描述一下HDFS写数据的完整流程
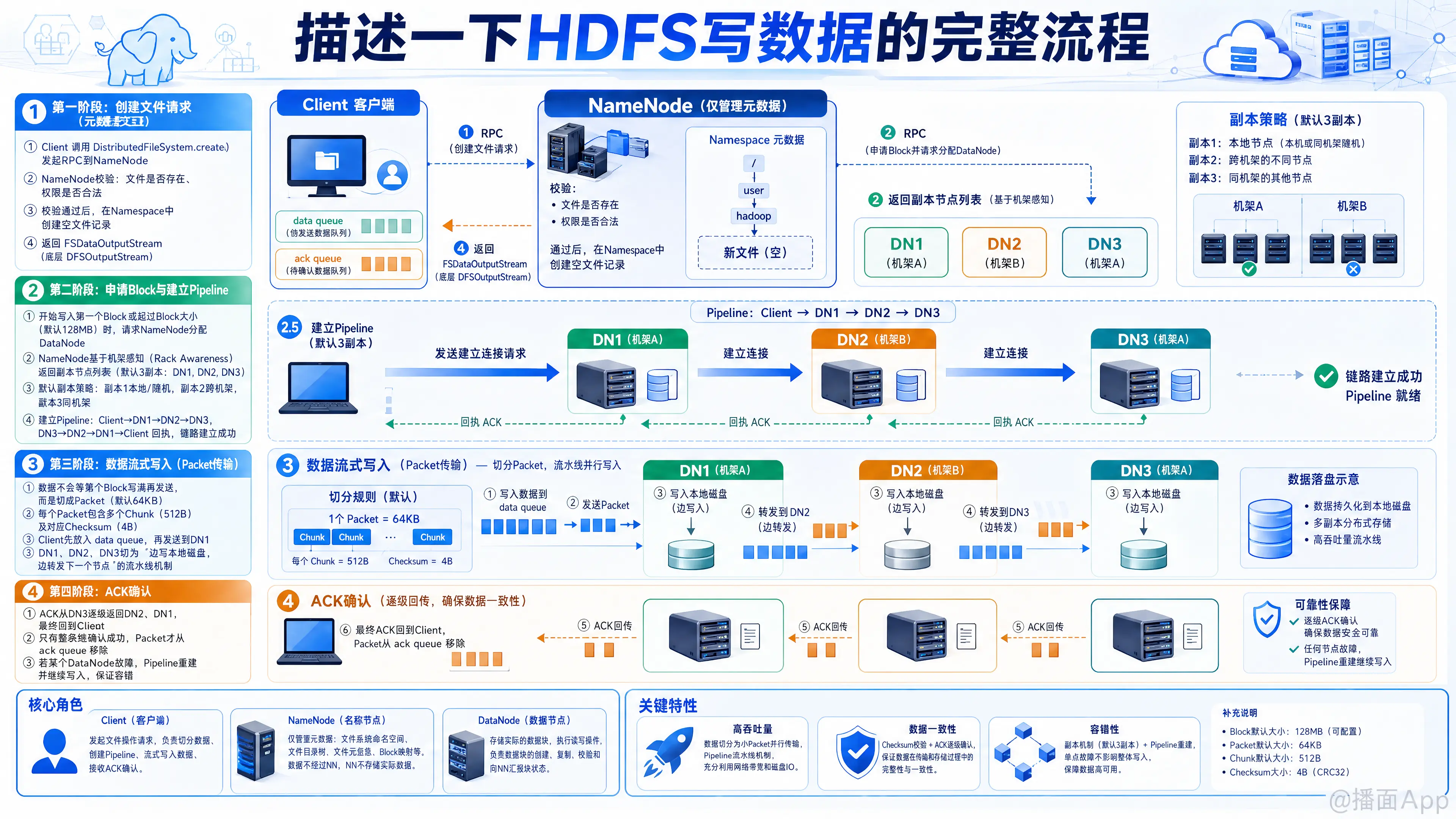
HDFS(Hadoop Distributed File System)的写数据流程是Hadoop架构中最核心、也是面试中最常被问到的机制之一。整个过程设计极其精妙,兼顾了高吞吐量、数据一致性和容错性。
以下是HDFS写数据的完整、详细步骤:
核心角色
- Client(客户端): 发起写请求的实体。
- NameNode(NN): 负责管理HDFS的元数据(目录树、文件与Block的映射、Block与DataNode的映射)。注意:数据本身绝对不经过NameNode。
- DataNode(DN): 负责实际存储数据的节点。
📝 完整写数据流程(Step-by-Step)
第一阶段:创建文件请求(元数据交互)
- 发起请求: 客户端通过调用
DistributedFileSystem.create()方法,向 NameNode 发起创建文件的 RPC(远程过程调用)请求。 - NameNode 校验:
- NameNode 检查目标文件是否已经存在。
- 检查客户端是否有权限在目标路径创建文件。
- 创建元数据: 如果校验通过,NameNode 会在内存中的命名空间(Namespace)里创建一条新的空文件记录。此时,还没有分配任何数据块(Block)。
- 返回输出流: NameNode 向客户端返回一个
FSDataOutputStream对象(底层是DFSOutputStream),客户端将使用它来写数据。
第二阶段:申请Block与建立管线(Pipeline)
- 切分与申请Block: 当客户端开始写入数据时,如果数据超过一个 Block 的大小(默认 128MB),或者开始写第一个 Block 时,客户端会向 NameNode 请求分配 DataNode 来存储该 Block。
- 返回DataNode列表(机架感知): NameNode 根据副本放置策略(Rack Awareness),返回一个包含多个 DataNode 地址的列表(默认是3个副本,比如 DN1, DN2, DN3)。
- 默认副本放置策略:
- 第一个副本:如果客户端在集群内,放在客户端所在的节点;如果在集群外,随机挑选一个负载不高的节点。
- 第二个副本:放在与第一个副本不同机架的随机节点上(保证机架故障时的容错)。
- 第三个副本:放在与第二个副本相同机架的另一个随机节点上(减少跨机架网络传输开销)。
- 默认副本放置策略:
- 建立数据管线(Pipeline):
- 客户端通过 Socket 连接到 DN1。
- DN1 连接到 DN2。
- DN2 连接到 DN3。
- 连接建立完毕后,DN3 响应 DN2,DN2 响应 DN1,DN1 响应客户端,Pipeline 建立成功。
第三阶段:数据流式写入(Packet传输)
- 数据切分(Packet): 客户端并不是等 128MB 的 Block 全部生成好才发送,而是将数据切分成一个个的 Packet(默认 64KB)。每个 Packet 又包含多个 Chunk(512 Byte) 和对应的 Checksum(校验和,4 Byte)。
- 发送到数据队列(Data Queue): 客户端将 Packet 放入一个内部的
data queue(数据队列)中。 - 管线传输(流式写入):
- 客户端将 Packet 发送给 DN1。
