集群中的DataNode节点可以动态扩容和缩容具体需要如何操作?
在Hadoop集群中,HDFS(Hadoop Distributed File System)原生支持动态扩容(添加节点)和动态缩容(退役节点),整个过程不需要重启集群,不会影响线上业务。
以下是具体的完整操作步骤:
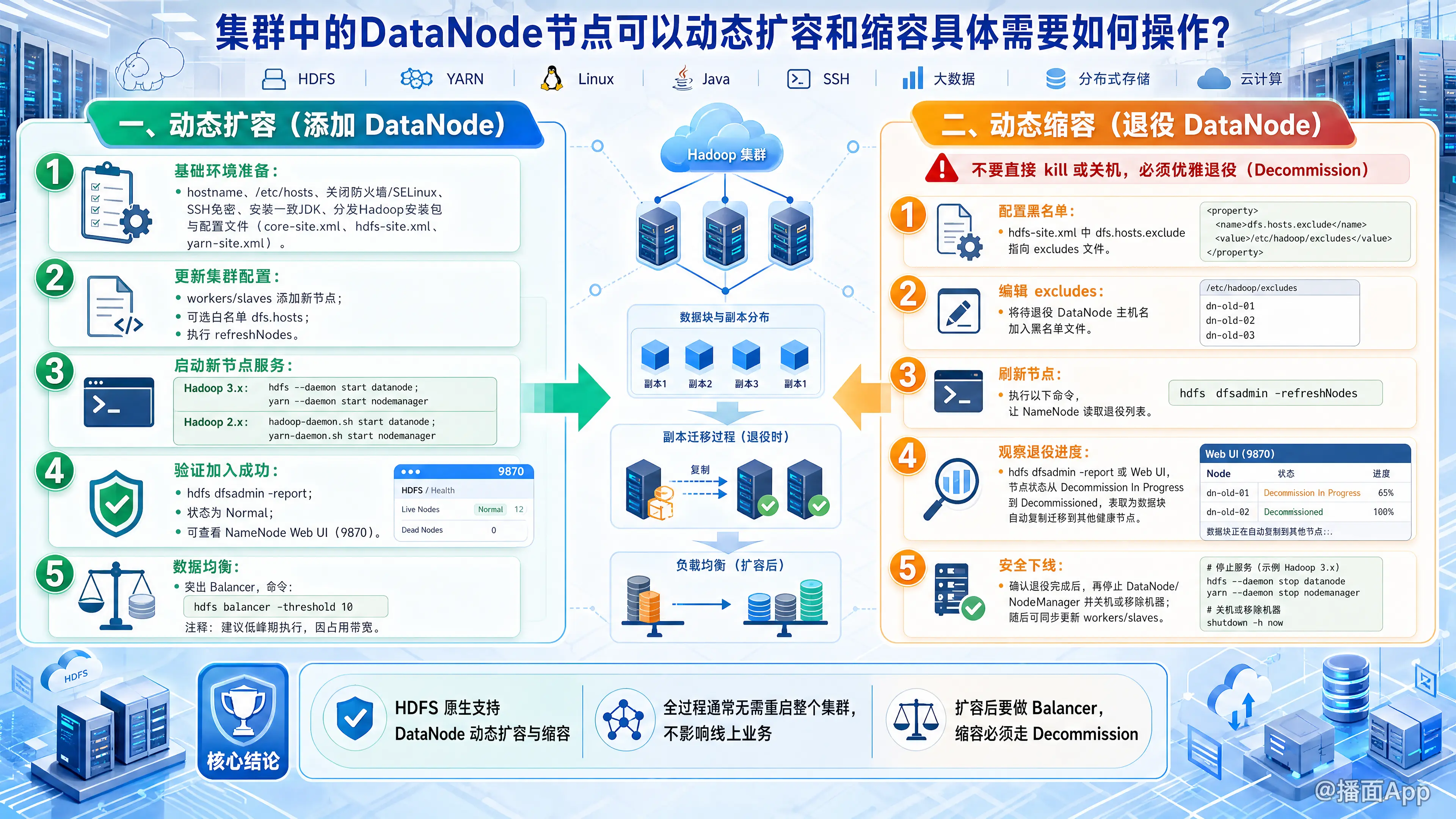
一、 动态扩容(添加 DataNode)
扩容的核心思想是:准备好新节点的环境,在新节点上启动 DataNode 服务,并让 NameNode 识别它,最后进行数据均衡。
1. 基础环境准备(在新节点上操作)
- 系统设置:配置主机名(hostname)、修改
/etc/hosts(确保与集群其他节点互相解析)、关闭防火墙/SELinux。 - SSH免密登录:配置 NameNode 到新节点的 SSH 免密登录。
- Java环境:安装与集群版本一致的 JDK。
- Hadoop环境:将现有集群的 Hadoop 安装包及配置文件(
core-site.xml,hdfs-site.xml,yarn-site.xml等)分发到新节点的相同路径下。
2. 更新集群配置(在 NameNode 上操作)
- 编辑
workers文件(Hadoop 2.x 中叫slaves),添加新节点的主机名。(注:这一步主要是为了后续使用群起脚本start-dfs.sh时能包含该节点,对当前动态扩容非强制,但建议保持同步)。 - 白名单配置(可选但推荐):如果你在
hdfs-site.xml中配置了dfs.hosts(白名单),需要将新节点加入该白名单文件中,然后执行hdfs dfsadmin -refreshNodes。
3. 启动新节点服务(在新节点上操作)
在新节点上手动启动 DataNode(如果用到了 YARN,一并启动 NodeManager):
# Hadoop 3.x 命令
hdfs --daemon start datanode
yarn --daemon start nodemanager
# Hadoop 2.x 命令
hadoop-daemon.sh start datanode
yarn-daemon.sh start nodemanager4. 验证是否加入成功
在 NameNode 上执行以下命令,或者查看 HDFS Web UI(默认 http://namenode:9870):
hdfs dfsadmin -report如果能看到新节点且状态为 Normal,说明扩容成功。
5. 集群数据均衡(非常重要)
新节点刚加入时是空的,为了充分利用空间并提高并行读写性能,需要进行数据负载均衡。在任意节点执行:
# 启动 Balancer,-threshold 10 表示各节点磁盘使用率偏差不超过 10%
hdfs balancer -threshold 10(注意:Balancer 过程较慢且消耗网络带宽,建议在业务低峰期运行)。
二、 动态缩容(退役 DataNode)
警告:千万不要直接 kill 掉 DataNode 进程或直接关机! 这样会导致数据块丢失(如果副本数不足)或引发大量的块复制风暴。必须使用优雅退役(Decommission)机制。
退役的核心思想是:告诉 NameNode 准备下线某节点,NameNode 会自动将该节点上的数据块复制到其他健康节点上,等数据转移完毕后,再安全关闭该节点。
