为什么JournalNode的数量通常是奇数个?
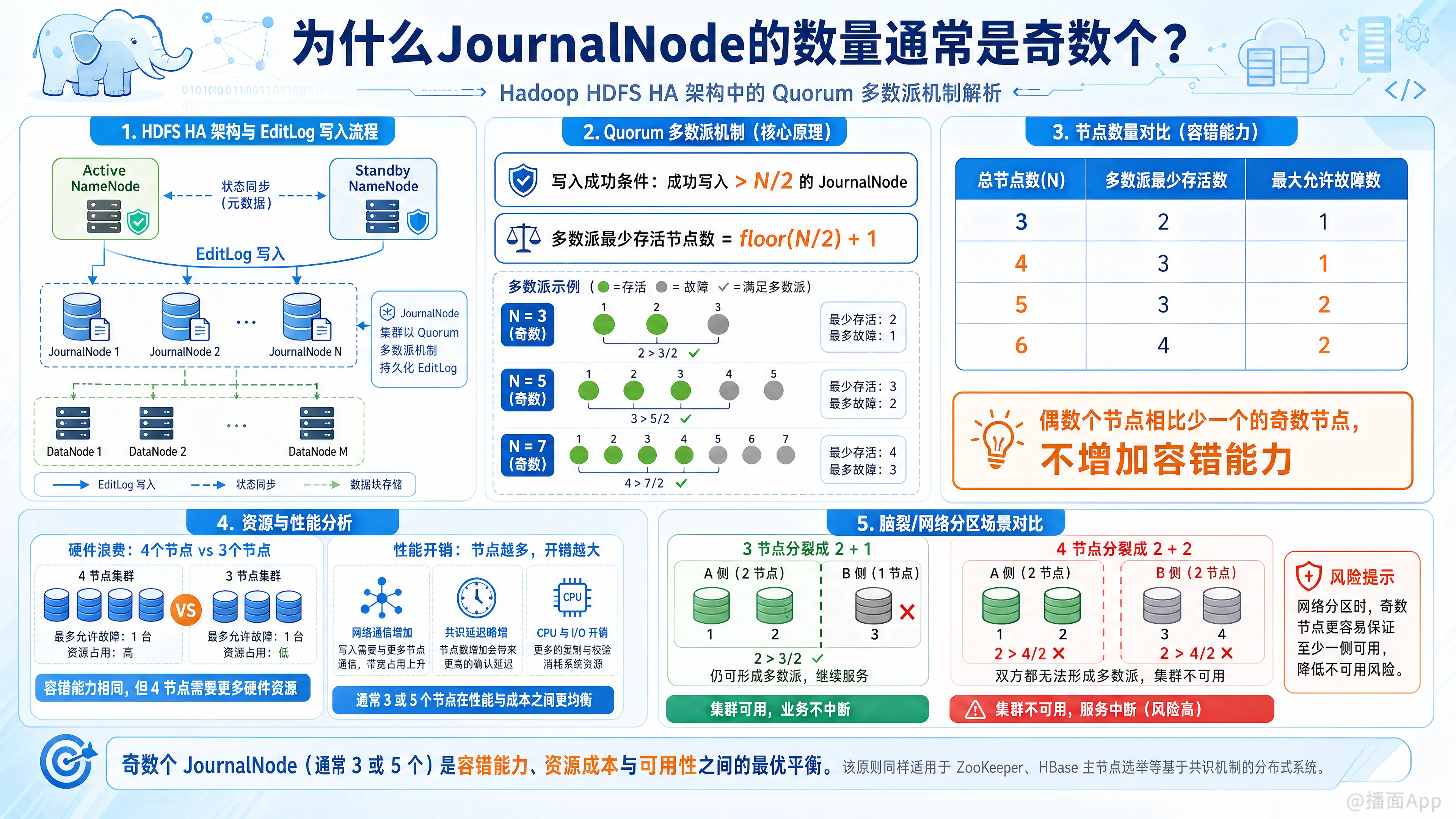
在Hadoop HDFS的高可用(HA)架构中,JournalNode(简称JN)的数量通常被要求或建议配置为奇数个(如3、5、7个)。这主要是由其底层的Quorum(多数派/过半)共识机制决定的。
具体原因可以从以下几个核心维度来理解:
1. Quorum(多数派)机制的数学逻辑
JournalNode集群在工作时,Active NameNode 必须成功将 EditLog(元数据修改日志)写入到 半数以上(> N/2) 的 JournalNode 中,这次写操作才算成功。
我们来对比一下奇数和偶数节点在容错能力上的数学差异:
- 公式:多数派要求的最少存活节点数 =
(N / 2) + 1(向下取整) - 允许宕机的节点数 =
总节点数 - 多数派最少节点数
| 总节点数 (N) | 多数派需要存活的最少节点数 | 最大允许宕机/故障的节点数 |
|---|---|---|
| 3 | (3/2)+1 = 2 | 3 - 2 = 1 |
| 4 | (4/2)+1 = 3 | 4 - 3 = 1 |
| 5 | (5/2)+1 = 3 | 5 - 3 = 2 |
| 6 | (6/2)+1 = 4 | 6 - 4 = 2 |
结论:
- 3个节点和4个节点,都只能容忍1个节点故障。
- 5个节点和6个节点,都只能容忍2个节点故障。
- 规律:偶数个节点(2N)相比于比它少一个的奇数个节点(2N-1),完全没有增加任何容错能力。
2. 避免资源浪费与性能损耗
既然4个节点和3个节点的容错能力完全一样(都只能坏1个),那么配置第4个节点就带来了以下劣势:
- 硬件浪费:白白多消耗了一台机器的计算、存储和网络资源。
- 性能开销:NameNode向JournalNode写入数据时,节点越多,网络通信的开销越大,集群达成共识的延迟可能会微弱增加。
3. 防范“脑裂”(Split-Brain)问题
在分布式系统中,如果发生网络故障导致集群被分割成两部分,Quorum机制可以完美防止“脑裂”(即两个NameNode都认为自己是Active并同时写数据):
- 如果是3个节点:网络断开变成
2个节点和1个节点的两部分。拥有2个节点的那边依然占大多数(2 > 3/2),可以继续工作;另一边则停止工作。 - 如果是4个节点:如果网络断开变成
2个节点和2个节点的两部分(对等分割)。因为2不大于4的一半(2不满足 > 4/2),两边都无法凑齐多数派(都需要3个),导致整个HDFS集群直接瘫痪。
可以看出,在某些特定的网络分区故障下,偶数节点反而比奇数节点更脆弱。
总结
配置奇数个JournalNode(通常是3个或5个)是基于性价比最高的容错设计。偶数个节点不仅不能提升系统的可用性,反而会浪费硬件资源,甚至在网络分区时增加集群完全不可用的风险。这也是为什么不仅是JournalNode,像ZooKeeper(Zookeeper集群)、HBase(RegionServer的主节点选举)等基于Paxos/Raft等共识算法的分布式系统,都强烈建议部署奇数个节点的原因。
右滑查看面试常问