PostgreSQL 是如何实现 MVCC 的?
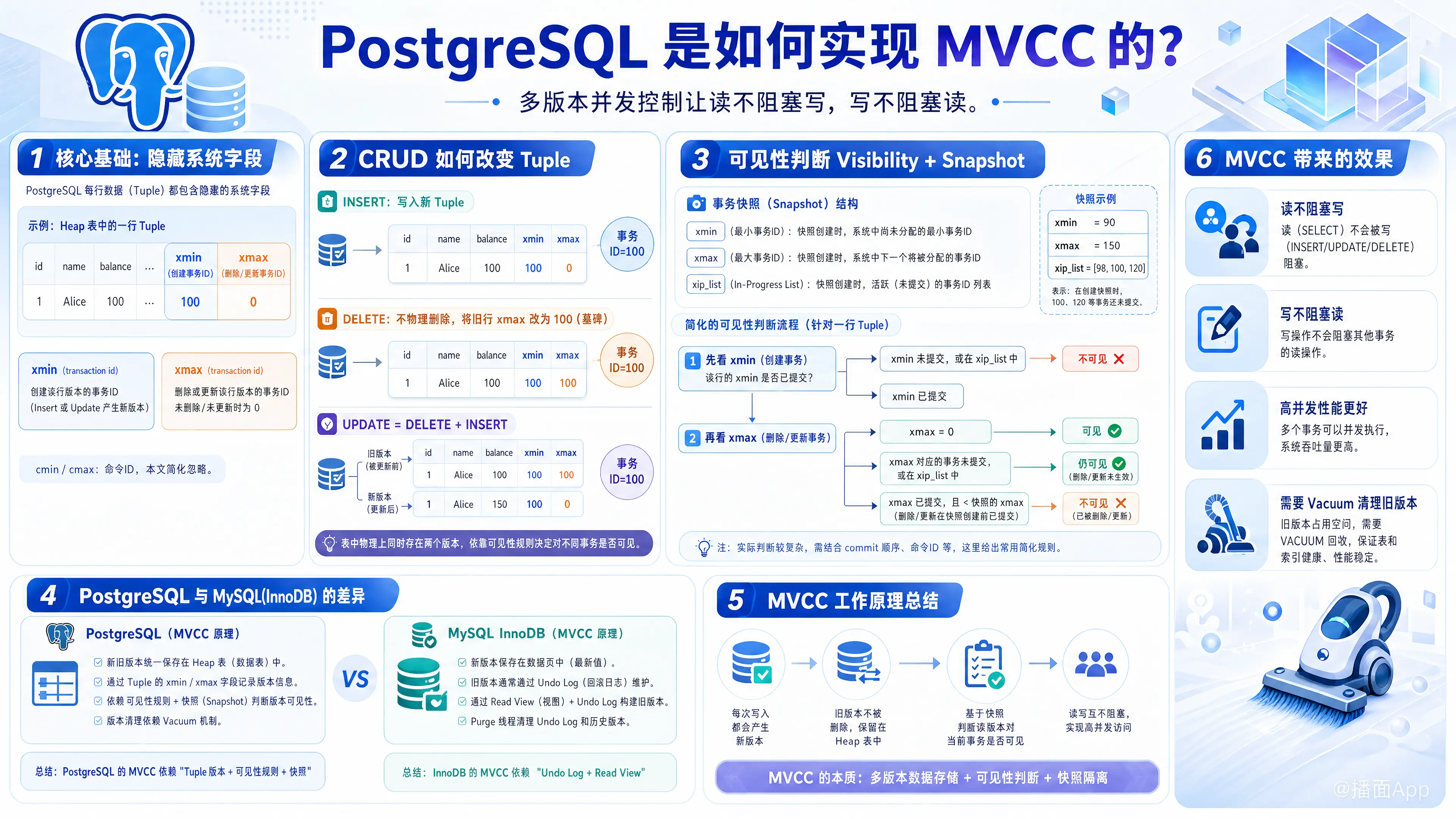
PostgreSQL 的 MVCC(多版本并发控制,Multi-Version Concurrency Control) 是其核心架构之一。它的主要目的是在保证数据库隔离性的同时,实现“读不阻塞写,写不阻塞读”,从而大幅提升高并发环境下的性能。
与 MySQL (InnoDB) 将旧版本数据存储在 Undo Log 中不同,PostgreSQL 将新旧版本的数据统一存放在数据表文件(Heap 表)中。
以下是 PostgreSQL 实现 MVCC 的核心机制和原理剖析:
1. 核心基础:隐藏的系统字段(System Columns)
PostgreSQL 表中的每一行数据(在 PG 中称为 Tuple 或元组)除了包含用户定义的数据外,还包含几个隐藏的系统字段。实现 MVCC 最关键的是以下两个:
xmin:创建(Insert)该行版本的事务 ID(Transaction ID,简称 XID)。xmax:删除或更新(Delete/Update)该行版本的事务 ID。如果该行尚未被删除或更新,此值为 0。
(注:还有 cmin 和 cmax 用于标识同一个事务内不同 SQL 语句的顺序,这里为了简化先忽略它们。)
2. 数据操作(CRUD)是如何改变 Tuple 的?
在 PostgreSQL 中,事务都有一个唯一且递增的 XID。假设当前开启了一个事务,分配的 XID = 100。
A. 插入 (INSERT)
事务 100 插入一条新记录:
- 数据库会在表中写入一条新的 Tuple。
xmin = 100(由事务 100 创建)。xmax = 0(目前存活,未被删除)。
B. 删除 (DELETE)
事务 100 删除一条已存在的记录(假设该记录原先的 xmin = 50, xmax = 0):
- PostgreSQL 不会立即在磁盘上物理删除该行。
- 而是将该行的
xmax修改为 100。这相当于给这行数据打上了一个“被事务 100 删除”的标记(墓碑标记)。
C. 更新 (UPDATE)
这是 PostgreSQL MVCC 最具特色的地方:Update = Delete + Insert。
事务 100 更新一条记录(假设原记录 xmin = 50, xmax = 0):
- 第一步(Delete):将旧 Tuple 的
xmax改为 100(标记为被删除)。 - 第二步(Insert):在表中插入一条拥有新值的新 Tuple,其
xmin = 100,xmax = 0。 - 此时,表中物理存在这条数据的两个版本。
