standby 节点,也没有 Secondary NameNode 的检查点,也没有任何外部备份,那么整个文件系统的目录树、文件名、权限信息已经永久丢失。
DataNode 上仍然存有数据块(Block),但它们的文件名全是类似于 blk_1073741825 这样的格式。官方没有提供直接从 DataNode 逆向还原 NameNode 的工具。
极其无奈的挣扎方案(数据刮取/打捞):
- 停止一切写入:立刻停止整个集群。
- 寻找可用文件:
- 去各个 DataNode 的
${dfs.datanode.data.dir}/current/BP-.../current/finalized/目录下。 - 你会看到大量的
blk_xxxxx文件。 - 如果你的数据大部分是文本文件(TXT/CSV)且文件很小(小于 128MB,即一个文件只有一个 Block),你可以通过 Linux 脚本遍历这些 block,用
file命令或head命令查看内容,手动把有用的数据挑出来重命名。
- 去各个 DataNode 的
- 放弃并重建:对于大型集群或复杂文件(如 Parquet, ORC, 或跨越多个 Block 的大文件),人工拼接 Block 几乎是不可能的。你只能接受数据完全丢失的现实。
- 清理所有 DataNode 的数据目录。
- 重新格式化 NameNode:
hdfs namenode -format。 - 重新构建集群。
总结与血的教训(防范于未然)
如果这次你幸运地恢复了数据,或者不幸地丢失了数据,请务必在未来的架构中落实以下规范:
- 必须启用 HA(High Availability):生产环境绝对不能单点 NameNode,必须使用 QJM (Quorum Journal Manager) 配置 Active/Standby。
- 多目录存储:在
hdfs-site.xml中将dfs.namenode.name.dir配置为至少两个路径,其中一个挂载远程 NFS 或高可靠的存储上。 - 定期冷备:写一个 Cron 定时任务,每天深夜将 NameNode 的 FsImage 拷贝到其他服务器或云存储(如 S3/阿里云 OSS)上。