- DN1 收到 Packet 后,一边将其写入本地磁盘,一边将该 Packet 转发给 DN2。
- DN2 同样一边写本地磁盘,一边转发给 DN3。
- DN3 收到后写入本地磁盘。
(这种流水线机制极大地提高了写入效率,不需要等前一个节点完全写完才发给下一个节点)。
第四阶段:接收确认(ACK)
- ACK确认机制: 为了保证数据写入成功,客户端内部还维护了一个
ack queue(确认队列)。Packet 发送出去后,会从 data queue 移入 ack queue。 - 逆向返回ACK:
- DN3 落盘成功后,向 DN2 发送 ACK 确认。
- DN2 落盘成功并收到 DN3 的 ACK 后,向 DN1 发送 ACK。
- DN1 落盘成功并收到 DN2 的 ACK 后,向客户端发送 ACK。
- 清理队列: 客户端收到确认后,将该 Packet 从
ack queue中删除。
第五阶段:循环与文件关闭
- 下一个Block: 当第一个 Block(128MB)写完后,客户端会再次向 NameNode 申请新的 DataNode 列表,建立新的 Pipeline,重复上述 7~13 步,直到整个文件的数据全部写完。
- 关闭流: 数据全部写完后,客户端调用
close()方法关闭输出流。此时客户端会等待所有未确认的 Packet 收到 ACK。 - 通知NameNode完成: 客户端向 NameNode 发送 RPC 请求,告知文件写入完成。NameNode 将该文件标记为正常状态(Available),此时文件才对其他读取操作完全可见。
🛡️ 容错机制(异常处理):如果在写入过程中 DataNode 宕机了怎么办?
这是面试官非常喜欢追问的问题。如果在 Pipeline 传输过程中(假设写 DN2 时),DN2 突然宕机,HDFS 会做如下处理:
- Pipeline 停止: 管线被立即关闭。
- 数据回滚: 客户端
ack queue中未收到确认的 Packet 会被重新放回data queue的头部,确保数据不丢失。 - 分配新版本号(Generation Stamp): 正常存活的 DataNode(DN1, DN3)会向 NameNode 报告,NameNode 会为当前的 Block 分配一个新的版本号(比如从 v1 变成 v2)。这样当宕机的 DN2 恢复后,它上面的旧 Block (v1) 会被 NameNode 发现并删除。
- 剔除故障节点: 故障的 DN2 会被从 Pipeline 中剔除。
- 恢复写入: 剩下的 DN1 和 DN3 重新建立 Pipeline。客户端继续向这剩下的节点写入剩下的数据。
- 异步补全副本: 当文件关闭后,NameNode 定期检查发现该 Block 只有 2 个副本(低于配置的 3 个),会在后台异步地安排其他 DataNode 复制该 Block,使其恢复到 3 个副本。
💡 总结核心特点
- 元数据与数据分离: NameNode 只管目录和 Block 映射,数据直接在 Client 和 DataNode 之间传输。
- 流水线(Pipeline)复制: 最大化网络带宽利用率,降低延迟。
- Packet 和 Chunk 机制: 细粒度的数据传输和校验(CRC32),保证数据完整性。
- 机架感知: 在可靠性(跨机架)和性能(同机架)之间取得完美平衡。
右滑查看面试常问