3. 可见性判断(Visibility Rules)与快照(Snapshot)
当一个事务(假设 XID = 200)去读取数据时,面对表中无数个具有不同 xmin 和 xmax 的 Tuple,它怎么知道该看哪一个版本?
事务快照 (Transaction Snapshot)
在语句开始或事务开始时(取决于隔离级别),PG 会生成一个快照。快照主要包含:
xmin:当前所有活跃事务中最小的 XID。xmax:下一个将要分配的 XID。xip_list:当前所有活跃(未提交)事务的 XID 列表。
核心判断逻辑 (简化的可见性规则):
对于表中的任意一个 Tuple,事务 200 按照以下规则判断其是否可见:
- 看
xmin(它是怎么来的?)- 如果
xmin对应的事务尚未提交,或者是快照中的活跃事务(在xip_list中):不可见(别人还没提交的数据不能看,除非是当前事务自己创建的)。 - 如果
xmin对应的事务已经提交:进入下一步。
- 如果
- 看
xmax(它被删了吗?)- 如果
xmax = 0:说明没被删除,可见。 - 如果
xmax对应的事务尚未提交,或在活跃列表中:说明别人正在尝试删除它但没提交,对当前事务可见。 - 如果
xmax对应的事务已经提交,且在当前快照生成之前:说明数据确确实实被历史事务删除了,不可见。
- 如果
PostgreSQL 内部维护了一个 pg_xact (以前叫 pg_clog) 结构,用来记录所有事务的状态(运行中、已提交、已回滚),可见性判断会查阅这个状态。
4. 垃圾回收机制:VACUUM
由于 UPDATE 和 DELETE 并不直接物理删除数据,只是修改 xmax 标记,这会导致表文件中充斥着大量对任何活跃事务都“不可见”的旧版本数据,称为 Dead Tuples(死元组)。
如果不清理,表的文件体积会不断膨胀(表膨胀,Table Bloat)。因此,PostgreSQL 引入了 VACUUM(真空清理) 机制:
- 普通 VACUUM:扫描表,找到所有的死元组,将其占用的空间标记为“可用(Free Space)”。新的 INSERT 或 UPDATE 生成的新元组可以复用这些空间。但它不会把文件变小还给操作系统。
- VACUUM FULL:重写整个表,把活着的数据紧凑地写到一个新文件中,释放磁盘空间。但该操作需要排他锁(Access Exclusive Lock),会阻塞业务。
- AutoVacuum:PG 后台运行的守护进程,会在死元组达到一定比例时自动触发普通 VACUUM,这是日常运维的关键。
5. PostgreSQL MVCC 的重要优化