1. 配置黑名单(在 NameNode 上操作)
确保你的 hdfs-site.xml 中配置了黑名单属性(如果没有,需要添加并重启 NameNode 才能生效,通常建集群时应提前配好):
<property>
<name>dfs.hosts.exclude</name>
<value>/usr/local/hadoop/etc/hadoop/excludes</value>
</property>2. 添加退役节点
编辑上述配置的 excludes 文件,将需要下线的 DataNode 主机名或 IP 添加进去(每行一个)。
3. 刷新集群状态(触发退役)
在 NameNode 上执行刷新命令,使得配置生效:
# 刷新 HDFS 节点
hdfs dfsadmin -refreshNodes
# 如果有 YARN,同样需要刷新 ResourceManager (需配置 YARN 黑名单 yarn.resourcemanager.nodes.exclude-path)
yarn rmadmin -refreshNodes4. 等待退役完成(监控状态)
执行刷新后,该节点的状态会变为 Decommissioning in Progress(退役中)。此时 NameNode 正在将该节点的数据迁移到其他节点。
你可以通过以下方式监控:
- Web UI:进入 HDFS 页面,查看 Datanodes 标签页,状态显示为
Decommissioning。 - 命令行:bash
hdfs dfsadmin -report
必须等待! 直到该节点的状态彻底变为 Decommissioned(已退役)。这个过程的长短取决于该节点上的数据量和集群网络带宽,可能需要几个小时。
5. 停止节点服务(在退役节点上操作)
确认状态变为 Decommissioned 后,说明数据已经全部安全转移。此时可以安全地停止该节点的进程:
# Hadoop 3.x
hdfs --daemon stop datanode
yarn --daemon stop nodemanager6. 清理配置文件(在 NameNode 上操作)
- 从
excludes黑名单文件中删除该节点。 - 从
workers/slaves文件中删除该节点。 - 再次执行
hdfs dfsadmin -refreshNodes使清理生效。
三、 动态扩缩容的注意事项
- 缩容前的容量评估:在退役节点前,必须计算 剩余集群的总可用空间 是否大于 当前集群已使用的总空间。如果剩余空间不足以容纳被退役节点的数据,退役过程会一直卡在
Decommissioning状态无法完成。 - 控制均衡/退役带宽:数据迁移会占用大量网络带宽。可以通过命令动态调整允许使用的带宽(默认通常很低,如 10MB/s,会导致过程极慢):bash
# 设置带宽为 50MB/s (单位为 bytes) hdfs dfsadmin -setBalancerBandwidth 52428800 - 机架感知(Rack Awareness):如果你的集群配置了机架感知,在添加新节点时,记得在拓扑脚本/配置中为新节点分配正确的机架(Rack)信息。
- 白名单与黑名单的关系:
- 如果一个节点同时存在于白名单(
dfs.hosts)和黑名单(excludes)中,它允许连接集群,但会直接进入退役状态。 - 推荐生产环境同时启用白名单和黑名单,严格控制节点接入。
- 如果一个节点同时存在于白名单(