在HDFS写数据的过程中,如果其中一台DataNode宕机了,系统会怎么处理?
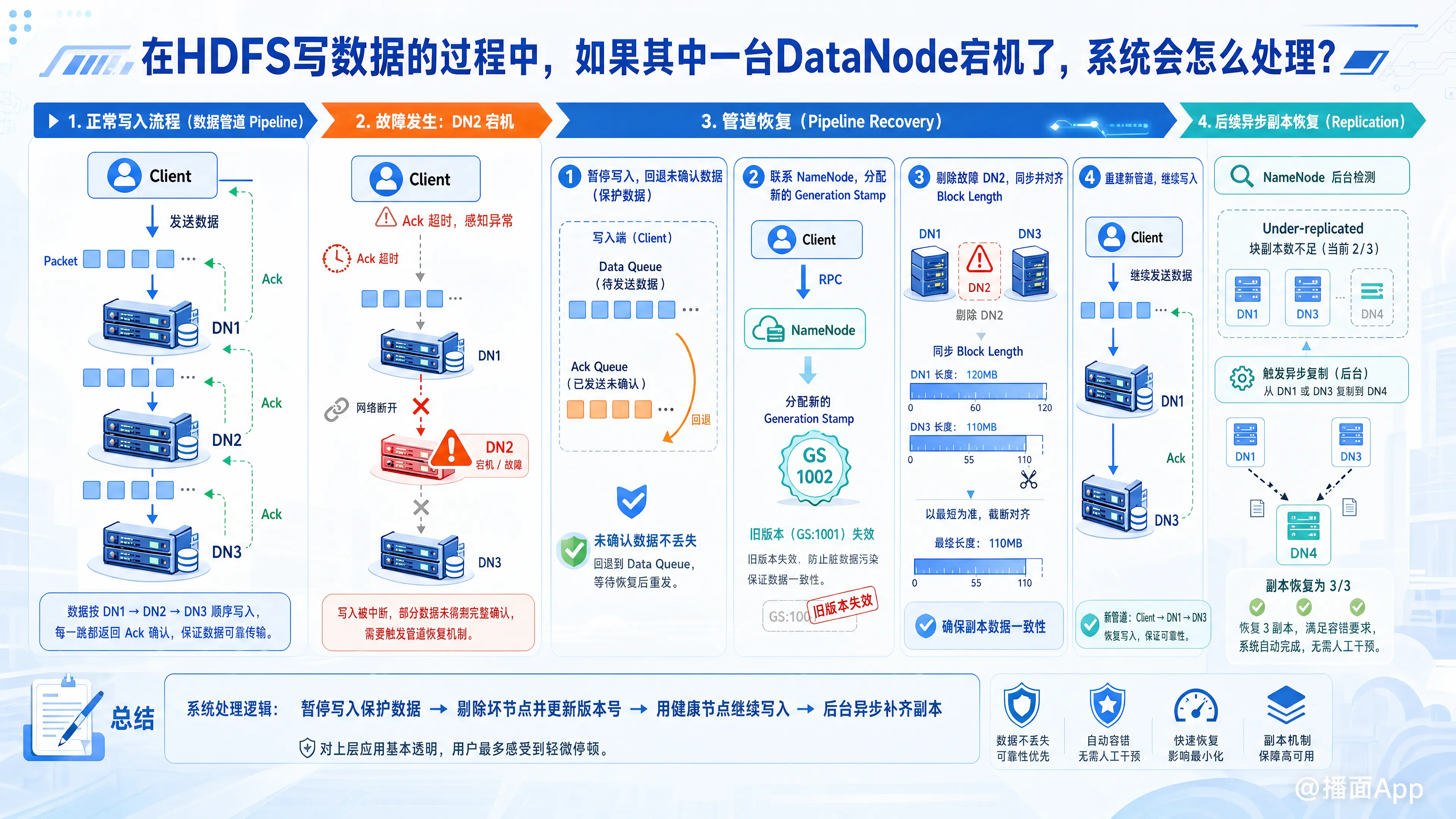
在HDFS写数据的过程中,如果其中一台DataNode(简称DN)宕机了,写操作并不会失败。HDFS具有高度的容错性,客户端和NameNode会通过管道恢复(Pipeline Recovery)机制自动处理这个异常,确保数据不丢失且写入过程能够继续。
以下是系统处理该情况的详细、逐步的过程:
1. 故障感知
HDFS写数据是通过数据管道(Pipeline)进行的。假设副本数为3,数据流向通常是:Client -> DN1 -> DN2 -> DN3。数据被切分成一个个Packet(数据包)发送,同时下游节点会向上游返回Ack(确认包)。
- 如果某台DN(例如DN2)宕机,网络连接会断开,Ack确认包无法按时返回。
- 客户端(Client)在等待超时或者捕获到网络异常(Exception)后,就会感知到管道出了问题。
2. 管道恢复(Pipeline Recovery)核心步骤
客户端一旦发现异常,会立即暂停数据的发送,并执行以下恢复操作:
第一步:停止写入,回退未确认的数据包
客户端关闭当前的管道。将处于Ack Queue(已发送但尚未收到确认的数据包)中的所有Packet重新放回到Data Queue(待发送数据队列)的最前端。这一步确保了即使有节点宕机,数据也不会丢失。第二步:申请新的数据块版本号(Generation Stamp)
客户端会通过RPC通信联系 NameNode,告知当前发生的异常。NameNode会为当前正在写入的Block分配一个新的版本号(Generation Stamp)。
(注:这样做的目的是,如果那个宕机的DN后来又恢复启动了,它上面包含的只是一部分不完整的数据。NameNode通过比对版本号,发现它的是旧版本,就会直接将其标记为失效并删除,防止脏数据污染。)第三步:剔除宕机节点,同步数据长度
客户端将宕机的节点(DN2)从管道中剔除。然后,剩下的正常节点(DN1和DN3)会根据新的版本号进行一次通信,确认当前大家已经成功接收到的数据块长度(Block Length)。如果剩余节点中数据长度不一致,会以最短的那个为准进行截断对齐(保证剩下的节点数据完全一致)。第四步:重建管道,恢复写入
客户端使用剩下的正常节点(DN1和DN3)建立新的数据管道(Client -> DN1 -> DN3)。客户端继续把Data Queue中的数据发送给剩下的DataNode,直到整个文件的数据写完。
3. 后续的异步恢复(Replication)
此时,虽然客户端成功把数据写完了,但这块数据只有2个副本(DN1和DN3),低于系统默认要求的3个副本。
- 当客户端写完数据并调用
close()关闭文件时,会向NameNode汇报文件的写入结果。 - NameNode 在接收到汇报后,会发现该数据块处于欠副本状态(Under-replicated)。
- NameNode 会在后台将其加入到复制队列中,异步地指示 DN1 或 DN3 将该数据块复制到另一台健康的 DataNode(例如 DN4)上。
- 最终,系统中的副本数恢复到3个,满足容错要求。
总结
简单来说,如果一台DataNode在写数据时宕机,系统会:
- 暂停写入,保护未确认的数据。
- 剔除坏节点,更新数据块版本号。
- 用剩下的好节点继续写完。
- 写完之后,NameNode会在后台偷偷找一台新机器把缺少的副本补齐。
对用户或上层应用而言,这个过程是完全透明的,除了可能感觉到写入稍微停顿了一下,不会收到任何错误报错。