HDFS HA架构中有哪些核心组件?(如Active NN, Standby NN, JournalNode, ZKFC等)
HDFS HA(High Availability,高可用)架构是为了解决早期 Hadoop 版本中 NameNode 存在的单点故障(SPOF, Single Point of Failure)问题而设计的。
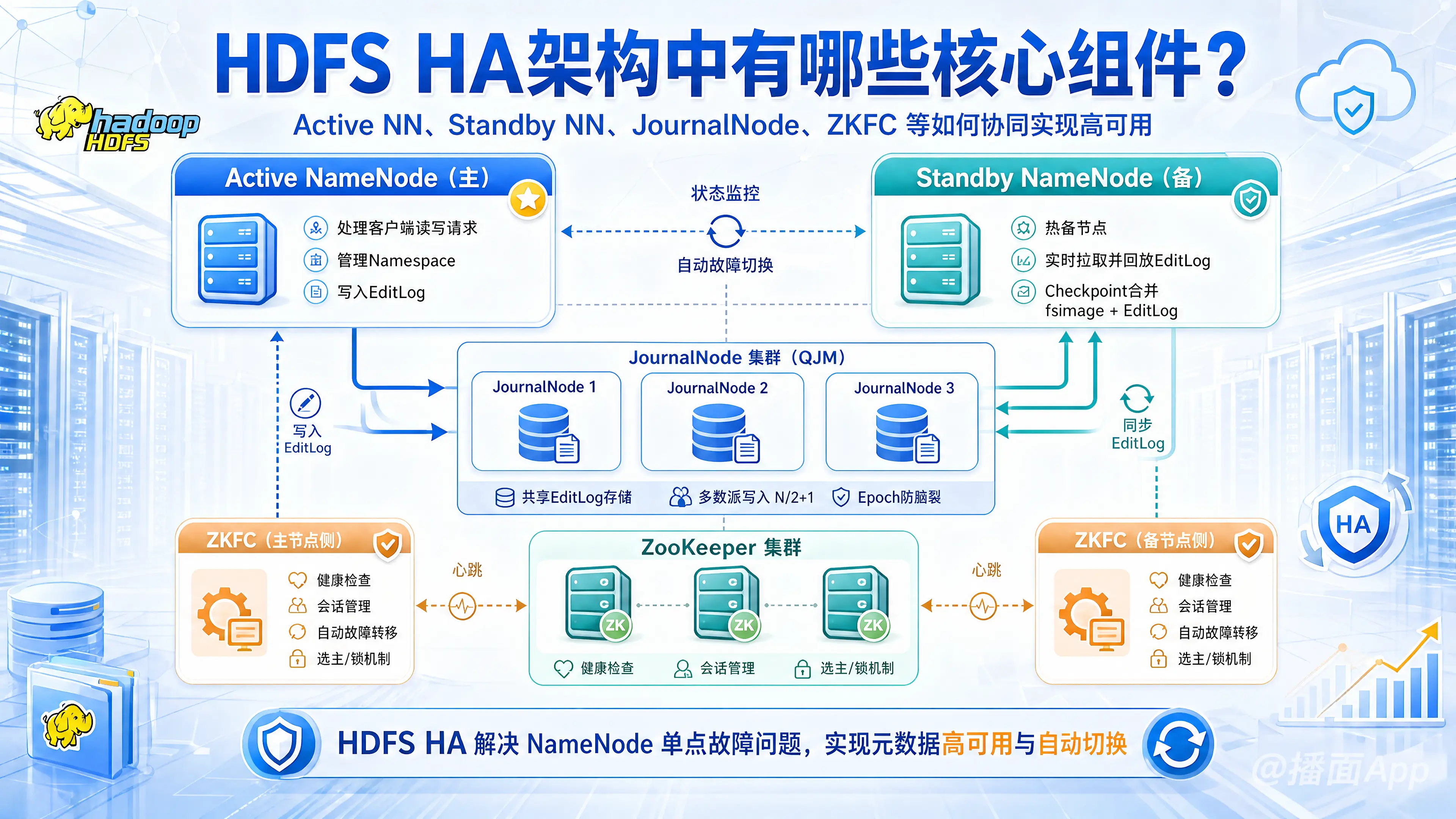
在一个典型的 HDFS HA 集群中,通常会配置两个 NameNode(一个 Active,一个 Standby)。为了保证元数据的一致性以及实现自动故障转移,HA 架构引入了几个至关重要的核心组件。
以下是 HDFS HA 架构中的核心组件及其详细解析:
1. 核心节点:Active NameNode 与 Standby NameNode
在 HA 架构中,NameNode 被分为了两种角色,它们在内存中维护着完全相同的元数据树和块映射信息:
- Active NameNode(活跃 NameNode):
- 职责:负责处理客户端所有的读写请求,管理 HDFS 的命名空间(Namespace),并执行所有对元数据的修改操作。
- 动作:将元数据的修改操作(EditLog)持续写入到共享存储系统(JournalNodes)中。
- Standby NameNode(备用 NameNode):
- 职责:作为 Active NN 的“热备(Hot Standby)”节点。它不处理客户端的写请求。
- 动作:它会持续监听共享存储系统(JournalNodes),一旦发现有新的 EditLog 写入,就会拉取并在自己的内存中回放(Replay)这些操作,从而保证与 Active NN 的元数据状态实时同步。
- 额外作用:在 HA 架构中,Standby NN 替代了原来的 Secondary NameNode 的功能。它会定期将内存中的文件系统镜像(fsimage)与 EditLog 进行合并(Checkpoint),并将合并后的新 fsimage 推送给 Active NN,防止 EditLog 过大。
2. 共享存储组件:JournalNode (JN) 集群
为了让 Active 和 Standby 之间能够实时同步元数据,必须依赖一个高可用的共享存储系统。Hadoop 默认且最常用的是 QJM(Quorum Journal Manager) 方案。
- 职责:负责存储 Active NN 产生的 EditLog,并提供给 Standby NN 读取。
- 工作机制(Quorum 机制):
- JournalNode 通常部署为奇数个(如 3、5、7 个)。
- Active NN 写入 EditLog 时,必须成功写入到大多数()的 JN 节点才算成功。例如 3 个节点,必须成功写入 2 个。
- 防止脑裂(Split-Brain)的底层保障:QJM 引入了 Epoch(纪元/轮次)概念。只有持有最新 Epoch 编号的 NameNode 才能向 JN 写入数据。如果发生网络分区导致两个 NN 都认为自己是 Active,JN 会拒绝旧 Epoch 的写入请求,从而保护元数据不被破坏。
3. 自动故障转移组件:ZKFC (ZooKeeper Failover Controller)
如果没有 ZKFC,HDFS HA 只能进行手动故障转移。ZKFC 是实现自动故障转移(Automatic Failover)的核心大脑。
- 部署方式:ZKFC 是一个独立的守护进程(Daemon)。在每一台运行 NameNode 的机器上,都会运行一个与之对应的 ZKFC 进程。
- 核心职责:
- 健康监控(Health Monitoring):ZKFC 会周期性地向它所在机器的本地 NameNode 发送健康检查命令(Ping)。如果 NN 崩溃、挂起或无响应,ZKFC 就会将其标记为不健康。
- ZooKeeper 会话管理:当本地 NN 健康时,ZKFC 会在 ZooKeeper 中保持一个打开的会话(Session),并在 ZK 中创建一个排他锁(临时节点 ZNode)。哪个 ZKFC 成功创建了这个锁,它对应的 NN 就是 Active 状态。
- 基于 ZooKeeper 的选举(Leader Election):如果 Active NN 挂掉,其对应的 ZKFC 也会断开与 ZK 的连接,临时节点(锁)被删除。此时,Standby NN 的 ZKFC 会立刻感知到,并在 ZK 中尝试获取锁。一旦获取成功,它就会触发本地的 NameNode 切换为 Active 状态。
4. 协调服务:ZooKeeper (ZK) 集群
- 职责:为 ZKFC 提供分布式的协调服务,维护 Active NameNode 的选举锁(ActiveBreadCrumb)。
- 作用:确保在任何时刻,集群中只有一个节点能够持有锁(即保证只有一个 Active NN),是触发自动故障转移的仲裁者。
5. 数据节点:DataNode (DN) 的特殊机制
在非 HA 架构中,DataNode 只向一个 NameNode 汇报。但在 HA 架构中,DataNode 的行为发生了改变:
- 双向汇报:所有的 DataNode 必须同时配置两个 NameNode 的地址。
- 状态同步:DataNode 会向 Active 和 Standby 两个 NameNode 同时发送心跳(Heartbeat)和块状态汇报(Block Report)。
- 原因:元数据不仅包含目录树(由 EditLog 同步),还包含文件块在哪些 DataNode 上的位置信息(Block Map)。位置信息是不持久化到磁盘的。通过让 DN 双向汇报,Standby NN 内存中会时刻保留一份完整的块位置映射表。这样在发生故障转移时,Standby NN 能够瞬间接管服务,不需要等待 DN 重新汇报。
6. 隔离机制:Fencing (防脑裂机制)
为了绝对保证集群中不会同时出现两个 Active NN(即脑裂 Split-Brain现象,会导致数据极其严重的损坏),HDFS 引入了 Fencing 机制。
当 ZKFC 决定让 Standby 升级为 Active 之前,它必须先“干掉”或“隔离”原来的 Active NN。
- QJM 级别的隔离:如前所述,通过 Epoch 机制阻止旧 NN 写日志。
- SSH Fencing:通过 SSH 登录到旧的 Active NN 机器上,强制执行
kill -9杀掉 NameNode 进程。 - Shell 脚本隔离:如果 SSH 失败,可以配置自定义脚本(例如调用智能电源管理接口 IPMI 直接切断旧主节点的电源,即 STONITH - "Shoot The Other Node In The Head")。
总结:HA 工作流程一句话串联
客户端向 Active NN 写数据;Active NN 将变更日志写入 JournalNode 集群的多数派;Standby NN 从 JN 拉取日志回放保持状态同步;DataNode 向两个 NN 均发送心跳和块报告;ZKFC 实时监控本地 NN 健康并借助 ZooKeeper 维持锁;一旦 Active NN 宕机,ZKFC 借助 Fencing 杀死旧主节点,并通过 ZK 选举将 Standby NN 提升为新的 Active NN,实现无缝切换。