为了弥补上述架构带来的一些性能损耗,PG 做了大量优化:
A. HOT (Heap-Only Tuples) 优化
如果一张表有索引,UPDATE 操作不仅要插入新 Tuple,还要在所有索引树中插入新的索引项指向新 Tuple(这叫索引膨胀)。
HOT 机制:如果 UPDATE 没有修改任何带有索引的字段,且当前数据页还有剩余空间,PG 就不会在索引中创建新条目。旧 Tuple 会包含一个隐藏指针指向新 Tuple。索引扫描时,先找到旧 Tuple,顺着指针就能找到新 Tuple。这大幅降低了 UPDATE 的开销和表膨胀。
B. 可见性映射表 (Visibility Map, VM)
为了加速 VACUUM 和实现 Index-Only Scan(仅索引扫描),PG 为每个表维护了一个 VM 文件。VM 记录了数据页(Page)上的所有元组是否对所有事务都可见。
- 如果一个页全是可见数据,VACUUM 就会直接跳过这个页。
- 如果查询只需要索引里的字段,且 VM 显示该数据页完全可见,PG 就不需要回表(Heap 表)去检查
xmin/xmax了,直接返回索引里的数据。
6. 特殊痛点:事务 ID 回卷 (XID Wraparound)
PostgreSQL 的事务 ID (XID) 是一个 32 位的整数,最大约 42 亿。当 XID 用尽时,它会从头开始循环。
这就引发了一个问题:如果新分配的 XID 循环到了很小的值,根据前面的比较规则,系统会误认为过去几十亿年前插入的老数据(由于其 XID 现在看起来比当前的更大)变成了“来自未来的未提交数据”,从而导致所有老数据突然变得不可见(数据丢失错觉)。
解决办法:Freeze (冻结)
VACUUM 还有一个极其重要的任务:它会扫描非常老的数据,并将其系统字段标记为一个特殊的标志(Frozen XID,通常是 2)。任何事务看到带有 Frozen 标记的 Tuple,都会认为它是“绝对古老且对所有人可见的”。这就防止了事务 ID 回卷灾难。
总结
PostgreSQL 实现 MVCC 的核心特点可以概括为:
- 追加写入式设计:新旧版本都在同一个表文件中(通过
xmin/xmax区分)。 - 快照隔离:基于事务 ID 列表动态判断每行数据的可见性。
- 依赖 VACUUM:由于旧数据不立即清理,必须依赖 AutoVacuum 回收空间和冻结旧事务 ID。
与 MySQL 的回滚段(Undo Log)机制相比,PG 的方式在事务回滚时极快(只需改变事务状态即可,不需要反向执行操作),但代价是更容易发生表膨胀,且对 VACUUM 的依赖度极高。